
IK 分词器插件
0 / 0 / 创建于 5年前 /
 HuDu 的个人博客
HuDu 的个人博客
什么是 IK 分词器
分词∶即把一段中文或者别的划分成一个个的关键字,我们在搜索时候会把自己的信息进行分词,会把数据库中或者索引库中的数据进行分词,然后进行一个匹配操作,默认的中文分词是将每个字看成一个词,比如“我爱编程”会被分为"我""爱""编""程”,这显然是不符合要求的,所以我们需要安装中文分词器ik来解决这个问题。
如果使用中文,建议使用ik分词器!
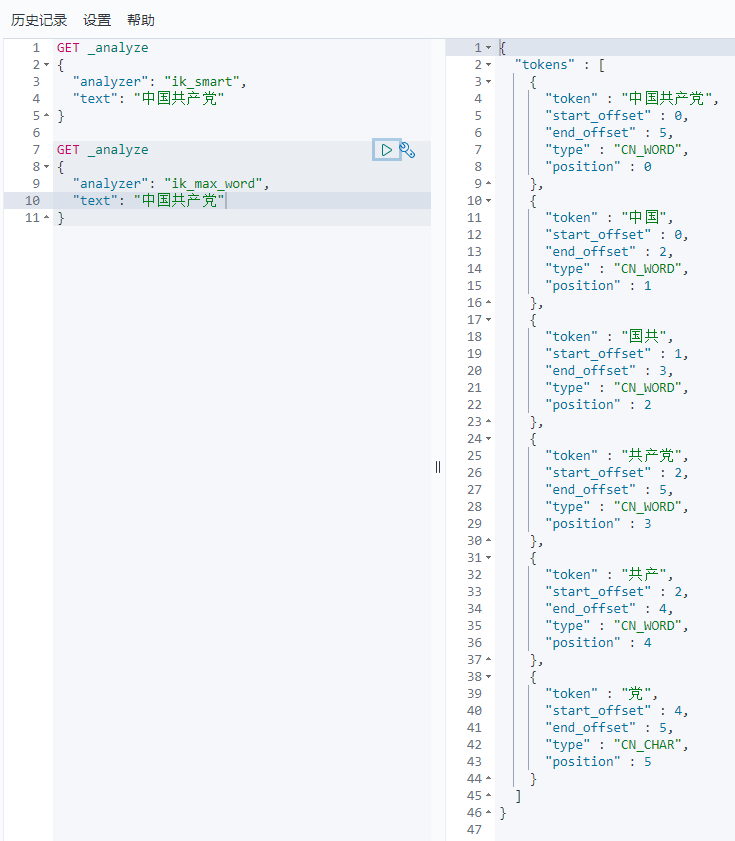
IK提供了两个分词算法:ik_smart和ik_max_word,其中 ik_smart为最少切分,ik_max_word为最细粒度划分!- 注意:在 ES 中默认使用的是标准分词器:StandarAnalizer,特点:中文单字分词,英文单词分词
分词器(analyzer)都由三种构件组成:
character filter,tokenizers,token filters
character filter字符过滤器- 在一段文本进行分词之前,先进行预处理,比如对常见的就是过滤 html 标签
tokenizers分词器- 英文分词可以根据空格将单词分开,中文分词比较复杂,可以采用机器学习算法来分词。
token filterstoken 过滤器- 将切分的单词进行加工,大小写转换(例如将”Quick”转为小写),去掉停用词(例如停用像 a、and、the等),加入同义词(例如同义词像 jump 和 leap)
注意:
- 三者顺序:Character Filters–>Tokenizer–>Token Filter
- 三者个数:Character Filters(0个或多个) + Tokenizer + Token Filters(0 个或多个)
内置分词器
- Standard Analyzer - 默认分词器,英文按照单词切分,并小写处理,中文按照单字分词
- Simple Analyzer - 英文按照单词分词(符号被过滤),小写处理,中文按照空格分词
- Stop Analyzer - 小写处理,停用词过滤(the,a,is)
- Whitespace Analyzer - 按照空格切分,不转小写,不去标点符号
- Keyword Analyzer - 不分词,直接将输入当作输出
IK 分词器配置
- 1、下载:IK 分词器下载地址
- 2、下载完毕之后,放入到我们的elasticsearch插件即可
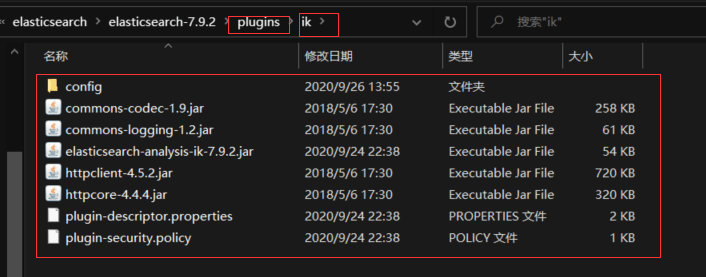
- 3、重启观察ES,可以看到ik分词器被加载了!

如果是安装了Linux集群
# 每个节点都执行
$ mkdir -p /opt/elasticsearch/plugins/ik
$ unzip elasticsearch-analysis-ik.zip -d /opt/elasticsearch/plugins/ik- 4、elasticsearch-plugin 可以通过这个命令查看加载进来的插件

使用kibana测试
查看不同的分词效果
ik_smart最少切分
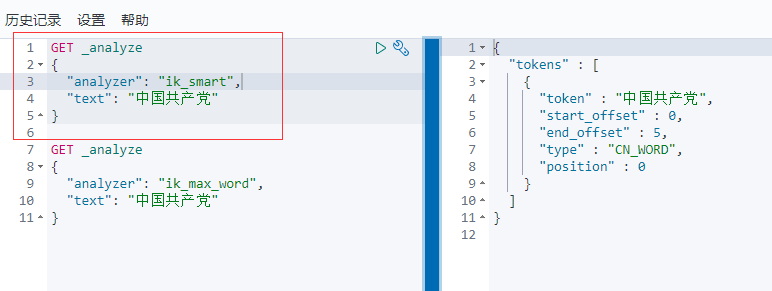
ik_max_word为最细粒度划分,穷尽词库的可能!
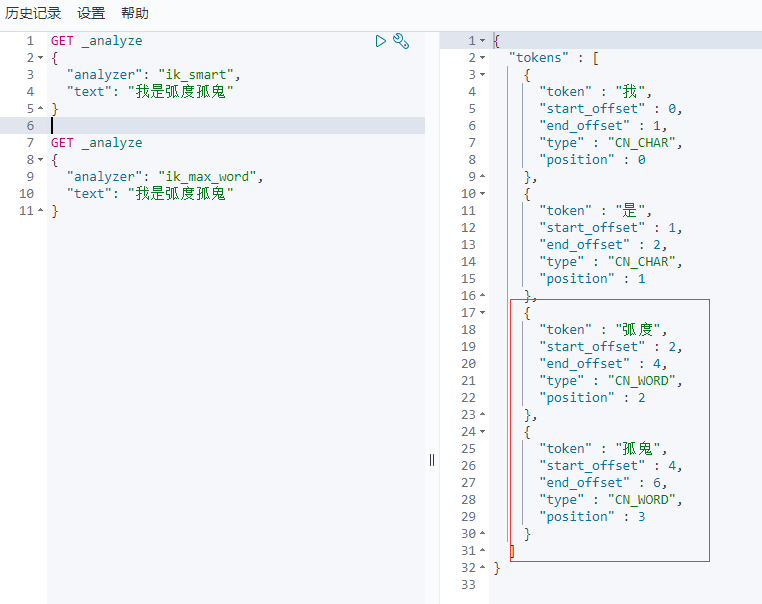
发现问题:弧度孤鬼被拆开了
这种自己需要的词,需要自己加到我们的分词器的字典中
创建索引测试
curl -X PUT http://192.168.122.161:9200/poetry {
"settings": {
"number_of_shards": 3,
"number_of_replicas": 1
},
"mappings": {
"dynamic": "false",
"properties": {
"name": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
},
"author": {
"type":"keyword"
},
"dynasty": {
"type": "keyword"
},
"content": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
}
}
}
}- 插入数据
$ curl -X POST http://192.168.122.161:9200/poetry -H 'Content-Type:applicatoin/json' -d '{
"name": "望庐山瀑布",
"author":"李白",
"dynasty":"唐代",
"content":"日照香炉生紫烟,遥看瀑布挂前川,飞流直下三千尺,疑是银河落九天。"
}'
$ curl -X POST http://192.168.122.161:9200/poetry -H 'Content-Type:applicatoin/json' -d '{
"name": "静夜思",
"author":"李白",
"dynasty":"唐代",
"content":"床前明月光,疑是地上霜。举头望明月,低头思故乡。"
}'
$ curl -X POST http://192.168.122.161:9200/poetry -H 'Content-Type:applicatoin/json' -d '{
"name": "春夜喜雨",
"author":"杜甫",
"dynasty":"唐代",
"content":"好雨知时节,当春乃发生。随风潜入夜,润物细无声。野径云俱黑,江船火独明。晓看红湿处,花重锦官城。"
}'
- 组合条件查询
- must,must not,should 的区别
- must 返回的文档必须满足 must 子句的条件,类似于 == and
- must not 返回的文档必须不满足 must nost 子句的条件 类似于 != not
- should 返回的文档只要满足 should 中的一个条件即可 类似于 || or
- 各类查询参数
- term
- 把检索串当作一个整体来执行检索,即不会对检索串分词
- text
- 会将检索词进行分词,然后对数据进行匹配
- prefix
- 就是前缀检索,比如商品 name 中有多个以 “Java” 开头的 document,检索前缀 “Java” 时就能检索到所有以”Java”开头的文档
- wildcard 通配符查询
- 通配符检索,例如
java*
- 通配符检索,例如
- fuzzy 纠错检索
- fuzziness 的默认值是 2 – 最多可以纠错两次
- 例如:检索 name 中包含 “Java” 的文档,Java 中缺失了一个字母 a
get shop/_search { "query": { "match": { "query": "Jav", "fuzziness": 1, "operator": "and" } } }
- rang
- 区间查询,如果 type 是时间类型,可用内置 now 表示当前, -1d/h/m/s 来进行时间操作
- query_string
- 可以对 int,long,string 查询,对 int,long 只能本身查询,对 string 进行分词和本身查询
- missing
- 返回没有字段或值为null的文档
- term
- must,must not,should 的区别
ik分词器配置扩展词及停用词
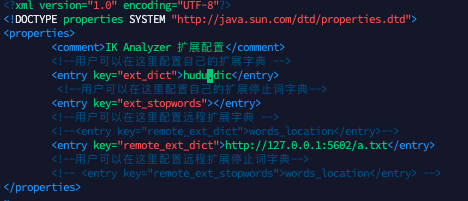
加载了我们自定义的dic文件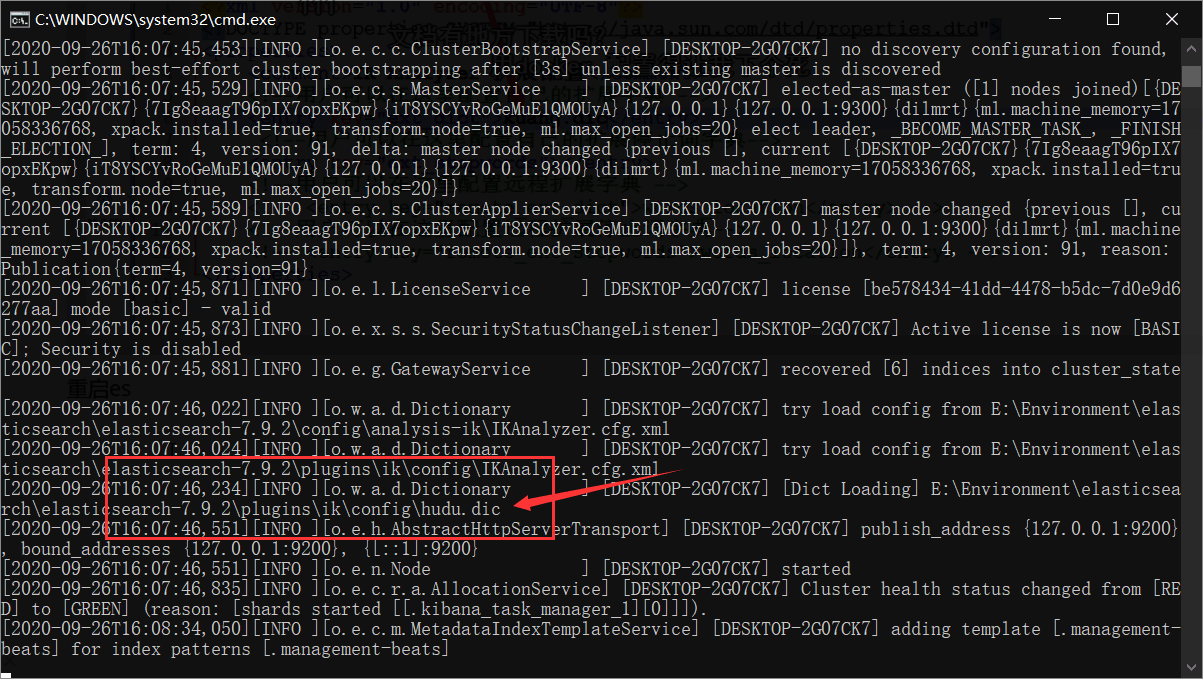
再次测试一下
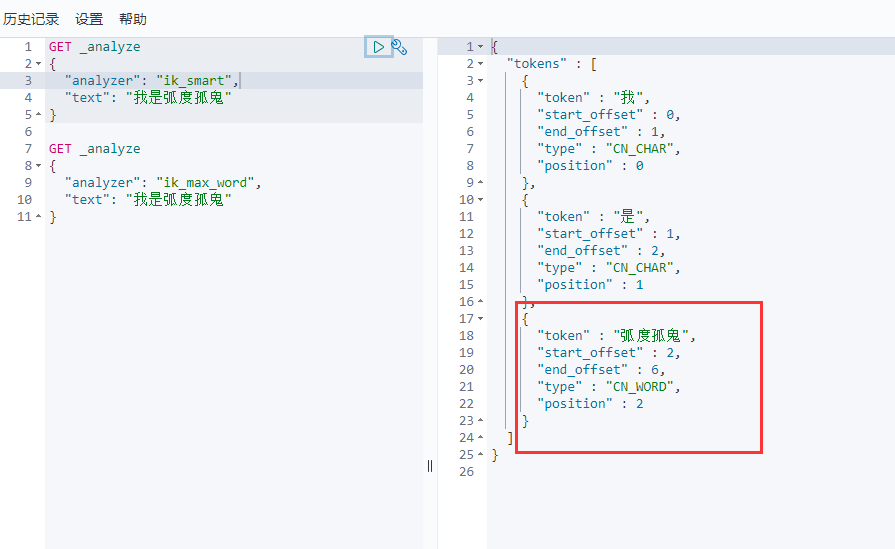
以后,我们需要自己配置分词就在自定义的dic文件中进行配置即可!
本作品采用《CC 协议》,转载必须注明作者和本文链接





 关于 LearnKu
关于 LearnKu



