
ThinkSNS+ 是如何计算字符显示长度的(使用 Laravel 自定义验证规则)
1 / 15 / 创建于 9年前
 medz 的个人博客
medz 的个人博客
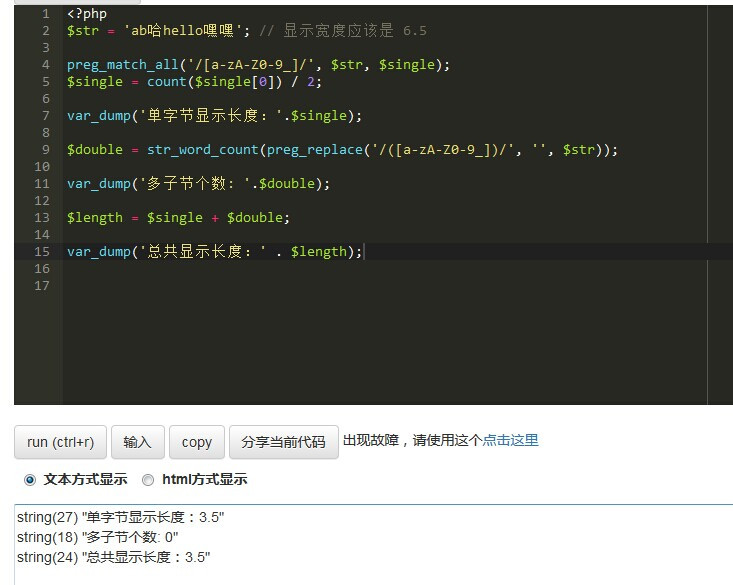
好久没分享了,今天我们来聊一下可能很对人都会头疼的东西。
没错,显示长度,需求是这样子的,在字符的显示上,两个英文单词才占一个中文或者其他语言的显示长度。如下:
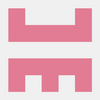
ab
哈
?上面排的是两个英文字母,一个汉字,一个 Emoji 。你会发现,在显示上占的宽度是一致的。一些设计上为了好看也要求有这样的处理。
例如,我们的用户名需求是 最多12个非单字节字符或者24个单字节字符的需求也可以混合排的需求,我们写后端不得不处理这样的验证了。
需求规则是
/^[a-zA-Z_\x7f-\xff][a-zA-Z0-9_\x7f-\xff]*$/
在 ThinlSNS+ 中,为了能把这部分验证公用,所以选择使用 自定义验证规则。算了,先说下计算的实现思路吧!
首先,就算是 mb_strlen 也没法准确的获取 多字节字符和单子节字符混合在一起的长度,网上有个说法,汉字占三个子节,英文数组半角符号占一个子节,所以:
(mb_strlen($str) + strleng($str)) / 2用这个方法可以得到单字节占0.5多字节占1的计算。但是以中文为例,只有两万个汉字才是这种情况,还有六万多汉字是四个,其次,emoji 也是四个字节。根本无法准确的计算。
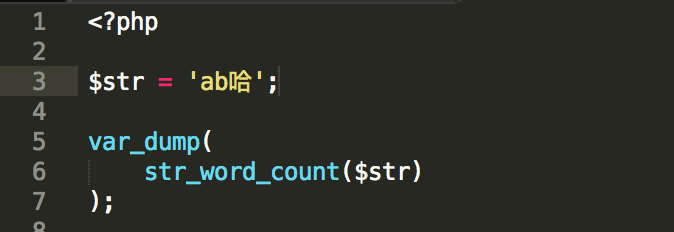
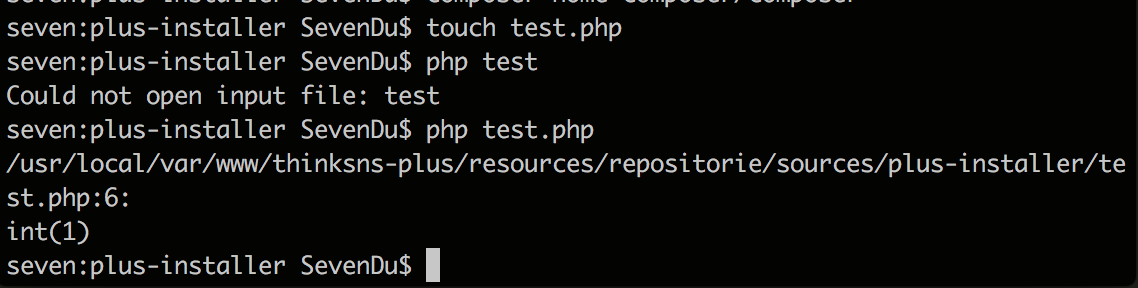
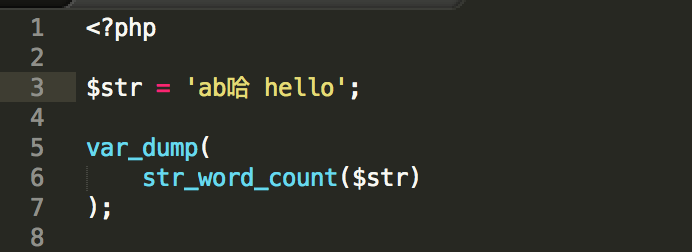
后在在无意间发现一个奇怪的东西 str_word_count 这个函数计算非英文单词外是除了符号例如中文就是按照汉字个数算的,emoji也是同理。发现这个后就好办了。我们吧用户名中的 [a-aA-Z0-9_] 剔除掉单独计算不就是我们要的验证长度了吗?
所以,首先我们用:
preg_match_all('/[a-zA-Z0-9_]/', $value, $single);
$single = count($single[0]) / 2;方式单独计算出单字节字符的显示长度,再用:
$double = str_word_count(preg_replace('([a-zA-Z0-9_])', '', $value));方式计算出多字节的长度,最后:
$length = $single + $double;就得出了显示长度,实现了,最后封装成验证规则:
Validator::extend('display_length', function ($attribute, $value, array $parameters) {
if (empty($parameters)) {
throw new \InvalidArgumentException('Parameters must be passed');
}
$min = 0;
if (count($parameters) === 1) {
list($max) = $parameters;
} elseif (count($parameters) >= 2) {
list($min, $max) = $parameters;
}
if (! isset($max) || $max < $min) {
throw new \InvalidArgumentException('The parameters passed are incorrect');
}
// 计算单字节.
preg_match_all('/[a-zA-Z0-9_]/', $value, $single);
$single = count($single[0]) / 2;
// 多子节长度.
$double = str_word_count(preg_replace('([a-zA-Z0-9_])', '', $value));
// 得出最终计算字符的长度
$length = $single + $double;
return $length >= $min && $length <= $max;
});代码是原型代码,还没有进行优化,之后我们只要按照下面的方式用:
$rules = [
'inputKey' => 'display_length:5', // 表示 0 - 5 显示长度
‘inputkey2’ => 'display_length:4,12' // 表示显示长度为 4 - 12
];很好的解决了这个需求。
我们很乐意在开发基于 Laravel 的 ThinkSNS+ 产品中的技术解决分享给大家,也希望喜欢的朋友能给国内开源产品一点点的支持。
GitHub: https://github.com/zhiyicx/thinksns-plus
求关注求 Star ?
本作品采用《CC 协议》,转载必须注明作者和本文链接



























 关于 LearnKu
关于 LearnKu




推荐文章: