
001.01 一般网页爬虫处理范例
0 / 0 / 创建于 6年前 /
 Jason990420 的个人博客
Jason990420 的个人博客
001.01 一般网页爬虫处理范例
建檔日期: 2019/07/28
更新日期: 2019/03/28 錯誤更正
| Win 10 | Python 3.7.4 |
在这里将不使用BeatifulSoup来作网页爬虫, 并尽可能不使用其他的库来完成件事, 使用别人的库来写程序, 好处是简单, 快捷, 程序码短, 而且还不一定要懂内部的细节; 但是就因为不懂细节, 就很容出错, 而且不会真正了解真正的作法等等缺点.
网页爬虫预备动作
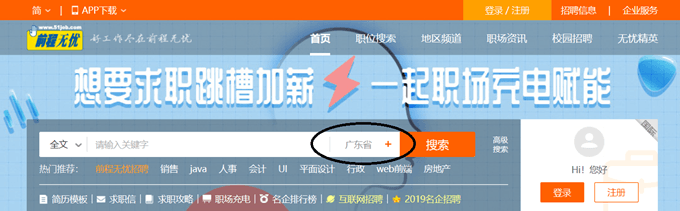
- 打开网页, 比如https://www.51job.com/, 选上方的职位搜索
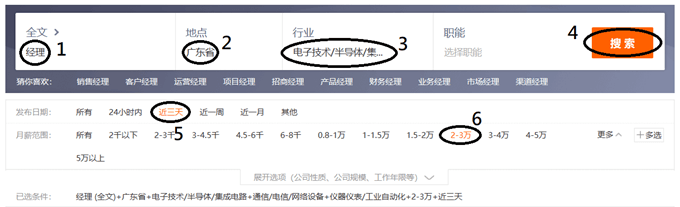
- 会出现超过十万条的工作信息, 我们并不需要这么多资料来供自己处理, 因此多加一点条件先行筛选, 按下面点选, 可以得到较少的数据, 比如撰文时的资料有491条职位, 共分10页.
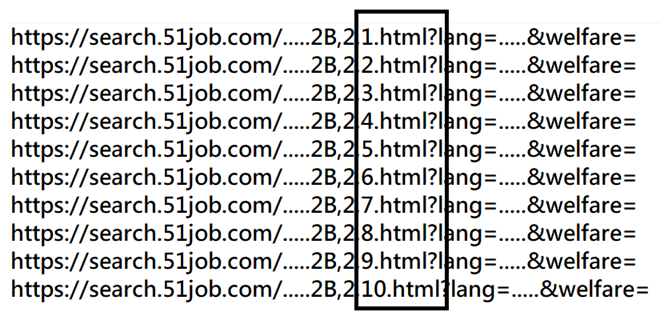
- 检查一下, 这十页的网址差异, 并建立一份十个网址的utf-8格式文本文件url.txt, 每条网址都有一些参数不同, 要自己确认. (如下图)
- 鼠标指向表格中一开始的字段, 右键单击选看”检查元素”, 检查HTML内容
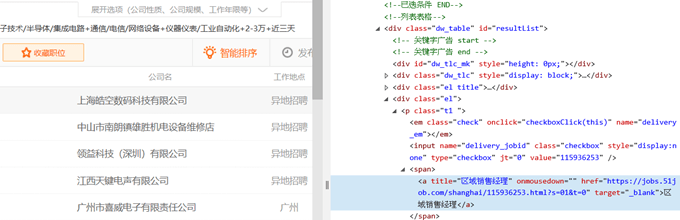
- 表格的起始位置及结束位置, 并找出表格数据所在的特别的标签或其他可以确认的字符串.

- 找出表格数据所在的特别的标签或其他可以确认的字符串.

- 在此, 我们以’<=”el title”>’为表格标题的起点, 再找到> …. <中的数据, 这就是表格的五项标题. 后面每一行的数据, 则以两个a title, 三个span class为起点, 再找到> …. <中的数据, 这就是表格的一行中的五项数据.
- 注意: 不同的系统, 浏览器所收到的HTML檔会有些差异, 比如我的前两笔数据就不是以a title为起点, 而是以a target为起点 其他部份则相同.
- 因此找出这网页的数据步骤为
- 取出 ‘‘ 到 ‘ ‘ 的HTML
- 找到 ‘<=”el title”>’, 取出’>’和’<’之间表格的五项标题
- 读取每一笔数据
- 找到 ‘a target’, 取出’>’和’<’之间表格的数据, 重复两次
- 找到 ‘span class’, 取出’>’和’<’之间表格的数据, 重复三次
- 重复以上的动作, 读取以下每一笔数据
- 找不到起点的字符串, 表示该网页数据已读取完毕, 再换下一个网页, 直到结束.
程序范例
import urllib.request
import datetime
# 取现在的时间当作档名
date = datetime.datetime.now()
url_list_file = "url.txt"
data_file_name = "Web Data " + str(date.year) + ("%02d" % date.month) + \
("%02d" % date.day) + ("%02d" % date.hour) + \
("%02d" % date.minute) + ("%02d" % date.second) +".csv"
# 读取网页及存盘用的编码`
decoder = "GB18030"
# 网页中表格的起点及终点
table_format = ['<!--列表表格-->','<!--列表表格 END-->']
area_start = table_format[0]
area_stop = table_format[1]
# 寻找字符串, 并跳过
def find_skip(in_string, string1):
global pointer, string_found
pointer = in_string.find(string1, pointer)
# 确认表格结束
if pointer < 0:
string_found = False
pointer += len(string1)
# 按起始字符串, 读取两个标记中的数据, 标记通常是'>'及'<', 并重复n次
def get_n_data(in_string, string1, string2, string3, n, data_follow):
global pointer, string_found, table
# 重复n次
for i in range(n):
# 跳过起始字符串
find_skip(in_string, string1)
# 表格结束 ?
if string_found:
# 找到第一个标记
find_skip(in_string, string2)
data_start = pointer
# 找到第二个标记
find_skip(in_string, string3)
data_stop = pointer - len(string3)
# 资料放到列表中
data = in_string[data_start : data_stop]
table.append(data.strip())
# 将列表的数据, 按CSV文本文件格式, 写入CSV檔中
def save_table(data_file_name, table):
# 表格是的空的, 不存档
if len(table) != 0:
table_data =""
count = 0
# 表格所有项目转成字符串
for item in table:
count += 1
# 每一行五个数据, 以','间隔, '\n'为结尾
if count != 5:
table_data = table_data+item+','
else:
table_data = table_data+item+'\n'
count = 0
# 建立档案, 写入数据字符串, 档案开闭
datafile = open(data_file_name, 'wt', encoding=decoder)
datafile.write(table_data)
datafile.close()
table =[]
# 读入网址档案中的每一个网址
with open(url_list_file, mode='rt', encoding='utf-8-sig') as url_list:
for url in url_list:
# 解碼读入网页HTML
try:
web_page = urllib.request.urlopen(url.strip())
except urllib.error.URLError:
print('Web page loading failed !!!')
exit()
html = web_page.read().decode(decoder)
# 网页只保留表格部份处理
pointer = 0
data_area_start = html.find(area_start)
data_area_stop = html.find(area_stop)
data_html = html[data_area_start : data_area_stop]
del html
pointer = 0
'''
省略全部表格每一栏的标题, 避免多个页标题和数据混在一起
find_skip(data_html, '<div class="el title">')
get_n_data(data_html, 'span class', '>', '<', 4, ',')
get_n_data(data_html, 'span class', '>', '<', 1, 'n')
'''
# 找不到间隔字符串, 表示表格结束
string_found = True
# 重复取得每一笔的表格数据, 找到起始字中, 再取 >......< 中的资料
while string_found:
# 两次的'a target', '< ......>'的资料
get_n_data(data_html, 'a target', '>', '<', 2, ',')
# 表格结束 ?
if string_found:
# 三次的'span class', '< ......>'的资料
get_n_data(data_html, 'span class', '>', '<', 3, '\n')
# 存表格
save_table(data_file_name, table)
# 结束
exit()注意: 由于本地变量及全局变量的混淆, 容易出错, 所以我对常用的变量, 使用了Global定义. 确认了一下, 程序读入十个网页, 取得491笔资料, 约34K档案大小, 结果使用了整整30秒.
把得到的数据, 转存为以”,”来分隔每一笔资料的.csv格式檔, 用Excel外部输入的方式, 插到Excel中, 就可以得到以下近五百笔的数据, 至于你要再作什么处理, 就看你自己了, 比如用EXCEL找出职位名有’经理’的部份.
—- The End —
本作品采用《CC 协议》,转载必须注明作者和本文链接






 关于 LearnKu
关于 LearnKu




推荐文章: