
笔记六十:提升集群读性能
43 / 2 / 创建于 4年前 /
 CrazyZard 的个人博客
CrazyZard 的个人博客
尽量 Denormalize 数据
- Elasticsearch != 关系型数据库
- 尽可能 Denormalize 数据,从而获取最佳的性能
- 使用 Nested 类型的数据。查询速度会慢几倍
- 使用 Parent / Child 关系。查询速度会慢几百倍
数据建模
- 尽量将数据先行计算,然后保存到 Elasticsearch 中。尽量避免查询时的 Script 计算
- 尽量使用 Filter Context,利用缓存机制,减少不必要的算分
- 结合 profile,explain API 分析慢查询的问题,持续优化数据模型
- 严禁使用 * 开头通配符 Terms 查询
避免查询时脚本
- 可以在 Index 文档时,使用 Ingest Pipeline,计算并写入某个字段

常见的查询性能问题 - 使用 Query Context
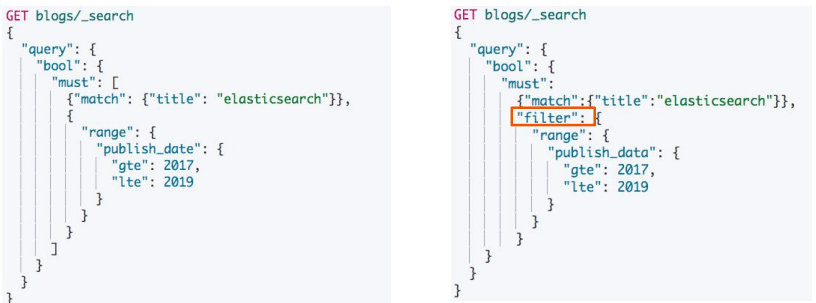
聚合文档消耗内存
- 聚合查询会消耗内存,特别是针对很大的数据集进行聚合运算
- 如果可以控制聚合的数量,就能减少内存的开销
- 当需要使用不同的 Query Scope,可以使用 Filter Bucket

通配符开始的正则表达
- 通配符开头的正则,性能非常糟糕,需避免使用

优化分片
- 避免 Over Sharing
- 一个查询需要访问每一个分片,分片过多,会导致不必要的查询开销
- 结合应用场景,控制单个分片的尺寸
- Search: 20GB
- Logging:40GB
- Force-merge Read-only 索引
- 使用基于时间序列的索引,将只读的索引进行 force merge,减少 segment 数
读性能优化
- 影响查询性能的一些因素
- 数据模型和索引配置是否优化
- 数据规模是否过大,通过 Filter 减少不必要的数据计算
- 查询语句是否优化
本作品采用《CC 协议》,转载必须注明作者和本文链接


 关于 LearnKu
关于 LearnKu




集群压力测试 这一章 没有
你是有课堂的ppt 吗 ?