
Python 开发简单爬虫 (学习笔记)
0 / 1 / 创建于 5年前
 wsAdmin 的个人博客
wsAdmin 的个人博客
爬虫:一段自动抓取互联网信息的程序;抓取互联网相关数据为自己所用
简单的爬虫架构
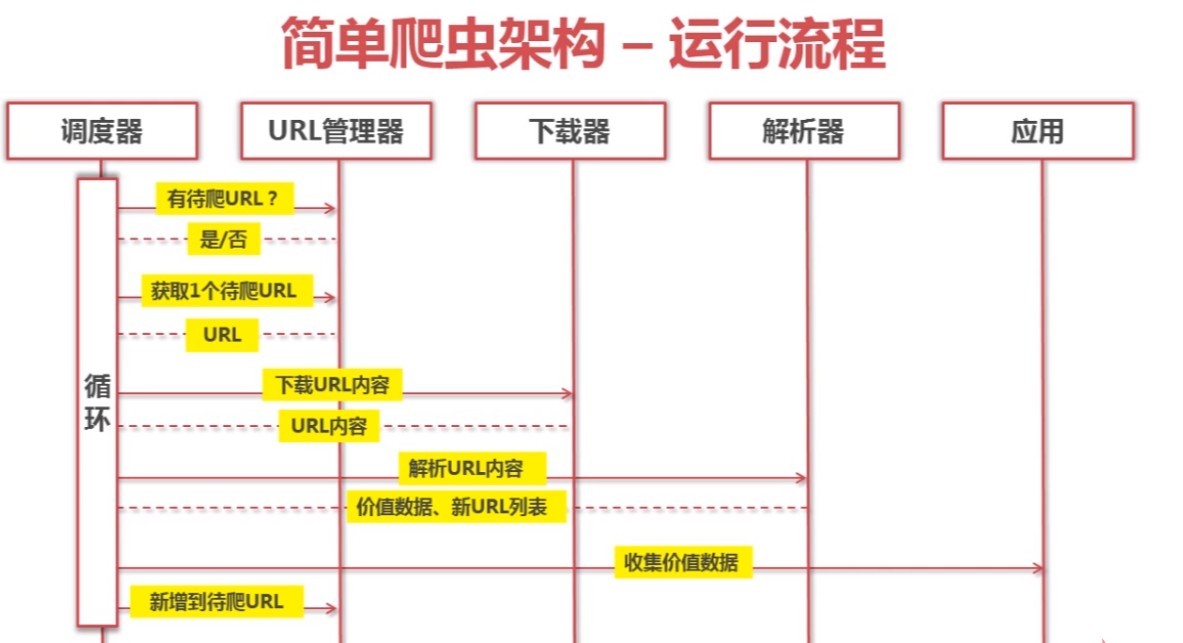
URL管理器
1.管理待抓取的url集合与已抓取的url集合
2.作用:防止重复抓取与循环抓取url指向资源
3.实现方式:内存管理;关系型数据库(mysql)管理;非关系型数据库管理(Redis)网页下载器
1.将互联网上的URL对应的网页下载至本地的工具
2.作用:通过url在互联网上获取指定的网页,将其下载至本地并保存成文件,或者以字符串的形式存储在内存中
3.种类:
①urllib2(Python官方提供的基础模块);
②requests(第三方插件,提供更为强大的功能)
4. urllib2抓取网页的三种方法url = "https://www.baidu.com";
print "第一方法"
res_1 = urllib2.urlopen(url); #直接请求url
print res_1.getcode(); #打印请求结果状态码
print len(res_1.read()) #打印获取的网页长度
print "第二种方法"
request = urllib2.Request(url) #创造请求
request.add_header('user-agent',"Mozilla/5.0") #伪造浏览器请求头并添加
res_2 = urllib2.urlopen(request) #发起请求
print res_2.getcode() #获取请求结果状态码
print len(res_2.read()) #打印获取的网页长度
print "第三种方法"
cookie_content = cookielib.CookieJar() #创建cookie容器
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookie_content)) #以容器作为参数创建opener的参数
urllib2.install_opener(opener) #给urllib2安装opener,这样urllib2就拥有了处理Cookie的增强能力
res_3 = urllib2.urlopen(url)
print res_3.getcode() #获取请求结果状态码
print res_3.read() #打印获取的网页内容网页解析器
1.从网页中提取有价值数据的工具
2.解析器种类:
①正则表达式;
②html.parser(Python自带);
③BeautifulSoup(第三方插件);
④lxml(第三方解析器)BeautifulSoup
1.安装:pip install beautifulsoup4
2.实例:#获取要抓取的网页内容
imooc = urllib2.Request("https://www.imooc.com/search/?words=python") #创造请求
imooc.add_header('user-agent',"Mozilla/5.0") #伪造浏览器请求头并添加
res_4 = urllib2.urlopen(imooc) #发起请求
print res_4.getcode() #获取请求结果状态码
string_4 = res_4.read() #打印获取的网页长度
#创建BeautifulSoup 对象,同时将网页字符串转为DOM树形式;参数1:获取的网页字符串;参数2:指定解析器;参数3:指定编码
soup = BeautifulSoup(string_4,'html.parser',from_encoding='utf-8');
# 获取所有图片地址;参数1:标签名称,参数2:标签属性
path = soup.find_all('img',{'class':"course-item-img"})
for link in path:
#打印标签名称,标签属性值,标签内容
print link.name, link['src'], link.get_text();注意:仅为整理的学习笔记(自学)
本作品采用《CC 协议》,转载必须注明作者和本文链接






 关于 LearnKu
关于 LearnKu




推荐文章: