
Elasticsearch基础结构
0 / 0 / 创建于 5年前 /
 Runtoweb3 的个人博客
Runtoweb3 的个人博客
集群:
ES节点:运行的ES实例
ES集群由若干节点组成,这些节点在同一个网络内,cluster-name相同
节点:
master节点:集群中的一个节点会被选为master节点,它将负责管理集群范畴的变更,例如创建或删除索引,添加节点到集 群或从集群删除节点。master节点无需参与文档层面的变更和搜索,这意味着仅有一个master节点并不会因流量增长而成为 瓶颈。任意一个节点都可以成为 master 节点
data节点:持有数据和倒排索引。默认情况下,每个节点都可以通过设定配置文件elasticsearch.yml中的node.data属性为 true(默认)成为数据节点。如果需要一个专门的主节点,应将其node.data属性设置为false
Client节点:如果将node.master属性和node.data属性都设置为false,那么该节点就是一个客户端节点,扮演一个负载均衡的角色,将到来的请求路由到集群中的各个节点,也就是执行协调节点的功能。
协调节点(Coordinating node)
协调节点,是一种角色,而不是真实的Elasticsearch的节点,你没有办法通过配置项来配置哪个节点为协调节点。集群中的任何节点,都可以充当协调节点的角色。当一个节点A收到用户的查询请求后,会把查询子句分发到其它的节点,然后合并各个节点返回的查询结果,最后返回一个完整的数据集给用户。在这个过程中,节点A扮演的就是协调节点的角色。毫无疑问,协调节点会对CPU、Memory要求比较高。
故障转移
当一个节点掉线,如果该节点是master节点,则通过比较node ID,选择较小ID的节点为master。然后由master节点决定分片如何重新分配。同理,新加入节点也是由master决定如何分配分片。
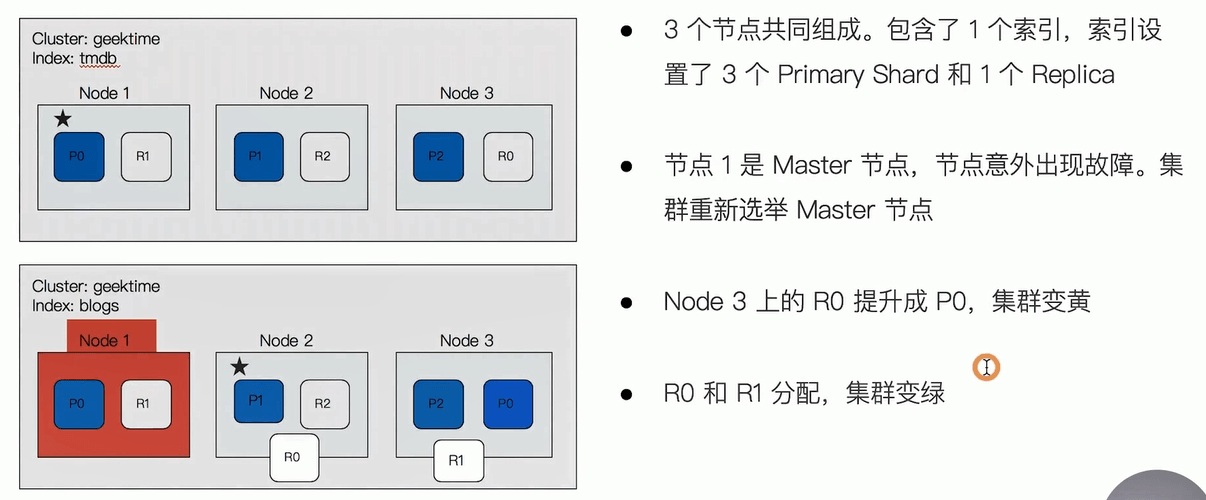
星号的就是master节点
分片
shard:单台机器无法存储大量数据,es可以将一个索引中的数据切分为多个shard,分布在多台服务器上存储(如果节点不够,也会在一个node分片多个shard)。shard又分为primary shard和replica shard,每个shard都是一个lucene index。
Segment
在Lucene中,单个倒排索引文件被称为segment,多个segment汇总在一起,就是lucene的index,也就是一个分片。写入新的文档,就会生成新的segment.搜索过程,就是搜索所有的segment.一个分片的所有的segment文件的信息保存在commit point文件中。而删除的文档会记录到.del文件中。
搜索过程就是从commit point文件找到所有的segment文件进行查询,然后排除掉.del中的文档。
删除文档,是直接把删除的文档写入到.del。
Refresh
写入文档,会先写入到index buffer 和transaction log(会写入磁盘)中,然后讲index buffer写入到segment中,这个过程就是refresh,默认是1s refresh一次。refresh后,数据就可以被搜索到。
Flush
主要就是把segment写入磁盘,会先调用refresh,把index buffer数据清空,生成新的segment.然后调用fsync把segment写入磁盘,然后清空Transaction log.默认30min执行一次Flush,或者translation log(512m)满
Merge
因为每次refresh,都会产生新的segment,所以可以通过merge操作可以把多个segment文件合并,并且删除掉.del里面的文档。
本作品采用《CC 协议》,转载必须注明作者和本文链接





 关于 LearnKu
关于 LearnKu



