
Pandas 基础 (13) - Crosstab 交叉列表取值
2471 / 0 / 创建于 5年前
 Rachel 的个人博客
Rachel 的个人博客
这小节的题目看起来还挺晦涩的, crosstab 是 pandas 的一个函数, 作用还蛮强大的, 一起来看一下吧~~~
首先还是先引入一个例子文件:
import pandas as pd
df = pd.read_excel('/Users/rachel/Sites/pandas/py/pandas/13_crosstab/survey.xls')
df输出:
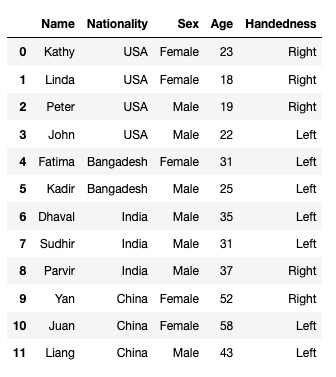
好, 下面看一下 crosstab 的功力:
pd.crosstab(df.Nationality, df.Handedness)输出:
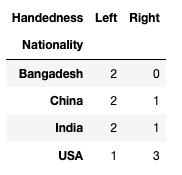
crosstab 第一个参数是列, 第二个参数是行. 还可以添加第三个参数:
pd.crosstab(df.Sex, df.Handedness, margins = True)输出:

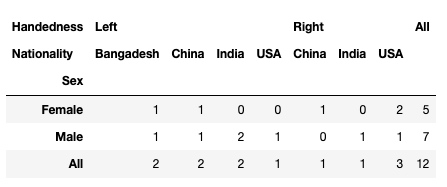
同时, 行和列都可以是复合的:
pd.crosstab(df.Sex, [df.Handedness, df.Nationality], margins = True)输出:
pd.crosstab([df.Nationality, df.Sex], df.Handedness, margins = True)输出:
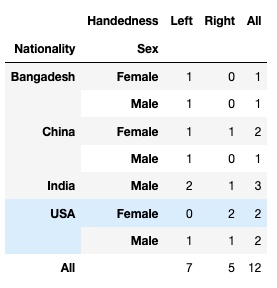
ok, 上面介绍了 crosstab() 函数最基本的功能, 其实它还可以通过很多参数的配置实现不同的功能. 这里分享一个小技巧, 把光标点到 crosstab 单词上, 按下 shift + tab 键, 就可以弹出对这个函数的详情(如果没反应,就把那个单元格的代码运行一下, 再试) 主要是参数的使用说明, 发现真的还有好多参数啊, 下面再选两个讲一下:
求百分比:
pd.crosstab(df.Sex, df.Handedness, normalize='index')输出:

求指定列的平均值:
import numpy as np
pd.crosstab(df.Sex, df.Handedness, values=df.Age, aggfunc=np.average)输出:

最后一个参数看起来有点多, 有点复杂, 那也是因为我们刚开始接触 crosstab 函数, 所以可以结合上面介绍的方法, 打开函数说明, 对照着里面的参数用法, 多看几遍 就懂了.
本作品采用《CC 协议》,转载必须注明作者和本文链接



 关于 LearnKu
关于 LearnKu



