
solr8.6.2 客户端界面介绍及配置中文分词器
0 / 0 / 创建于 5年前 /
 HuDu 的个人博客
HuDu 的个人博客
启动solr服务
访问http://localhost:8080/solr/index.html
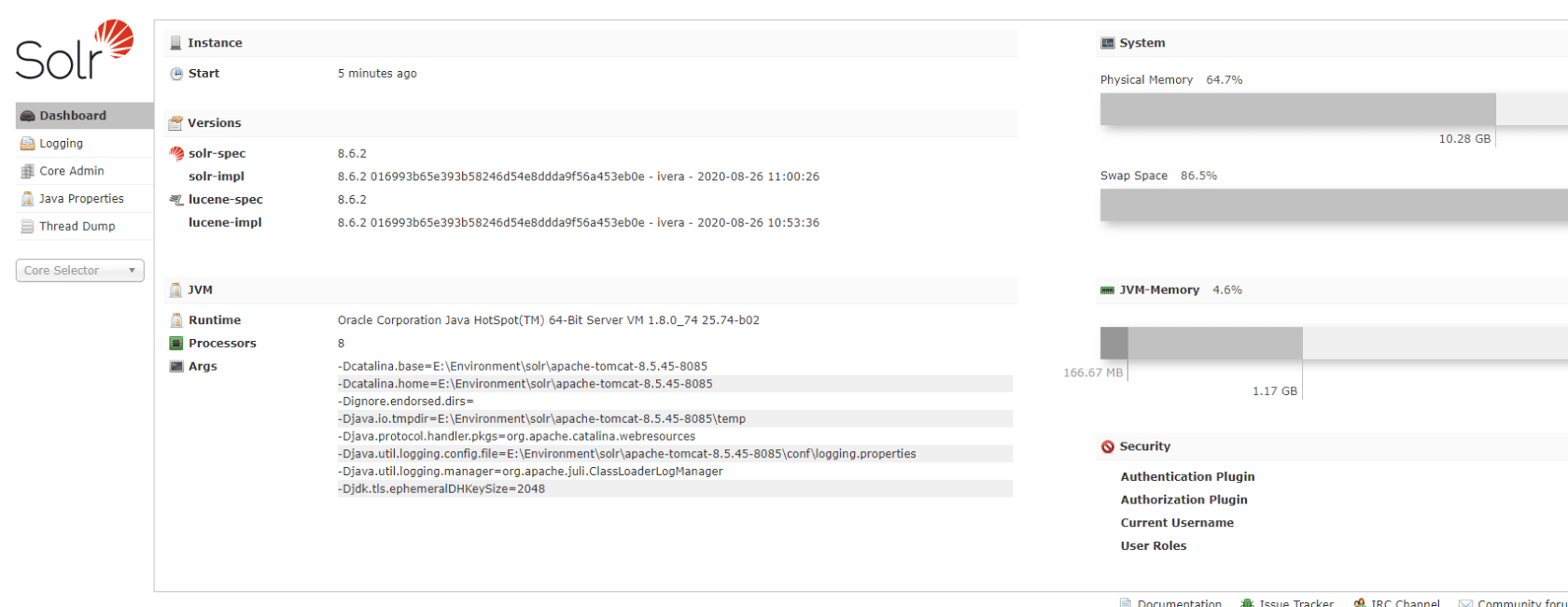
Dashboard:仪表盘,显示了该 solr 实例开始启动运行的时间,版本,系统资源,jvm等信息。Logging:显示 solr 运行出现的异常或错误Core Admin:Solr Core的管理界面,可以添加SolrCore实例。
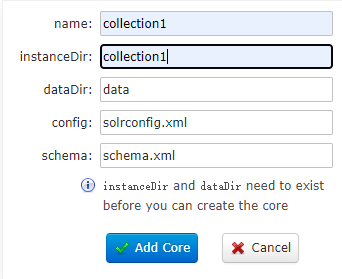
主要有Add Core(添加核心),Unload(卸载和兴),Rename(重命名),Reload(重新加载核心),Optimize(优化索引)
Add Core是添加core:主要是在instanceDir对应的文件夹里生成一个core.properties文件
name:给core起名字
instanceDir:与我们在配置solr到tomcat里时的solrhome里新建的core文件夹名一致
dataDir:确认Add Core时,会在collection1目录下生成名为data的文件夹
config:collection1下的conf下的config配置文件(solrconfig.xml)
schema:collection1下的schema文件(schema.xml)Java Properties:solr在JVM运行环境中的属性信息,包括类路径、文件编码、jvm内存设置等信息。可查看到java相关的一些属性的信息。
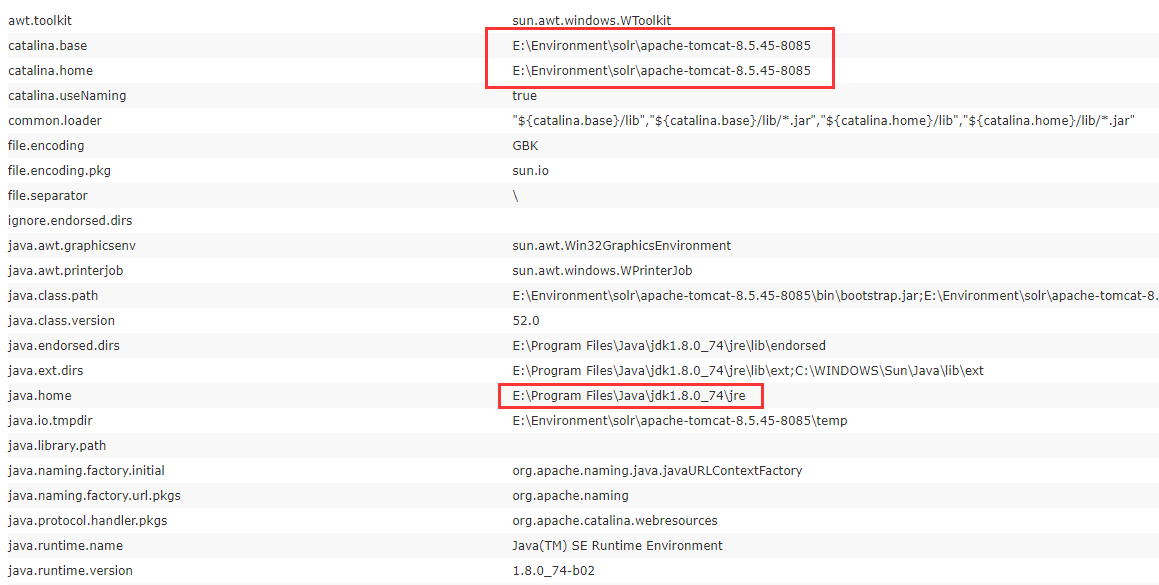
Thread Dump:显示Solr Sever中当前活跃线程信息,同时也可以跟踪线程运行栈信息。Core selector(重点)Analysis(重点):此界面可以测试索引分词器和搜索分词器的执行情况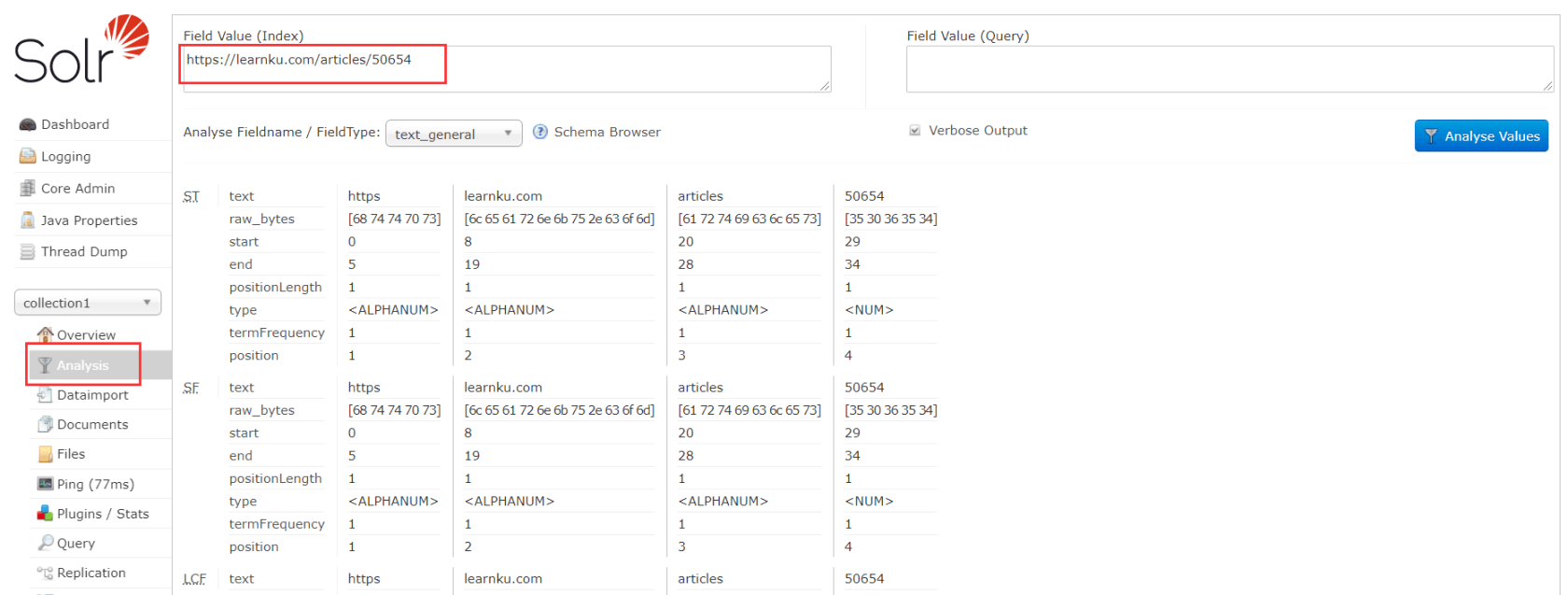
Dataimport:可以定义数据导入处理器,从关系数据库将数据导入到Solr索引库中。默认没有配置,需要手动配置Document:通过/update表示更新索引,solr默认根据id(唯一约束)域来更新Document的内容,如果根据id值搜索不到id域,则会执行添加操作,如果找到则更新,通过此菜单可以创建索引、更新索引、删除索引等操作Query(重点):通过/select执行搜索索引,必须指定“q”查询条件方可搜索。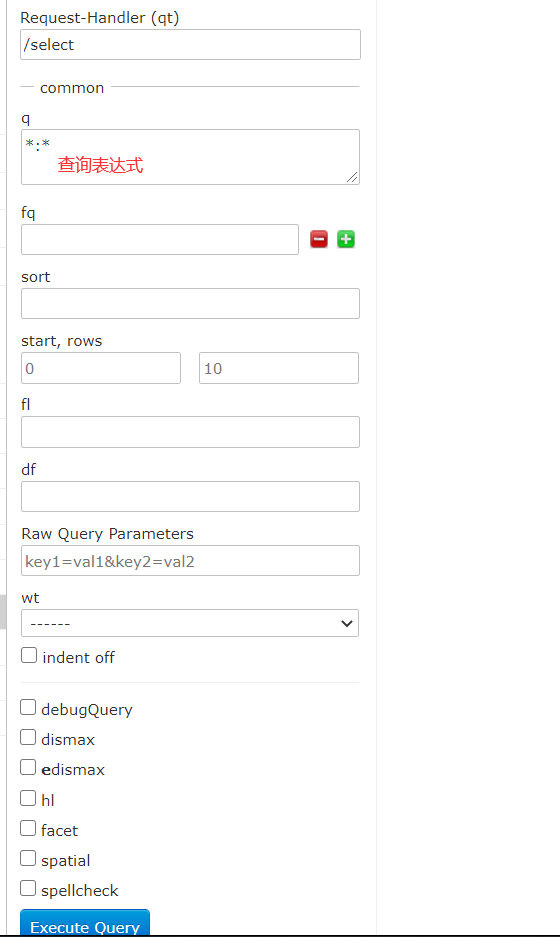
配置中文分词器
配置 solr8 自带分词器
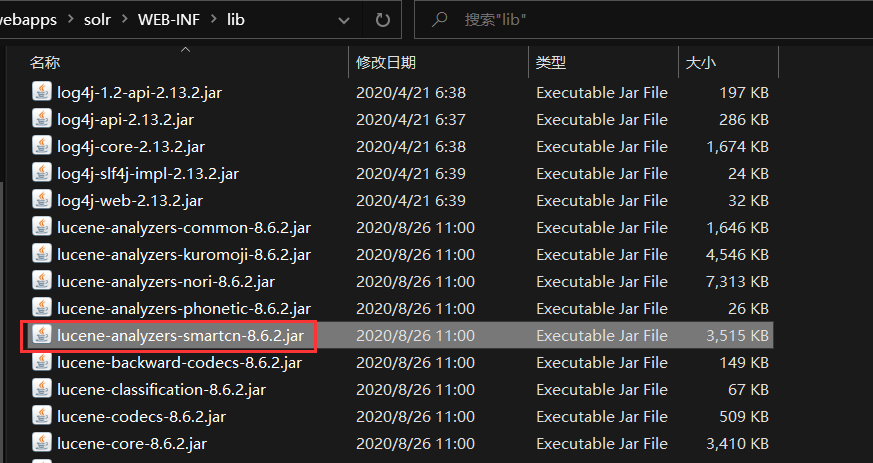
找到solr-8.6.2\contrib\analysis-extras\lucene-libs下的这个jar包,复制到配置的tomcat的webapps\solr\WEB-INF\lib目录下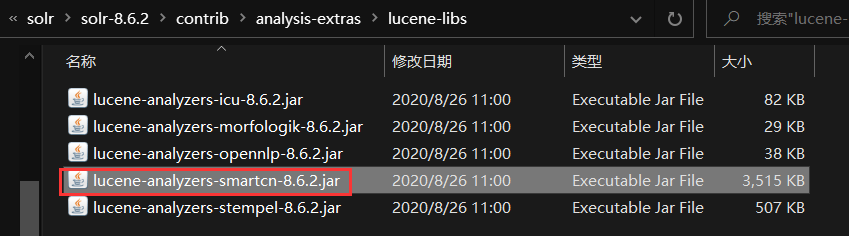
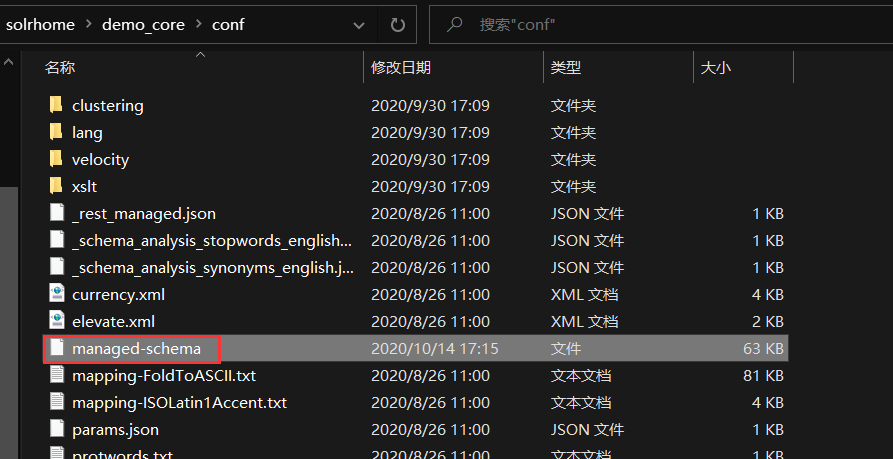
然后配置配置文件,在solrhome的配置的管理员目录下,我这里是solrhome\demo_core\conf目录下的managed-schema文件。
在文件中添加如下配置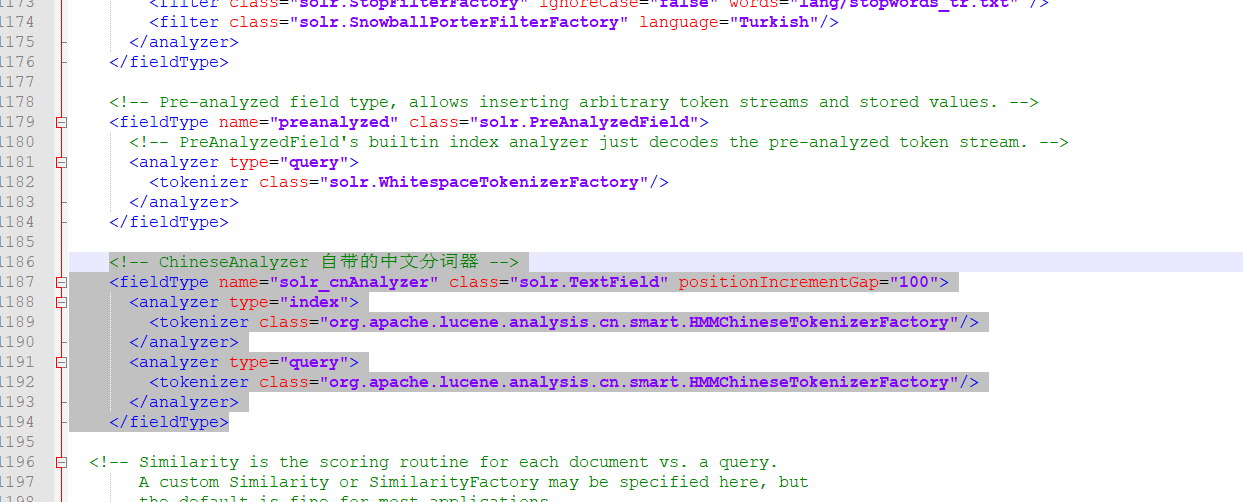
<!-- ChineseAnalyzer 自带的中文分词器 -->
<fieldType name="solr_cnAnalyzer" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/>
</analyzer>
</fieldType>配置ik分词器
先下载solr8版本的ik分词器,下载地址:search.maven.org/search?q=com.gith...
分词器GitHub源码地址:github.com/magese/ik-analyzer-solr
下载jar包

将jar包拷贝到tomcat\webapps\solr\WEB-INF\lib下

然后到solrhome\demo_core\conf目录下配置managed-schema文件
在配置文件中加入以下代码:
<!-- ik分词器 -->
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" conf="ik.conf"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="true" conf="ik.conf"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>测试
启动 solr,测试一下刚刚配置的中文分词器。
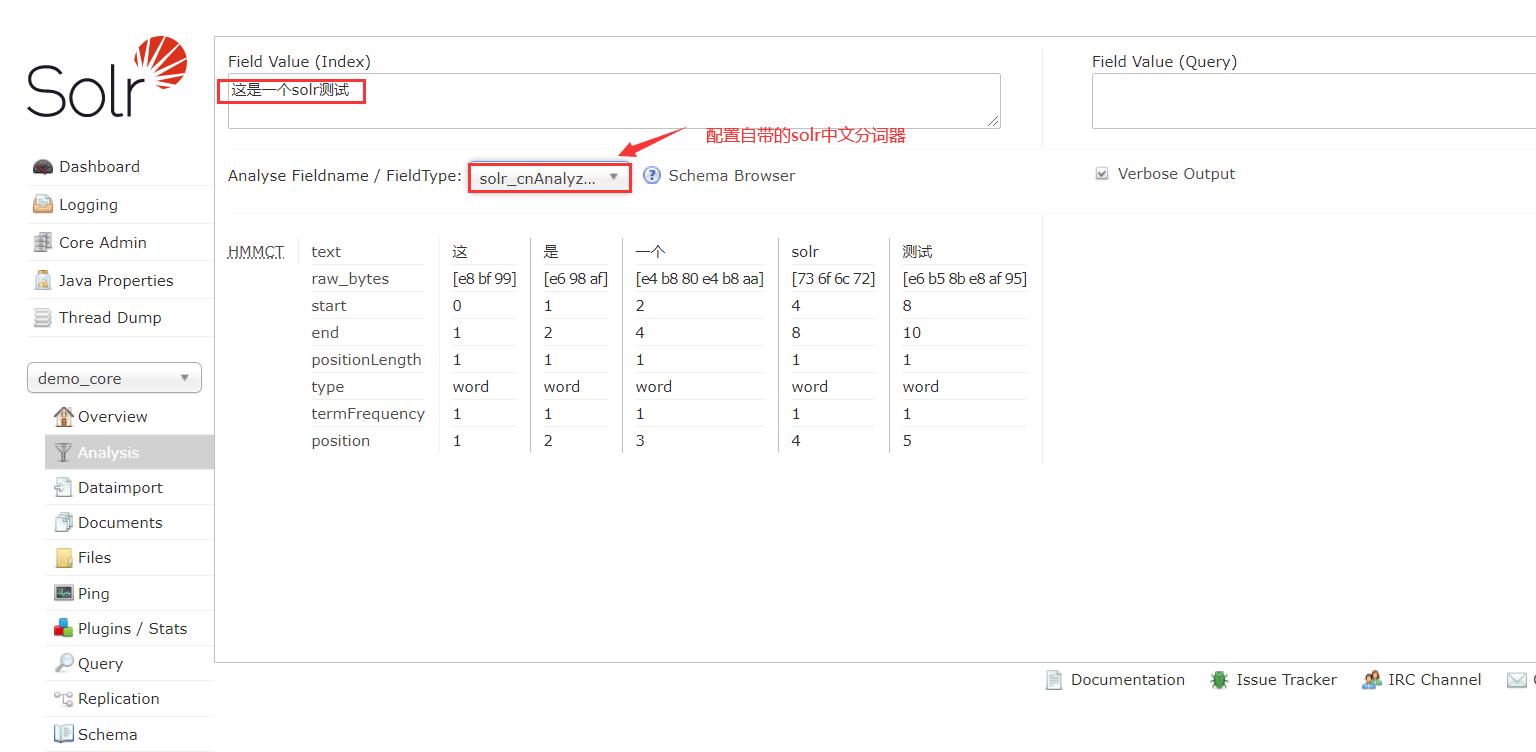
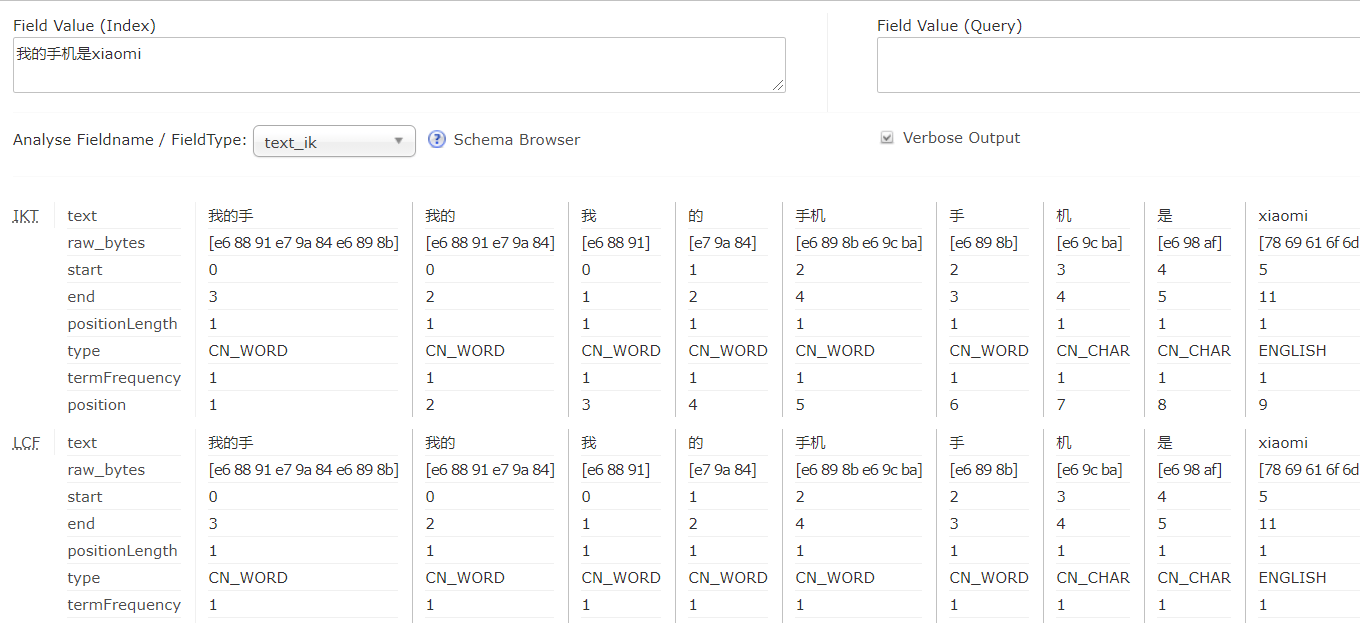
本作品采用《CC 协议》,转载必须注明作者和本文链接






 关于 LearnKu
关于 LearnKu




推荐文章: