
elastic-job-lite 数据结构分析
0 / 0 / 创建于 6年前 /
 a_wei 的个人博客
a_wei 的个人博客
开篇语
程序=数据结构+算法,由此可见,数据结构是多么的重要,任何一个框架底层都有自己数据存储结构,elastic-job-lite是一个开源的分布式任务调度框架,其基于zk来存储运行时job信息,配置信息等等,也就是说zk是它的注册中心,所以它的数据结构也和zk有关,今天我们就一起聊聊elastic-job-lite数据结构,一起揭开它的神秘面纱。
EJL数据结构整体概要介绍
在ejl中数据结构的根节点是命名空间,由开发人员在zk的配置中指定,如下代码,ejl中的数据结构都在zk的命名空间下存在(也就是可以同一zk集群,可以基于命名空间做隔离)
regCenter:
serverList: x.x.x.x:2181,x.x.x.x:2181
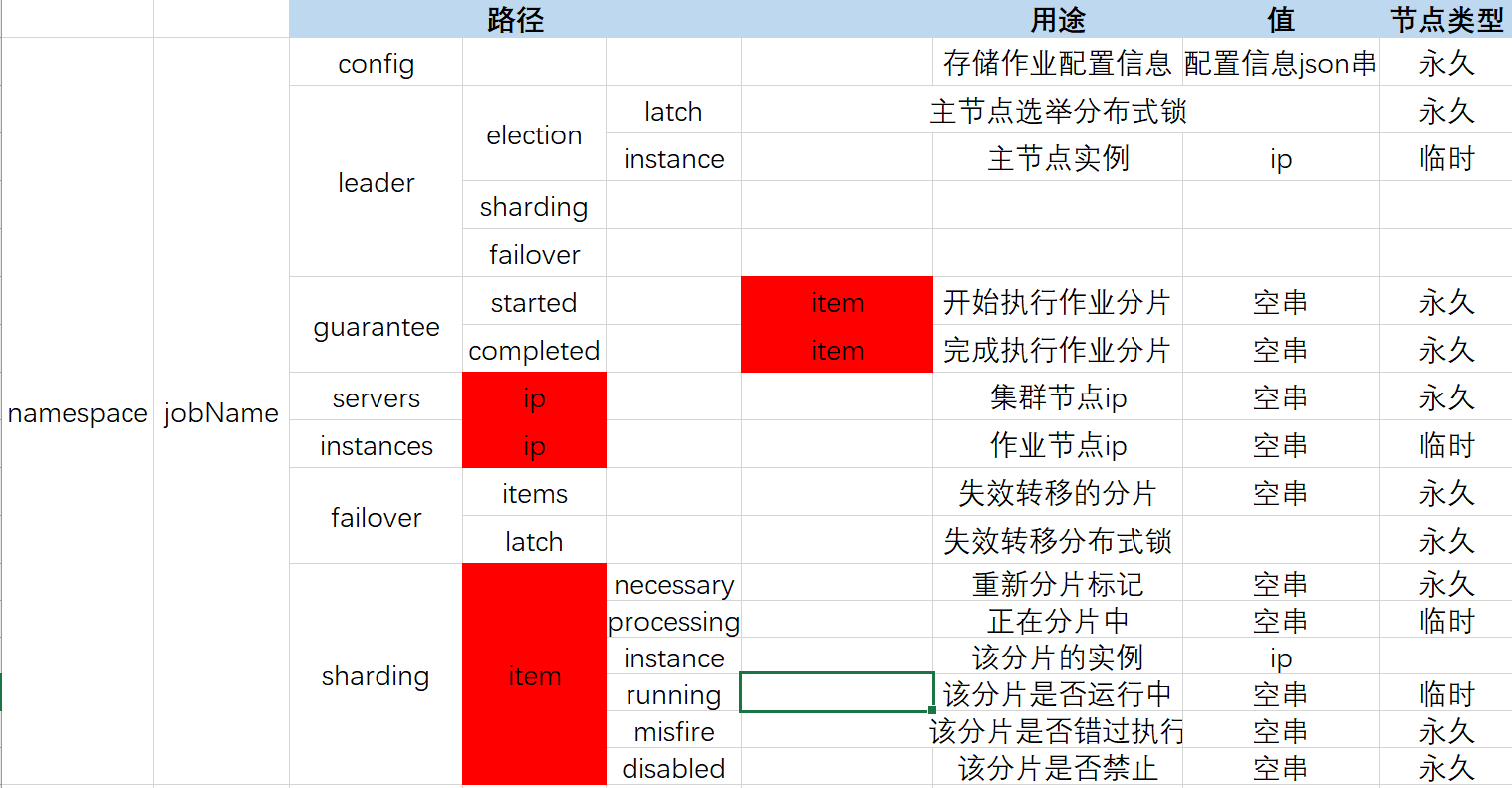
namespace: bs在命名空间之下,存放各个job的名称,通过jobName用来做区分,JobName就是类的全限定名称,比如com.xxx.job.SimpleJobTest;在jobName下,就是各个Job的数据结构了,总的来说如下:
- name_space1 命名空间1
- jobName1 作业名称2
- ConfigurationNode /confg 作业的配置信息
- LeaderNode /leader 作业的主节点选举信息
- FailoverNode /failover 作业失效转移信息
- GuaranteeNode /guarantee 作业分布式全部开始和结束信息
- InstanceNode /instance 作业运行实例信息
- ServerNode /servers 集群服务器信息
- ShardingNode /sharding 作业分片信息
- jobName2 作业名称2
- ......
- jobName1 作业名称2
- name_space2 命名空间2
- ......
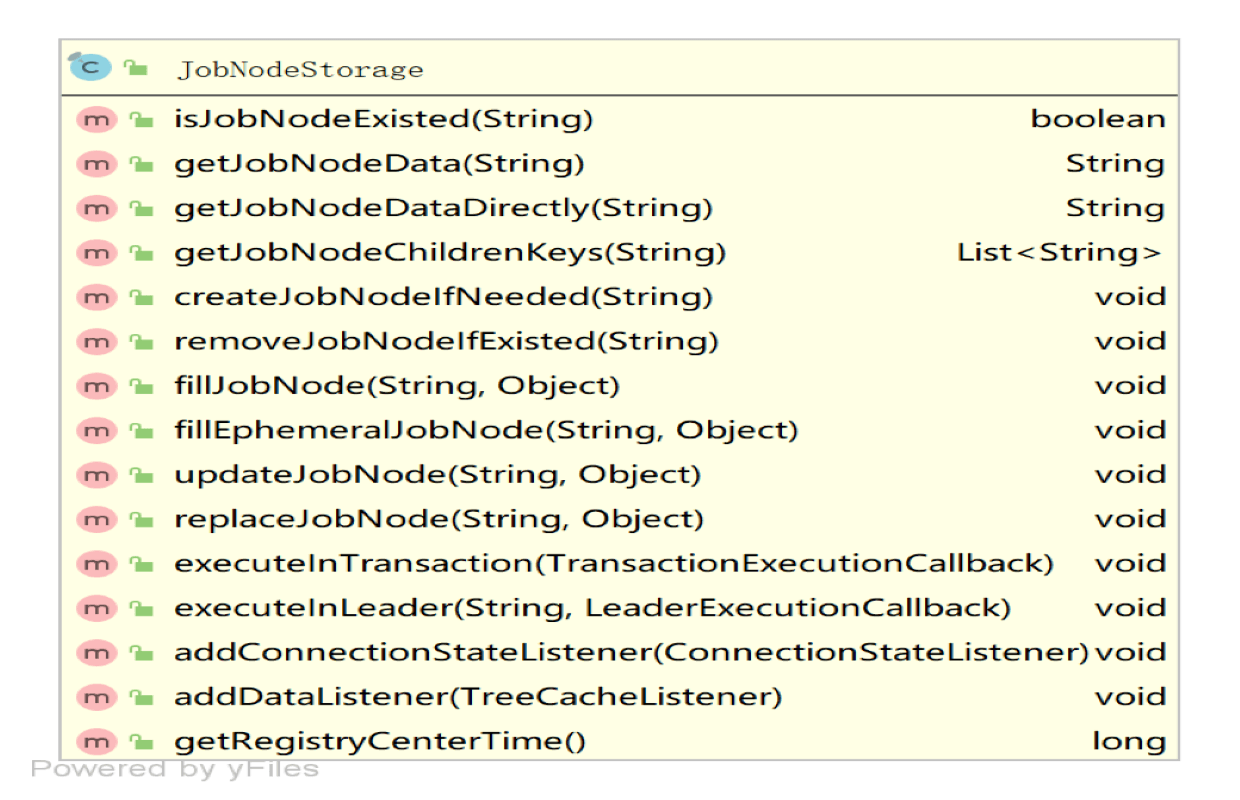
上面整体描述了作业的数据结构,那么这些数据结构是怎么操作呢?在ejl中,存在这么一个服务:io.elasticjob.lite.internal.storage.JobNodeStorage,通过此类来操作job的各个节点(增删改查),这个类比较偏底层,事实上,每个数据结构都有对应的一个服务(比如ConfigurationService...等),服务中统一调用JobNodeStorage来具体来实现,具体方法如下
细节介绍
通过上面我们整理我们对ejl的数据结构整体有了清晰的认识,ejl的数据结构就是一个tree,或者你理解为一个目录,一级一级的,接下来我们就深入看一下数据结构中每一个节点的作用,在此之前,我们假设我们的namespace的名称为,cluster1,有一个job,job的名称为com.xxx.job.SimpleJobTest,那么数据结构的前缀如下:我们为前缀起一个别名: cs
/cluster1/com.xxx.job.SimpleJobTest/ -> csConfigurationNode
其在zk中表示为下: /cs/conifg,这个节点中存储是的job的配置信息,字符串形式
LeaderNode
这个是job分布式锁的根节点,在zk中表示如下:/cs/leader/,在下面还有多级节点,如下:
- election
- latch 这是job选举leader的分布式锁
- instance 这是选举成功后存储leader节点的job名称
FailoverNode
失效转移节点是基于leader的,也就是说failover也是在leader下面,因为是功能不一样,所以没放在上面,在zk中表示为下:/cs/leader/failover/,在下面也有多级节点:
- items 这个节点下面存放的失效转移的分片,判断是否需要失效转移,也就是判断这个节点下面是否有数据
- latch 执行失效转移时的分布式锁,谁获得了锁,谁处理这个分片的数据
GuaranteeNode
这个节点是统一作业各个分片一起开始执行,到最后全部完成执行结束,在zk中表示如下:/cs/guarantee/,举个例子,比如想在作业执行前和执行后做一些事情,但因为作业是分布式的,怎么搞呢?每个节点在执行前同一个往一个地方写一个标记,大家标记都写好了,就意味着大家都准备好了,可以开执行了,这个时候可以加个监听器做一点事情(日志打印),等每个节点都执行完了,也写一个标记,最终所有节点写完了,也加个监听器做一点事情(资源清理),在下面有两个多级节点:
- started 作业开始每个节点往这里写标记
- completed 作业完成后每个节点往这里写标记
InstanceNode
这个节点是存储作业运行的实例信息,也就是这个job由那些实例运行呢,在zk中表示为: /cs/instances/,对应的数据就是实例的ip
ServerNode
这个节点用来保存集群服务器的信息,就是说有多少机器在zk中注册,在zk的中表示如下:/cs/servers/,存储的数据是机器的ip。
ShardingNode
这个节点也依赖leader节点,作用是否需要失效转移?这个节点主要存储作业的分片信息,在zk中表示为:/cs/sharding/,在下面有多个多级节点
依赖leader
/leader/sharding/necessary 作用是每次作业启动时检查是否需要重新分片,如果这个节点存在,说明需要重新分片,分片结束后删除,当分片总数增加,或者有分片机器下线时,会设置此节点
/leader/sharding/processing 当开始重新分片时,会创建这个节点,分片结束后删除这个节点
不依赖leader
instance 存储当前分片的实例信息
running 存储正在运行的分片项
misfire 当该作业被错过执行时,该节点存在,当被执行后,该节点删除
disabled 当作业该分片被禁用时,节点存在,开启时,删除
上面我们详细描述job的各个数据结构,并表明了其作用,大家可结合上源码一起学习,进入源码的数据结构class中。具体哪个类,上面以写明。
整理
最后把涉及的数据结构整理成一个表格,大家一目了然

本作品采用《CC 协议》,转载必须注明作者和本文链接





 关于 LearnKu
关于 LearnKu



