
gRPC 的接口描述语言 ProtoBuffer(二)
3 / 0 / 创建于 6年前 /
 a_wei 的个人博客
a_wei 的个人博客
什么是ProtoBuffer
ProtoBuffer是一种与语言无关,平台无关,可扩展的序列化结构化数据的方法,用于通信协议,数据存储等,ProtoBuffer由Google开发,目前各大互联网公司普遍使用,在使用时需要编写.proto文件,目前ProtoBuffer有两个版本,Pro2、Pro3,这次主要分享的是Pro3。
ProtoBuffer的特点
相比xml,json等数据序列化方式,ProtoBuffer具有如下特点
- 体积小3到10倍,(其数据格式紧密,没有多余的空格,括号,尖括号,key等)
- 性能快20到100倍(体积小了,所以传输也快,另外protobuffer也做了一个额外处理,比如传入每个字段值的长度,方便读取)
- 生成更易于以编程方式使用的数据访问类
- 支持新字段增加,向后兼容
- 支持相对复杂的数据格式
- 跨语言(为每种语言提供了编译器),跨平台(序列化结果为二进制与平台无关)
- .proto文件可读性不高,序列化后的字节序列为二进制序列,不能简单的分析有效性
ProtoBuffer安装
安装地址:https://github.com/protocolbuffers/protobu...
选择自己合适的版本进行下载
下载之后把bin文件的protoc添加到环境变量中
ProtoBuffer的数据类型和各语言的数据类型对应关系
这里只介绍几种常用的语言的,具体各语言的对应关系请看如下链接:
https://developers.google.cn/protocol-buffers/docs/proto3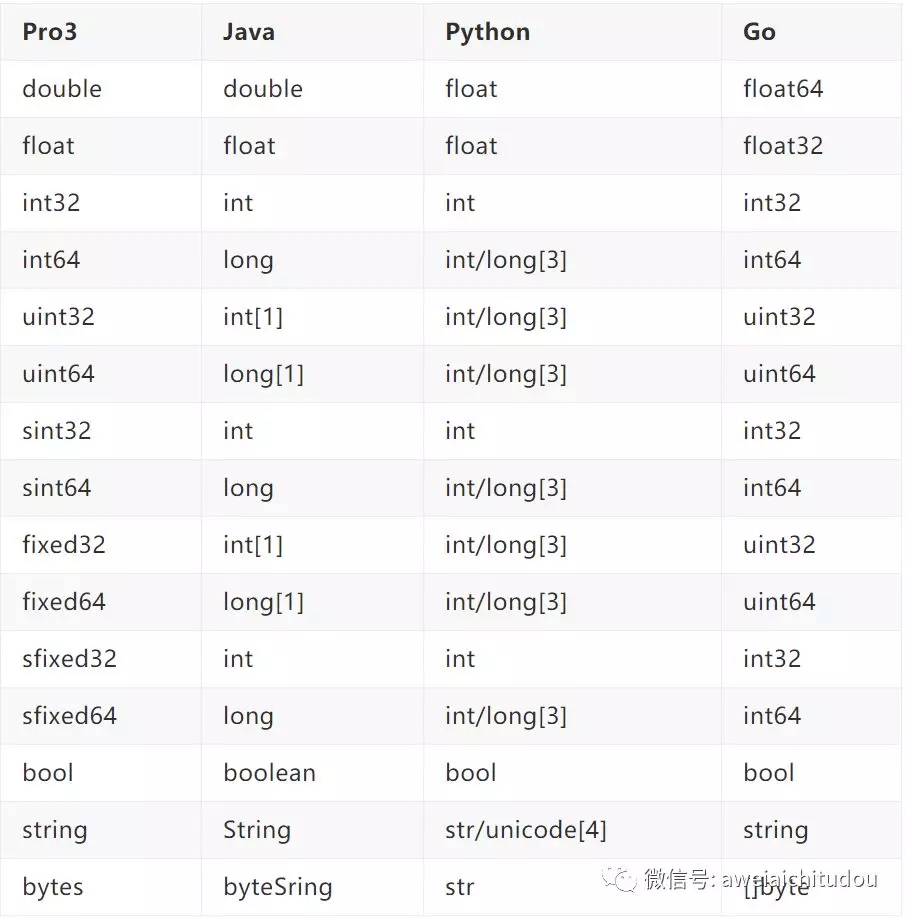
ProtoBuffer的使用
我们创建一个person.proto文件来描述人的一些信息
//声明proto的版本,并且必须是第一行,否则认为是proto2版本
syntax = "proto3";
//最终通过编译器生成的.go文件的包名
package proto_file;
//使用message定义Person结构体,按照上面的类型映射一一映射
message Person{
string no = 1;
string name = 2;
int32 age = 3;
int32 sex = 4;
enum PhoneType{
HOME = 0;
WORK = 1;
MOBILE = 2;
}
message PhoneNumber{
string number = 1;
PhoneType type = 2;
}
repeated PhoneNumber phones = 5;
repeated string address = 6;}
}解释一下上面一些字段的含义
message,类似与Java中的class,go中的struct
repeated代表这个字段是可以重复出现的,对应的就是类似数组类型
每个字段后面的编号代表着字段在序列化以后二进制数据中的位置,编号越大越往后,该值在同一message中不能重复
enum是枚举类型字段的关键字,等同于Java中的enum,HOME,WORK,MOBILE为枚举值,可以为枚举值指定任意的整型值,整型值的顺序必须连续,且在proto3中必须从0开始
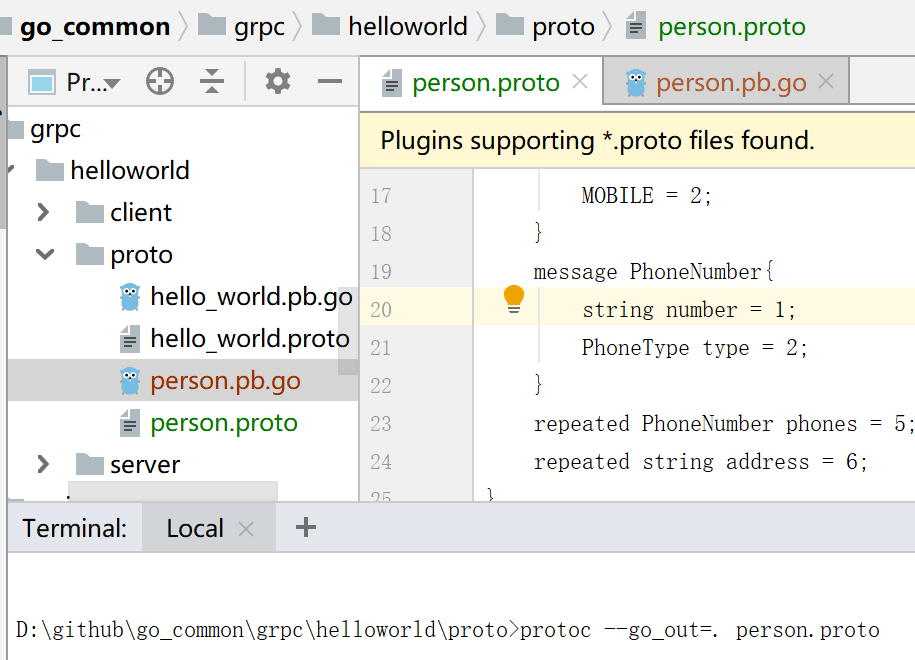
下面说一下如何将proto文件编译成go文件
- 我们通过protobuffer提供的插件来生成对应的person.pb.go文件
- 首先下载插件 go get -u github.com/golang/protobuf/protoc-gen-go
- 然后执行以下命令生成对应的go文件
- protoc -I "proto文件的路径" --go_out="生成的go文件的路径" route_guide.proto
- 我我这里使用的命令是:protoc --go_out=. route_guide.proto
- 没有 -I代表我在proto文件下执行的命令, .代表我最后生成的.pb.go文件在当前目录下,如下截图:
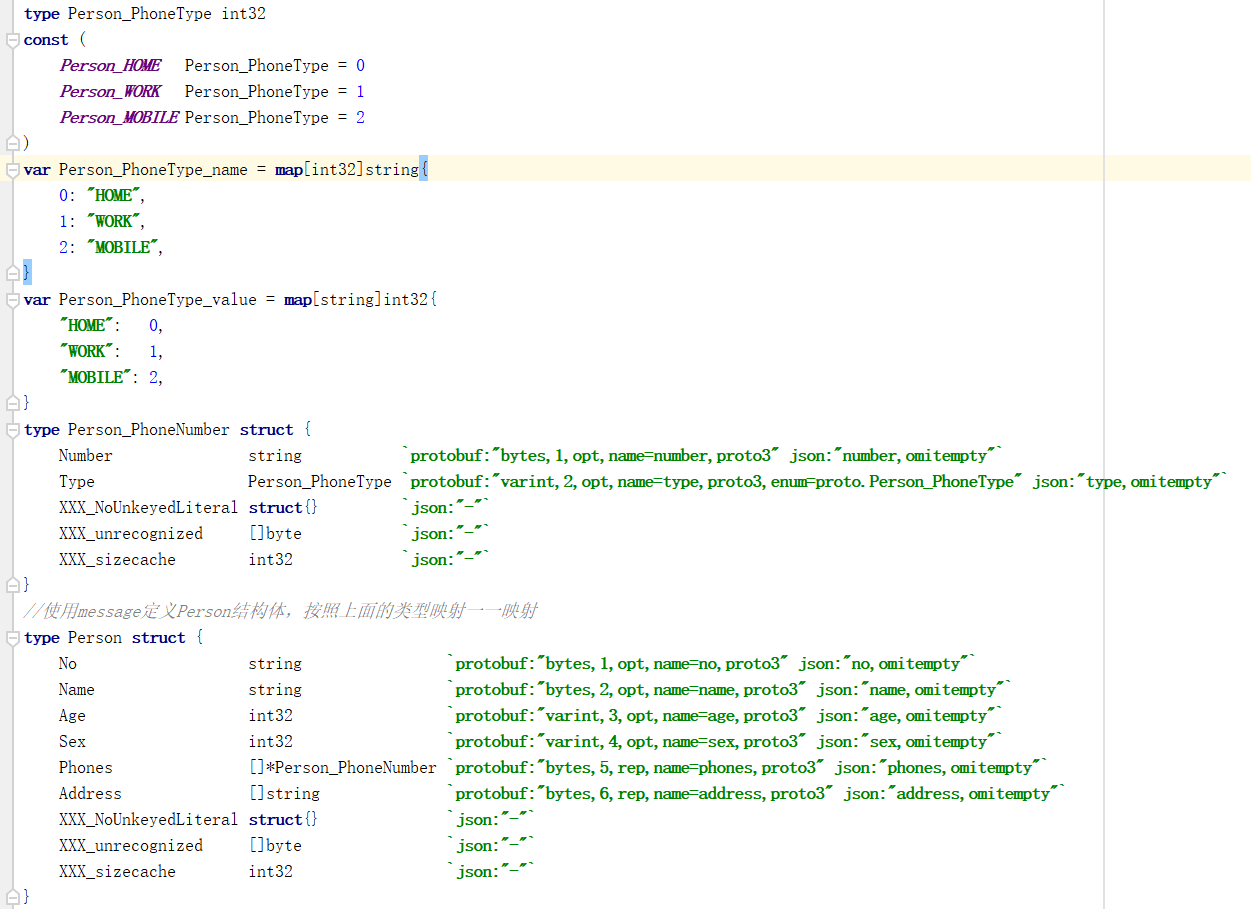
最终生成的代码如下,截取一些核心代码,我们可以看到protobuffer编译器将proto文件能够转化为go的struct
ProtoBuffer的原理
什么是Base 128 varint?这是一个编码算法,我们都知道,int32占四个字节,int64占8个字节,这是固定的,不管这个数字是1还是123456,占的字节数是一样,那有没有一种能根据数字大小变长编码的算法呢?Base 128 varint就是,在设置二进制网络协议通信时,这种好处是可观的,能够带来性能上的提升。为什么叫128呢,就是因为采用7bit的空间存储数据(一个字节占8bit,但只采用7bit),7bit最大当然只能存储128了,那么最高位干啥呢?最高位用来当作一个标识(flag),如果最高位是0就表示这个最后一个字节了。
示例:我们用一个数字10和数字300来讲解一下上面的Base 128 varint
先说数字10,转化为二进制后是:0000 1010,为什么只有八位呢,因为10用一个字节表示已经足够了,最高位为0(加粗的那个),表示这是最后一个字节了,不需要再用额外的字节来存储了
再来看数字300,转化为二进制后是:00010010_1100,转化成varint,如下步骤:
- 按照7位进行分开, 0000010_0101100,不够的补0
- 进行反转:0101100_0000010
- 最高位补数,第一个字节最高位补1,第二个字节最高位补0:10101100_00000010
ProtoBuffer序列化后的存储格式是什么样的呢?
Tag,Length,Value ,这是序列化后存储的二进制的格式,Tag大家简单理解为就是proto文件中字段后面的编号,Length是这个字段对应的值的字节长度,Value就是具体的值了,最终将所有数据拼装成一个流,如下图:
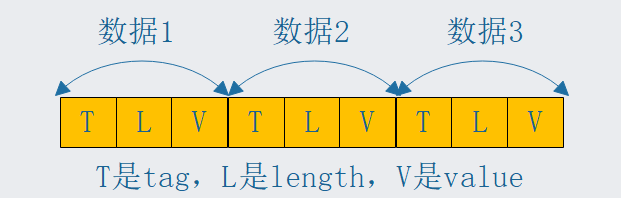
由图我们得知,ProtoBuffer存储是紧密的,各个字段非常紧凑,不会浪费空间,若某个字段没有赋值,则不会出现在序列化后的数据中,相应字段在解码时才会被设置默认值。
ProtoBuffer对不同类型数据采用编码方式和存储方式,如下图:
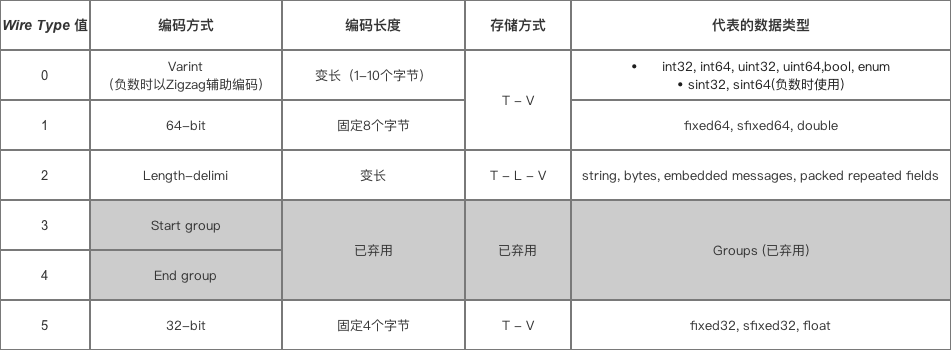
如上图,如果采用varint方式,则存储的格式是TV格式,没有L,因为T上就已经知道V的字节长度了。
T代表的tag是由fieldNumber(字段编号)和wireType(上图中最左边的0,1,2...)组成的,fieldNumber保证了字段不重复和他在数据流中的位置,wireType标记了数据类型,如果是varint便哈,fieldNumber也保证了数据字节的长度(L)
varint编码的不足
- 整数1在计算几存储中二进制是0000 00001,那么你知道整数-1的二进制呢?如下:
- 11111111_11111111_11111111_11111111,如果也采用varint编码那么就需要至少占用5个字节,这显然有些浪费空间,ProtoBuffer的解决方案如下:
- ProtoBuffer定义了sint32和sint64类型来表示负数,通过先采用Zigzag编码(将由符号数转化成无符号数),再采用varint编码,从而用于减少编码后的字节数

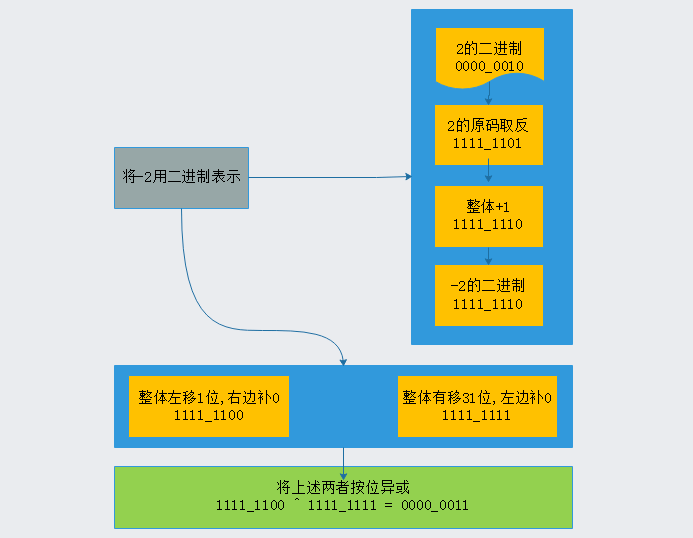
什么是Zigzag编码?
Zigzag也是一种变长的编码方式,使用无符号数表示有符号数,作用是使得绝对值小的数字可以采用较小子的字节进行表示,Zigzag编码是辅助varint在编码负数时的不足,从而更好的帮助ProtoBuffer进行数据的压缩,下面一张图了解:
总结
ProtoBuffer编解码方式简单(只需要简单的数学运算,位运算)
ProtoBuffer数据压缩方式好,占用的空间小
ProtoBuffer兼容性好,采用TLV的存储格式
参考文章:
https://blog.csdn.net/carson_ho/article/de...
https://developers.google.cn/protocol-buff...
https://www.jianshu.com/p/522f13206ba1

本作品采用《CC 协议》,转载必须注明作者和本文链接






 关于 LearnKu
关于 LearnKu




推荐文章: