
LeetCodet探索——数组与字符串
0 / 0 / 创建于 4年前 /
 okumiko 的个人博客
okumiko 的个人博客
寻找数组的中心索引
给定一个整数类型的数组 nums,请编写一个能够返回数组 “中心索引” 的方法。
我们是这样定义数组 中心索引 的:数组中心索引的左侧所有元素相加的和等于右侧所有元素相加的和。
如果数组不存在中心索引,那么我们应该返回 -1。如果数组有多个中心索引,那么我们应该返回最靠近左边的那一个。
示例 1:
输入:
nums = [1, 7, 3, 6, 5, 6]
输出:3
解释:
索引 3 (nums[3] = 6) 的左侧数之和 (1 + 7 + 3 = 11),与右侧数之和 (5 + 6 = 11) 相等。
同时, 3 也是第一个符合要求的中心索引。
示例 2:
输入:
nums = [1, 2, 3]
输出:-1
解释:
数组中不存在满足此条件的中心索引。
说明:
nums的长度范围为[0, 10000]。- 任何一个
nums[i]将会是一个范围在[-1000, 1000]的整数。
方法:前缀和
唯一要思考的地方是如何减少计算量,如果每一个中心时都要左右全部计算sum一次会超时,观察中间游标i的移动,当我们知道元素总和与i左侧元素的和时,右边元素的和用减法就能得到,无需再次循环计算。
算法:
S是数组的和,当索引i是中心索引时,位于i左边数组元素的和leftsum满足S - nums[i] - leftsum。- 我们只需要判断当前索引
i是否满足leftsum==S-nums[i]-leftsum并动态计算leftsum的值。
class Solution {
public:
int pivotIndex(vector<int>& nums) {
int S=accumulate(nums.begin(),nums.end(),0);
for(int i=0,leftsum=0;i<nums.size();i++ ){
if(leftsum==S-nums[i]-leftsum)return i;
leftsum=sum+nums[i];
}
return -1;
}
};这个题比较奇怪,中心索引可以取到边界,所以要先判断再求和。因为leftsum可以没有元素,但最多有nums.size()-1个元素相加。
复杂度分析
- 时间复杂度:O(N)O(N),其中 NN 是
nums的长度。 - 空间复杂度:O(1)O(1),使用了
S和leftsum。
accumulate函数
accumulate定义在#include<numeric>中,作用有两个,一个是累加求和,另一个是自定义类型数据的处理。accumulate带有三个形参:头两个形参指定要累加的元素范围,第三个形参则是累加的初值。accumulate函数将它的一个内部变量设置为指定的初始值,然后在此初值上累加输入范围内所有元素的值。accumulate算法返回累加的结果,其返回类型就是其第三个实参的类型。
搜索插入位置
搜索插入位置
给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引。如果目标值不存在于数组中,返回它将会被按顺序插入的位置。你可以假设数组中无重复元素。
示例 1:
输入: [1,3,5,6], 5
输出: 2
示例 2:
输入: [1,3,5,6], 2
输出: 1
示例 3:
输入: [1,3,5,6], 7
输出: 4
示例 4:
输入: [1,3,5,6], 0
输出: 0
思路2:在循环体内部排除元素( leetcode-cn.com/problems/search-in... 转自@liweiwei1419)
while(left < right)这种写法表示在循环体内部排除元素;- 退出循环的时候
left和right重合,区间[left, right]只剩下 1 个元素,这个元素 有可能 就是我们要找的元素。

第 2 种思路可以归纳为「左右边界向中间走,两边夹」,这种思路在解决复杂问题的时候,可以使得思考的过程变得简单。
思路分析:
首先,插入位置有可能在数组的末尾(题目中的示例 3),需要单独判断。如果在数组的末尾,插入位置的下标就是数组的长度;
否则,根据示例和暴力解法的分析,插入位置的下标是 大于等于 target 的第 11 个元素的位置。
因此,严格小于 target 的元素一定不是解,在循环体中将左右边界 left 和 right 逐渐向中间靠拢,最后 left 和 right 相遇,则找到了插入元素的位置。根据这个思路,可以写出如下代码。
class Solution {
public:
int searchInsert(vector<int> &nums, int target) {
int size = nums.size();
if (size == 0) {
return 0;
}
// 特判
if (nums[size - 1] < target) {
return size;
}
int left = 0;
int right = size - 1;
while (left < right) {
int mid = left + (right - left) / 2;
// 严格小于 target 的元素一定不是解
if (nums[mid] < target) {
// 下一轮搜索区间是 [mid + 1, right]
left = mid + 1;
} else {
// 下一轮搜索区间是 [left, mid]
right = mid;
}
}
return left;
}
};
我自己的思考:
当最后剩两个元素时,mid就是left。若target<=nums[mid],那么缩小区间为[left,legt],若left是要找的,则返回left就是所需的,若不是要找的,因为left所在的元素是大于等于target的,所以要插入的位置就是left。若target>nums[mid],则缩小区间为[right,right],若right是要找的,则返回right就是所需的,若不是要找的,怎么能保证right所在元素一定大于等于target呢?因为一开始对nums数组的末端元素进行了判断,所以target一定是小于等于末端元素的。当这最后两个元素区间是末端两个自然满足,而当是中间的元素时,再缩进到两个元素前,有满足target小于nums[mid],而缩进区间后mid变为right,也就是target一定小于缩进区间后的right,所以返回的right就是要插入的位置。
复杂度分析:
- 时间复杂度:O(\log N)O(logN),这里 NN 是数组的长度,每一次都将问题的规模缩减为原来的一半,因此时间复杂度是对数级别的;
- 空间复杂度:O(1)O(1),使用到常数个临时变量。
合并区间
给出一个区间的集合,请合并所有重叠的区间。
示例 1:
输入: intervals = [[1,3],[2,6],[8,10],[15,18]]
输出: [[1,6],[8,10],[15,18]]
解释: 区间 [1,3] 和 [2,6] 重叠, 将它们合并为 [1,6].
示例 2:
输入: intervals = [[1,4],[4,5]]
输出: [[1,5]]
解释: 区间 [1,4] 和 [4,5] 可被视为重叠区间。
注意:输入类型已于2019年4月15日更改。 请重置默认代码定义以获取新方法签名。
提示:
- intervals[i][0] <= intervals[i][1]
方法一:排序
思路
如果我们按照区间的左端点排序,那么在排完序的列表中,可以合并的区间一定是连续的。如下图所示,标记为蓝色、黄色和绿色的区间分别可以合并成一个大区间,它们在排完序的列表中是连续的:
算法
我们用数组 merged 存储最终的答案。
首先,我们将列表中的区间按照左端点升序排序。然后我们将第一个区间加入 merged 数组中,并按顺序依次考虑之后的每个区间:
如果当前区间的左端点在数组 merged 中最后一个区间的右端点之后,那么它们不会重合,我们可以直接将这个区间加入数组 merged 的末尾;
否则,它们重合,我们需要用当前区间的右端点更新数组 merged 中最后一个区间的右端点,将其置为二者的较大值。
class Solution {
public:
vector<vector<int>> merge(vector<vector<int>>& intervals) {
if (intervals.size() == 0) {
return {};
}
sort(intervals.begin(), intervals.end());
vector<vector<int>> merged;
for (int i = 0; i < intervals.size(); ++i) {
int L = intervals[i][0], R = intervals[i][1];
if (!merged.size() || merged.back()[1] < L) {
merged.push_back({L, R});
}
else {
merged.back()[1] = max(merged.back()[1], R);
}
}
return merged;
}
};总结:
- 没有对空的vector进行判断而溢出错误,对每道题应该都进行空判,因为返回类型是vector,所以
return {}; - 排序vector只是保证了每个元素左端是从小到大的,而右端可能不是,比如[1,3]和[2,4],合并后应该是[1,4],所以右端应该是取
max(merged.back()[1], R)。 - 题解里直接在if里加入或条件
!merged.size(),相当于在merged为空时对他第一次填充,免去了在外面进行第一步的操作,更简洁。 sort(intervals.begin(), intervals.end());,sort函数对于二维数组,默认是按第一列进行行排列的。`
旋转矩阵
给你一幅由 N × N 矩阵表示的图像,其中每个像素的大小为 4 字节。请你设计一种算法,将图像旋转 90 度。
不占用额外内存空间能否做到?
示例 1:
给定 matrix =
[
[1,2,3],
[4,5,6],
[7,8,9]
],原地旋转输入矩阵,使其变为:
[
[7,4,1],
[8,5,2],
[9,6,3]
]
示例 2:
给定 matrix =
[
[ 5, 1, 9,11],
[ 2, 4, 8,10],
[13, 3, 6, 7],
[15,14,12,16]
],原地旋转输入矩阵,使其变为:
[
[15,13, 2, 5],
[14, 3, 4, 1],
[12, 6, 8, 9],
[16, 7,10,11]
]
解法1:原地旋转
class Solution {
public:
void rotate(vector<vector<int>>& matrix) {
int n=matrix.size();
for(int i=0;i<n/2;i++){
for(int j=i;j<n-1-i;j++){
int temp=matrix[i][j];
matrix[i][j]=matrix[n-1-j][i];
matrix[n-1-j][i]=matrix[n-1-i][n-1-j];
matrix[n-1-i][n-1-j]=matrix[j][n-1-i];
matrix[j][n-1-i]=temp;
}
}
}
};解法2:用翻转代替旋转
我们还可以另辟蹊径,用翻转操作代替旋转操作。
class Solution {
public:
void rotate(vector<vector<int>>& matrix) {
int n = matrix.size();
// 水平翻转
for (int i = 0; i < n / 2; ++i) {
for (int j = 0; j < n; ++j) {
swap(matrix[i][j], matrix[n - i - 1][j]);
}
}
// 主对角线翻转
for (int i = 0; i < n; ++i) {
for (int j = 0; j < i; ++j) {
swap(matrix[i][j], matrix[j][i]);
}
}
}
};零矩阵
编写一种算法,若M × N矩阵中某个元素为0,则将其所在的行与列清零。
示例 1:
输入:
[
[1,1,1],
[1,0,1],
[1,1,1]
]
输出:
[
[1,0,1],
[0,0,0],
[1,0,1]
]
示例 2:
输入:
[
[0,1,2,0],
[3,4,5,2],
[1,3,1,5]
]
输出:
[
[0,0,0,0],
[0,4,5,0],
[0,3,1,0]
]
解法:
- 首先,不能遍历到有0就将它所在的行与列置0,因为会改变还未遍历到的元素。
- 其次,可能会想到用一个容器去记录元素为0位置的下标,对二维数组遍历完后再根据记录值去依次置0。但是这个题目原题其实是要求O(1)空间复杂度的,所以不能另外开辟空间。
- 但是,记录位置数据是难免的,所以考虑用数组内部空间来记录。因为置零操作是按行和按列进行的,第0行有所有列数的标号,第0列有所有行数的标号。所以只要把第0行与第0列用来记录某一行或某一列是否应该置零就行了。而因为把第0行与第0列作为记录数组了,所以他们中是否有0元素应在一开始就记录,用两个布尔变量记录。
class Solution {
public:
void setZeroes(vector<vector<int>> &matrix) {
int m = matrix.size();
int n = matrix[0].size();
if (m == 0 || n == 0) return; //0矩阵则直接返回
bool row = false, col = false; //row和col分别记录第0行与第0列是否需要全部置0
for (int i = 0; i < m; ++i) {
for (int j = 0; j < n; ++j) {
if (matrix[i][j] == 0) { //将十字阵与第0行和第0列的交叉元素置为0
matrix[i][0] = 0; //哪一行置0记录在第0列中
matrix[0][j] = 0; //哪一列置0记录在第0行中
if (i == 0) row = true; //如果第0行有0元素,那么第0行应该全部置0
if (j == 0) col = true; //如果第0列有0元素,那么第0列应该全部置0
}
}
}
//对有0的行清零
//因为第0行已经作为标记数组了,并非原来的数据,并且也用row记录了,所以从1开始循环
for (int i = 1; i < m; ++i) {
if (matrix[i][0] == 0) { //第0列每个i行都应该清零
for (int j = 1; j < n; ++j) { //这里j代表列,遍历列清零
matrix[i][j] = 0;
}
}
}
//对有0的列清零
//因为第0列已经作为标记数组了,并非原来的数据,并且也用col记录了,所以从1开始循环
for (int i = 1; i < n; ++i) {
if (matrix[0][i] == 0) { //第0行每个i列都应该清零
for (int j = 1; j < m; ++j) { //注意这里j是代表行,遍历行清零
matrix[j][i] = 0; //所以这里应该是matrix[j][i] 一开始结果错的原因
}
}
}
//最后根据row与col判断第0行与第0列是否全部置零,若不用,作为记录数组时也完成了置0的工作
if (row) {//第0行应该置零
for (int i = 0; i < n; ++i) {
matrix[0][i] = 0;
}
}
if (col) { //第0列应该置零
for (int i = 0; i < m; ++i) {
matrix[i][0] = 0;
}
}
}
};对角线遍历
给定一个含有 M x N 个元素的矩阵(M 行,N 列),请以对角线遍历的顺序返回这个矩阵中的所有元素,对角线遍历如下图所示。
示例:
输入:
[
[ 1, 2, 3 ],
[ 4, 5, 6 ],
[ 7, 8, 9 ]
]输出: [1,2,4,7,5,3,6,8,9]
解释:

说明:
- 给定矩阵中的元素总数不会超过 100000 。
题解:
- 因为每次遍历个数不一样,所以考虑用
while判断遍历条件,当超出矩阵边界后就停止遍历。 ↗和↙遍历主要是起点不一样,一个呈现L型,一个呈现7型。L的转折条件是行坐标达到m-1,所以↗遍历行坐标主动,列坐标用不变的和去减。7的转折条件是列坐标达到n-1,所以↙遍历列坐标主动,行坐标用不变的和去减。- 可以找规律知道,每个斜对角线元素的行坐标+列坐标不变,自然联想到用这个做
for循环。
class Solution {
public:
vector<int> findDiagonalOrder(vector<vector<int>> &matrix) {
vector<int> result;
int m = matrix.size();
if (m == 0)return result; //因为下面使用了行索引,所以必须要先对行进行空判,空矩阵没有行,会报错
int n = matrix[0].size();
if (n == 0)return result; //若外一维数组存在,但里面每个元素都是空也应该返回空
bool direction = 1; //1表示↗遍历
for (int i = 0; i < m + n - 1; ++i) {
if (direction == 1) {
int x = i < m ? i : m - 1; //起点行数,呈现L型,一开始逐渐增加,到最大后不变
int y = i - x; //起点列数,呈现L型,横纵坐标和不变,直接减就行
while (x >= 0 && y <= n - 1) { //↗遍历运行标志,x和y都不能超过边界
result.push_back(matrix[x--][y++]);
}
} else { //0表示↙遍历
int y = i < n ? i : n - 1; //起点列数,呈现7型,一开始逐渐增加,到最大后不变
int x = i - y; //起点列数,呈现7型,横纵坐标和不变,直接减就行
while (y >= 0 && x <= m - 1) { //↙遍历运行标志,x和y都不能超过边界
result.push_back(matrix[x++][y--]);
}
}
direction = !direction; //每次循环都将方向调转
}
return result;
}
};最长公共前缀
编写一个函数来查找字符串数组中的最长公共前缀。
如果不存在公共前缀,返回空字符串 ""。
示例 1:
输入: [“flower”,”flow”,”flight”]
输出: “fl”
示例 2:
输入: [“dog”,”racecar”,”car”]
输出: “”
解释: 输入不存在公共前缀。
说明:
所有输入只包含小写字母 a-z 。
方法一:横向扫描
依次遍历字符串数组中的每个字符串,对于每个遍历到的字符串,更新最长公共前缀,当遍历完所有的字符串以后,即可得到字符串数组中的最长公共前缀。
先比较1、2,得到的结果再与3比较,依次类推。所以定义一个比较两个字符串的函数。每次调用它,共调用n-1次。
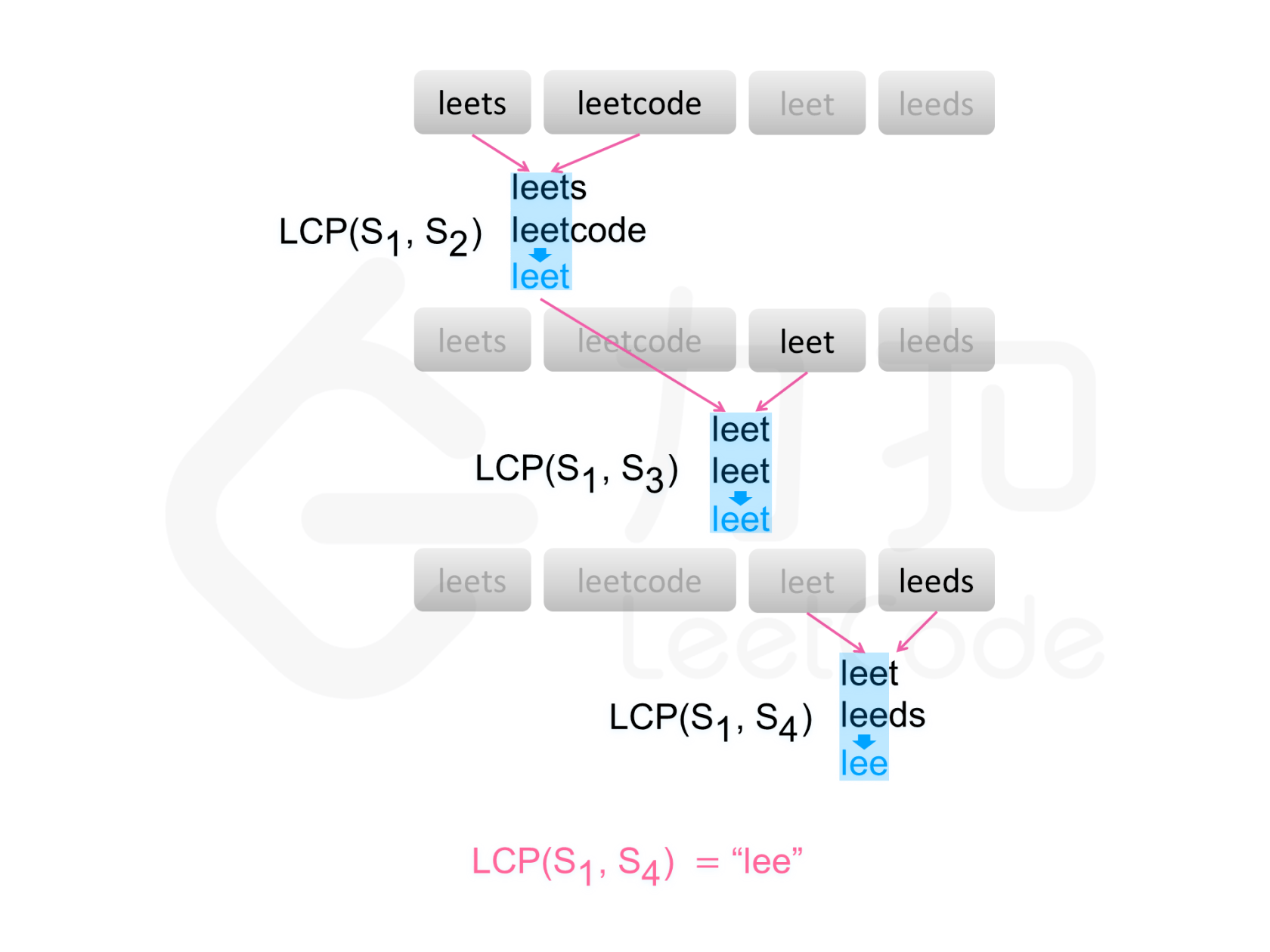
如果在尚未遍历完所有的字符串时,最长公共前缀已经是空串,则最长公共前缀一定是空串,因此不需要继续遍历剩下的字符串,直接返回空串即可。break出循环。
class Solution {
public:
string longestCommonPrefix(vector<string> &strs) {
int num = strs.size();
if (num == 0)return "";
string result = strs[0];
for (int i = 1; i < num; ++i) {
result = longestCommonPrefix(result, strs[i]);
if (!result.length()) break;
}
return result;
}
string longestCommonPrefix(const string &s1, const string &s2) {
int len = min(s1.length(), s2.length());
int index = 0;
while (index < len && s1[index] == s2[index]) ++index;
return s1.substr(0, index);
}
};复杂度分析
- 时间复杂度:O(mn)O(mn),其中 mm 是字符串数组中的字符串的平均长度,nn 是字符串的数量。最坏情况下,字符串数组中的每个字符串的每个字符都会被比较一次。
- 空间复杂度:O(1)O(1)。使用的额外空间复杂度为常数。
方法二:纵向扫描
方法一是横向扫描,依次遍历每个字符串,更新最长公共前缀。另一种方法是纵向扫描。纵向扫描时,从前往后遍历所有字符串的每一列,比较相同列上的字符是否相同,如果相同则继续对下一列进行比较,如果不相同则当前列不再属于公共前缀,当前列之前的部分为最长公共前缀。
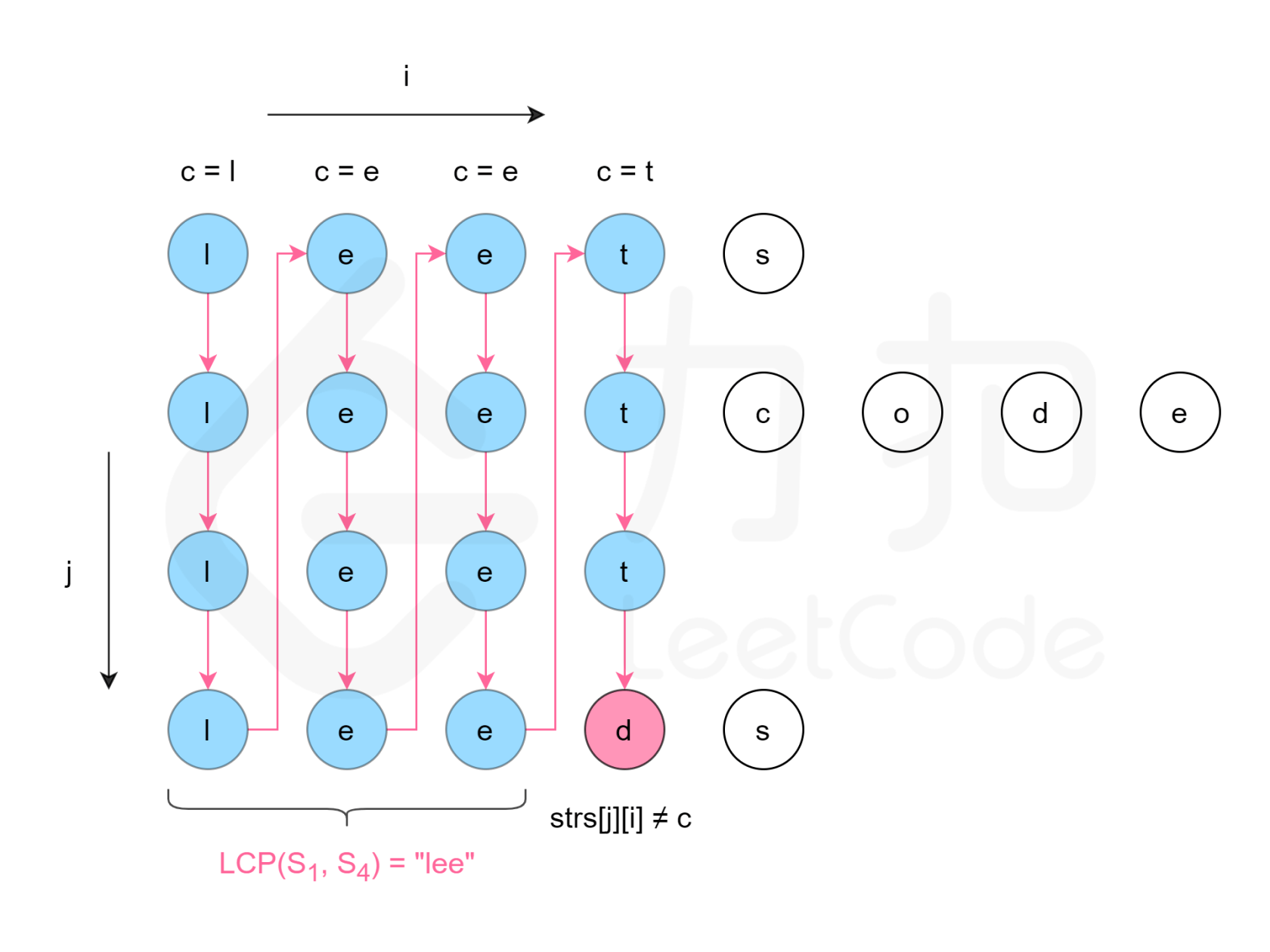
- 把第
0个字符串作为参考,最多遍历它的长度,每次遍历第i位,内循环遍历所有字符串。如果碰到有字符串的长度等于i,说明它是最短的字符串,直接输出第0个字符串前i长度的部分。如果碰到有字符串i位和第0个字符串i位不等,也直接输出第0个字符串前i长度的部分。这里补充说明下:因为前i长度的比较是在上轮完成的,对应的是i-1位。 string.substr(a,b)是指从第a位开始,选取b位复制,返回子字符串。默认a为0。如果没有指定长度或超出了源字符串的长度,则子字符串将延续到源字符串的结尾。
string longestCommonPrefix(vector<string> &strs) {
int num = strs.size();
if (num == 0)return "";
int len = strs[0].length();
for (int i = 0; i < len; ++i) {
char c = strs[0][i];
for (int j = 1; j < num; ++j) {
if (strs[j].length() == i || strs[j][i] != c) return strs[0].substr(0, i);
}
}
return strs[0];
}复杂度分析
- 时间复杂度:O(mn)O(mn),其中 mm 是字符串数组中的字符串的平均长度,nn 是字符串的数量。最坏情况下,字符串数组中的每个字符串的每个字符都会被比较一次。
- 空间复杂度:O(1)O(1)。使用的额外空间复杂度为常数。
方法三:分治
找最长公共前缀和找最小的数差不多,所以可以用分治思想,先分成n个1,再两两比较归并找到最长公共前缀。
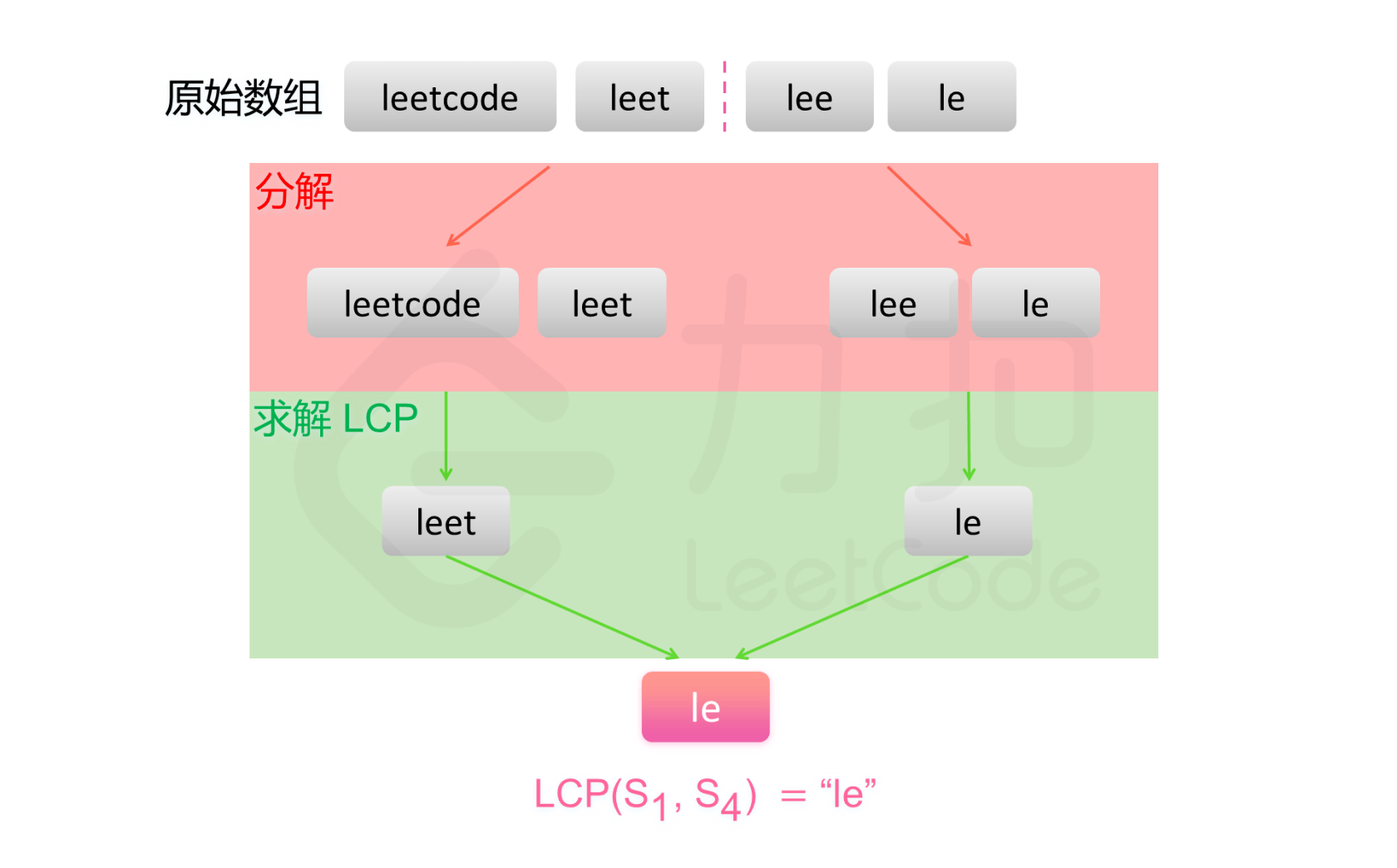
class Solution {
public:
string longestCommonPrefix(vector<string> &strs) {
if (!strs.size()) {
return "";
} else {
return longestCommonPrefix(strs, 0, strs.size() - 1);
}
}
string longestCommonPrefix(const vector<string> &strs, int start, int end) {
if (start == end) {
return strs[start]; //递归终止条件:分成了一份一个数
} else {
int mid = (start + end) / 2;
string lcpLeft = longestCommonPrefix(strs, start, mid);
string lcpRight = longestCommonPrefix(strs, mid + 1, end);
return commonPrefix(lcpLeft, lcpRight); //两两归并
}
}
string commonPrefix(const string &lcpLeft, const string &lcpRight) {
int minLength = min(lcpLeft.size(), lcpRight.size());
for (int i = 0; i < minLength; ++i) {
if (lcpLeft[i] != lcpRight[i]) { //第i位不一样,返回0到i-1共i位
return lcpLeft.substr(0, i);
}
}
return lcpLeft.substr(0, minLength); //一个字符串是另一个的子串
}
};复杂度分析:
时间复杂度:O(mn)O(mn),其中 m 是字符串数组中的字符串的平均长度,n 是字符串的数量。时间复杂度的递推式是 T(n)=2⋅T(\frac{n}{2})+O(m),通过计算可得T(n)=O(nm)
空间复杂度:O(m \log n),其中 m 是字符串数组中的字符串的平均长度,n 是字符串的数量。空间复杂度主要取决于递归调用的层数,层数最大为 \log n,每层需要 m 的空间存储返回结果。
方法四:二分查找
显然,最长公共前缀的长度不会超过字符串数组中的最短字符串的长度。用 minLength 表示字符串数组中的最短字符串的长度,则可以在 [0,minLength] 的范围内通过二分查找得到最长公共前缀的长度。每次取查找范围的中间值 mid ,判断每个字符串的长度为mid 的前缀是否相同,如果相同则最长公共前缀的长度一定大于或等于 mid,如果不相同则最长公共前缀的长度一定小于 mid,通过上述方式将查找范围缩小一半,直到得到最长公共前缀的长度。
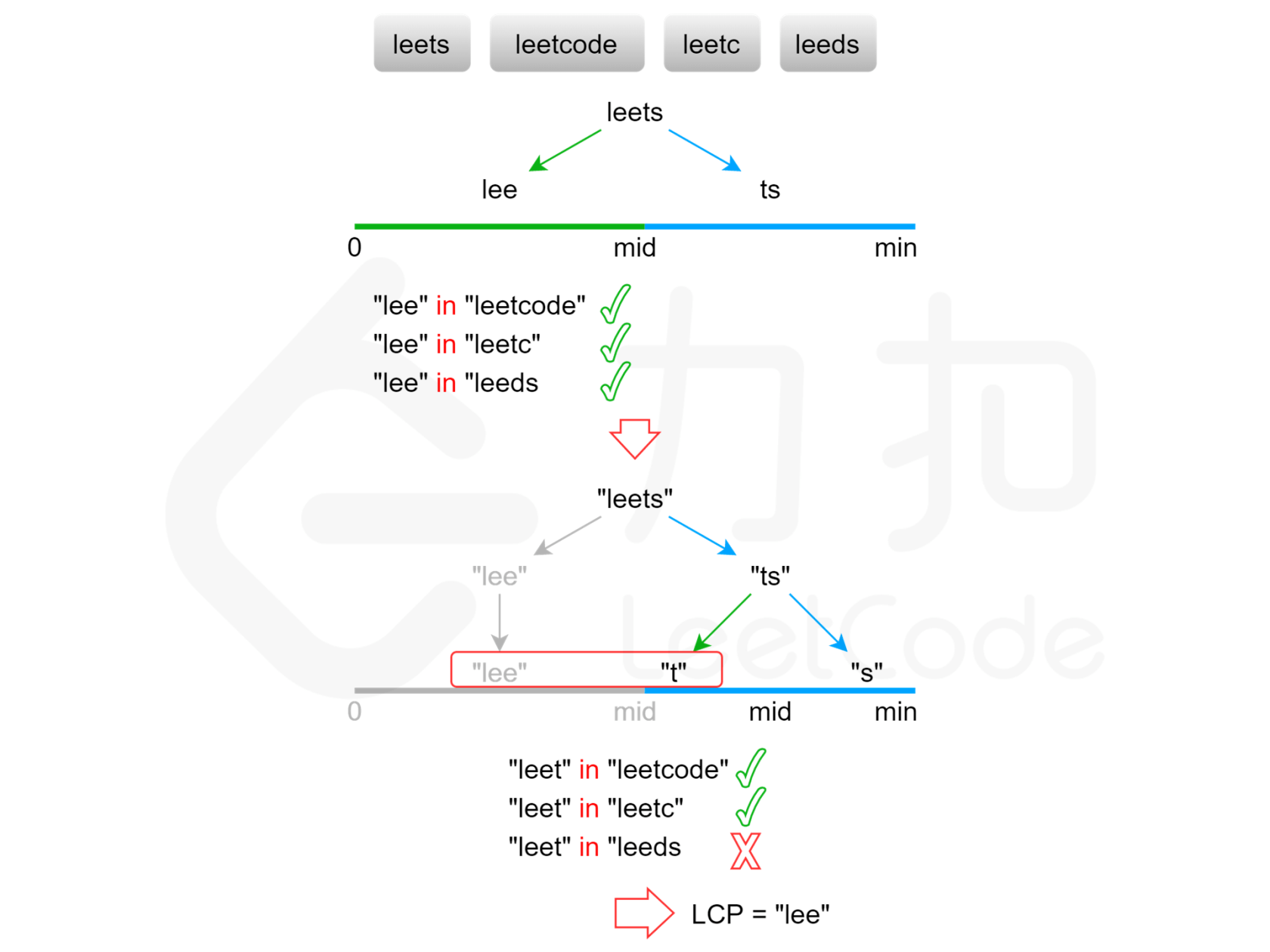
class Solution4 {
public:
string longestCommonPrefix(vector<string> &strs) {
if (!strs.size()) {
return "";
}
int minLength = min_element(strs.begin(), strs.end(), [](const string &s, const string &t) { return s.size() < t.size(); })->size();
int low = 0, high = minLength;
while (low < high) {
int mid = (high - low + 1) / 2 + low;
if (isCommonPrefix(strs, mid)) {
low = mid;
} else {
high = mid - 1;
}
}
return strs[0].substr(0, low);
}
bool isCommonPrefix(const vector<string> &strs, int length) {
string str0 = strs[0].substr(0, length);
int count = strs.size();
for (int i = 1; i < count; ++i) {
string str = strs[i];
for (int j = 0; j < length; ++j) {
if (str0[j] != str[j]) {
return false;
}
}
}
return true;
}
};string类型的两个方法
- begin
方法:begin();
解释:begin()函数返回一个迭代器,指向字符串的第一个元素. - end
方法:end();
解释:end()函数返回一个迭代器,指向字符串的末尾(最后一个字符的下一个位置).
min_element
头文件algorithm
default (1)
template <class ForwardIterator>
ForwardIterator min_element (ForwardIterator first, ForwardIterator last);
custom (2)
template <class ForwardIterator, class Compare>
ForwardIterator min_element (ForwardIterator first, ForwardIterator last, Compare comp);
返回范围内的最小元素
返回指向范围[first,last)中具有最小值的元素的迭代器。
比较是使用operator <作为第一个版本,或comp作为第二个版本; 如果没有其他元素比它少,则元素是最小的。 如果多个元素满足此条件,则迭代器返回指向第一个这样的元素。
此函数模板的行为等效于:
template <class ForwardIterator>
ForwardIterator min_element ( ForwardIterator first, ForwardIterator last )
{
if (first==last) return last;
ForwardIterator smallest = first;
while (++first!=last)
if (*first<*smallest) // or: if (comp(*first,*smallest)) for version (2)
smallest=first;
return smallest;
}参数
- fisrt,last
将迭代器输入到要比较的序列的初始和最终位置。 使用的范围是[first,last),它包含first和last之间的所有元素,包括first指向的元素,但不包括last指向的元素。 - comp
二进制函数,接受范围中的两个元素作为参数,并返回可转换为bool的值。 返回的值指示作为第一个参数传递的元素是否小于第二个参数。
该函数不得修改其任何参数。这可以是函数指针或函数对象。
返回值
迭代器到范围中的最小值,如果范围为空则为last。
#include <iostream>
#include <algorithm>
#include <string>
#include <vector>
using namespace std;
bool cmp(int a, int b)
{
return a < b;
}
int main()
{
vector<int> ints = {5, 3, 90, 32, 24, 56, 98, 54, 76, 45, 89, 100};
auto min_iterator = min_element(ints.begin(), ints.end(), cmp);
cout << *min_iterator << endl; //输出为 3 ,此时的min_iterator为迭代器,需要解引用才能获得最小值
return 0;
}
//--------------------------------------------------------------
//当然,这个比较函数(cmp)也可以直接用无名函数代替,如下代码所示:
int main()
{
vector<int> ints = {5, 3, 90, 32, 24, 56, 98, 54, 76, 45, 89, 100};
auto min_iterator = min_element(ints.begin(), ints.end(), [](int a, int b)
{
return a < b;
}
);
cout << *min_iterator << endl; //同样输出 3
return 0;
}
//----------------------------------------------------------------
//定义一个学生类
class Student
{
public:
string name_;
int age_;
Student()
{}
Student(string name, int age):
name_(name), age_(age)
{}
};
int main()
{
vector<Student> students;
students.push_back(Student("zhangsan",23));
students.push_back(Student("lisi",20));
students.push_back(Student("wangwu",34));
students.push_back(Student("zhaoliu",27));
students.push_back(Student("jerry",19));
string student_who_has_min_age = min_element(students.begin(), students.end(), [](const Student& s1, const Student& s2)
{
return s1.age_ < s2.age_;
}
)->name_;
cout << student_who_has_min_age << endl; //输出: jerry
return 0;
}
/**
* 上述这段代码的含义是用无名函数取代 cmp,并且取运算出来的符合要求的迭代器的name属性:->name_
*/
}最长回文子串
给定一个字符串 s,找到 s 中最长的回文子串。你可以假设 s 的最大长度为 1000。
示例 1:
输入: “babad”
输出: “bab”
注意: “aba” 也是一个有效答案。
示例 2:
输入: “cbbd”
输出: “bb”
方法一:动态规划
思路与算法
对于一个子串而言,如果它是回文串,并且长度大于 22,那么将它首尾的两个字母去除之后,它仍然是个回文串。例如对于字符串“ababa”,如果我们已经知道“bab”是回文串,那么“ababa”一定是回文串,这是因为它的首尾两个字母都是“a”。
根据这样的思路,我们就可以用动态规划的方法解决本题。我们用P(i,j)表示字符串s的第i到第j个字母组成的串,(下文表示成 s[i:j])是否为回文串:
f(n) = \begin{cases} \text{true}, & \text{如果子串}S_i...S_j\text{是回文串} \\ \text{false}, & \text{其它情况} \end{cases}
这里的「其它情况」包含两种可能性:
s[i,j] 本身不是一个回文串;
i>j,此时 s[i,j] 本身不合法。
那么我们就可以写出动态规划的状态转移方程:
P(i,j)=P(i+1,j−1)∧(S_i==S_j)
也就是说,只有 s[i+1:j−1] 是回文串,并且 s 的第 i 和 j 个字母相同时,s[i:j] 才会是回文串。
上文的所有讨论是建立在子串长度大于 2 的前提之上的,我们还需要考虑动态规划中的边界条件,即子串的长度为 1 或 2。对于长度为 1 的子串,它显然是个回文串;对于长度为 2 的子串,只要它的两个字母相同,它就是一个回文串。因此我们就可以写出动态规划的边界条件:
\begin{cases} P(i,j)=\text{true} \\ P(i,i+1)=(S_i==S_i+1) \end{cases}
根据这个思路,我们就可以完成动态规划了,最终的答案即为所有 P(i,j) = \text{true} 中 j−i+1(即子串长度)的最大值。
注意:在状态转移方程中,我们是从长度较短的字符串向长度较长的字符串进行转移的,因此一定要注意动态规划的循环顺序。
class Solution {
public:
string longestPalindrome(string s) {
int n = s.length();
vector<vector<int> > dp(n, vector<int>(n));
string result;
for (int dlen = 0; dlen < n; ++dlen) {//转移长度最大为n-1
for (int begin = 0; begin + dlen < n; ++begin) {//起点下标加转移长度就是末尾字符的下标,末尾字符下标最大为n-1
if (dlen == 0) {//转移长度为0,就是一个字符的边界情况
dp[begin][begin + dlen] = 1;
} else if (dlen == 1) {//转移长度为1,就是两个字符的边界情况
dp[begin][begin + dlen] = (s[begin] == s[begin + dlen]);//判断首位字符是否相等
} else {//大于两个字符的情况,用之前的记录解决
dp[begin][begin + dlen] = (dp[begin + 1][begin + dlen - 1] && (s[begin] == s[begin + dlen]));
}
if (dp[begin][begin + dlen] && dlen + 1 > result.size()) result = s.substr(begin, dlen + 1);
//如果不加长度判断就会超时,因为一样长度的回文子串每次都要重新赋值,加了用时也是倒数。。。
}
}
return result;
}
};这种相当于是先遍历了所有二字符的字串(一字符自然成立,遍历记录为1即可),判断是不是回文然后记录,之后三字符串及以上的用之前的记录判断。
复杂度分析
时间复杂度:O(n^2),其中 n 是字符串的长度。动态规划的状态总数为 O(n^2),对于每个状态,我们需要转移的时间为 O(1)。
空间复杂度:O(n^2),即存储动态规划状态需要的空间。
方法二:中心扩展算法
思路与算法
我们仔细观察一下方法一中的状态转移方程:
\begin{cases} P(i,j)=\text{true} \\ P(i,i+1)=(S_i==S_i+1) \\ P(i,j)=P(i+1,j−1)∧(S_i==S_j) \end{cases}
找出其中的状态转移链:
P(i,j)←P(i+1,j−1)←P(i+2,j−2)←⋯←某一边界情况
可以发现,所有的状态在转移的时候的可能性都是唯一的。也就是说,我们可以从每一种边界情况开始「扩展」,也可以得出所有的状态对应的答案。
边界情况即为子串长度为 1 或 2 的情况。我们枚举每一种边界情况,并从对应的子串开始不断地向两边扩展。如果两边的字母相同,我们就可以继续扩展,例如从 P(i+1,j−1) 扩展到 P(i,j);如果两边的字母不同,我们就可以停止扩展,因为在这之后的子串都不能是回文串了。
聪明的读者此时应该可以发现,「边界情况」对应的子串实际上就是我们「扩展」出的回文串的「回文中心」。方法二的本质即为:我们枚举所有的「回文中心」并尝试「扩展」,直到无法扩展为止,此时的回文串长度即为此「回文中心」下的最长回文串长度。我们对所有的长度求出最大值,即可得到最终的答案。
class Solution1 {
public:
pair<int, int> expandAroundCenter(const string &s, int left, int right) {//判断从两个字符开始是否是回文子串
while (left >= 0 && right < s.length() && s[left] == s[right]) {
--left;
++right;
}
return {left + 1, right - 1};
}
string longestPalindrome(string s) {
int begin = 0, end = 0;//注意一定要赋初始值为0,因为局部变量是在栈中,并不是默认为0,
for (int i = 0; i < s.length(); ++i) {//遍历所有中心扩展的初始位置
auto[left1, right1]=expandAroundCenter(s, i, i);//若是以一个字符开始,即奇数回文子串,就令首位相等即可
auto[left2, right2]=expandAroundCenter(s, i, i + 1);
if (right1 - left1 > end - begin) {//记录最大的长度
end = right1;
begin = left1;
}
if (right2 - left2 > end - begin) {//记录最大的长度
end = right2;
begin = left2;
}
}
return s.substr(begin, end - begin + 1);
}
};其实中心扩散更好理解,首先扩散无非两种情况,一个字符开始扩散成奇数个;两个字符开始扩散成偶数个。写一个通用的扩散函数即可,然后找出两种扩散方式里最长的哪个子串输出。
复杂度分析
时间复杂度:O(n^2),其中 n 是字符串的长度。长度为 1 和 2 的回文中心分别有 n 和 n−1 个,每个回文中心最多会向外扩展 O(n) 次。
空间复杂度:O(1)。
- 官方题解用到了标准库中的pair,扩散函数返回的就是两个int的pair类型,并用auto[]自动判断类型赋值俩个变量,否则可能要分别赋值或者先声明一个新的pair变量再赋值,值得学习。下面转载一篇pair的总结文章。
pair
转载自blog.csdn.net/sevenjoin/article/de...
@sevencheng798
pair的应用
pair是将2个数据组合成一组数据,当需要这样的需求时就可以使用pair,如stl中的map就是将key和value放在一起来保存。另一个应用是,当一个函数需要返回2个数据的时候,可以选择pair。 pair的实现是一个结构体,主要的两个成员变量是first second 因为是使用struct不是class,所以可以直接使用pair的成员变量。
其标准库类型–pair类型定义在#include 头文件中,定义如下:
- 类模板:template<class T1,class T2> struct pair
- 参数:T1是第一个值的数据类型,T2是第二个值的数据类型。
- 功能:pair将一对值(T1和T2)组合成一个值,这一对值可以具有不同的数据类型(T1和T2),两个值可以分别用pair的两个公有函数first和second访问。
定义(构造函数):
pair<T1, T2> p1; //创建一个空的pair对象(使用默认构造),它的两个元素分别是T1和T2类型,采用值初始化。
pair<T1, T2> p1(v1, v2); //创建一个pair对象,它的两个元素分别是T1和T2类型,其中first成员初始化为v1,second成员初始化为v2。
make_pair(v1, v2); // 以v1和v2的值创建一个新的pair对象,其元素类型分别是v1和v2的类型。
p1 < p2; // 两个pair对象间的小于运算,其定义遵循字典次序:如 p1.first < p2.first 或者 !(p2.first < p1.first) && (p1.second < p2.second) 则返回true。
p1 == p2; // 如果两个对象的first和second依次相等,则这两个对象相等;该运算使用元素的==操作符。
p1.first; // 返回对象p1中名为first的公有数据成员
p1.second; // 返回对象p1中名为second的公有数据成员pair的创建和初始化
pair包含两个数值,与容器一样,pair也是一种模板类型。但是又与之前介绍的容器不同;
在创建pair对象时,必须提供两个类型名,两个对应的类型名的类型不必相同。
pair<string, string> anon; // 创建一个空对象anon,两个元素类型都是string
pair<string, int> word_count; // 创建一个空对象 word_count, 两个元素类型分别是string和int类型
pair<string, vector<int> > line; // 创建一个空对象line,两个元素类型分别是string和vector类型当然也可以在定义时进行成员初始化:
pair<string, string> author("James","Joy"); // 创建一个author对象,两个元素类型分别为string类型,并默认初始值为James和Joy。
pair<string, int> name_age("Tom", 18);
pair<string, int> name_age2(name_age); // 拷贝构造初始化pair类型的使用相当的繁琐,如果定义多个相同的pair类型对象,可以使用typedef简化声明:
typedef pair<string,string> Author;
Author proust("March","Proust");
Author Joy("James","Joy");变量间赋值:
pair<int, double> p1(1, 1.2);
pair<int, double> p2 = p1; // copy construction to initialize object
pair<int, double> p3;
p3 = p1; // operator =pair对象的操作
访问两个元素操作可以通过first和sencond访问:
pair<int ,double> p1;
p1.first = 1;
p1.second = 2.5;
cout<<p1.first<<' '<<p1.second<<endl;
//输出结果:1 2.5
string firstBook;
if(author.first=="James" && author.second=="Joy")
firstBook="Stephen Hero";生成新的pair对象
还可以利用make_pair创建新的pair对象:
pair<int, double> p1;
p1 = make_pair(1, 1.2);
cout << p1.first << p1.second << endl;
//output: 1 1.2
int a = 8;
string m = "James";
pair<int, string> newone;
newone = make_pair(a, m);
cout << newone.first << newone.second << endl;
//output: 8 James通过tie获取pair元素值
在某些清况函数会以pair对象作为返回值时,可以直接通过std::tie进行接收。比如:
std::pair<std::string, int> getPreson() {
return std::make_pair("Sven", 25);
}
int main(int argc, char **argv) {
std::string name;
int ages;
std::tie(name, ages) = getPreson();
std::cout << "name: " << name << ", ages: " << ages << std::endl;
return 0;
}翻转字符串里的单词
给定一个字符串,逐个翻转字符串中的每个单词。
说明:
- 无空格字符构成一个 单词 。
- 输入字符串可以在前面或者后面包含多余的空格,但是反转后的字符不能包括。
- 如果两个单词间有多余的空格,将反转后单词间的空格减少到只含一个。
示例 1:
输入:“the sky is blue”
输出:“blue is sky the”
示例 2:
输入:“ hello world! “
输出:“world! hello”
解释:输入字符串可以在前面或者后面包含多余的空格,但是反转后的字符不能包括。
示例 3:
输入:“a good example”
输出:“example good a”
解释:如果两个单词间有多余的空格,将反转后单词间的空格减少到只含一个。
示例 4:
输入:s = “ Bob Loves Alice “
输出:“Alice Loves Bob”
示例 5:
输入:s = “Alice does not even like bob”
输出:“bob like even not does Alice”
提示:
- 1 <= s.length <= 10^4
- s 包含英文大小写字母、数字和空格 ‘ ‘
- s 中 至少存在一个 单词
进阶:
- 请尝试使用 O(1) 额外空间复杂度的原地解法。
解法一:两步走
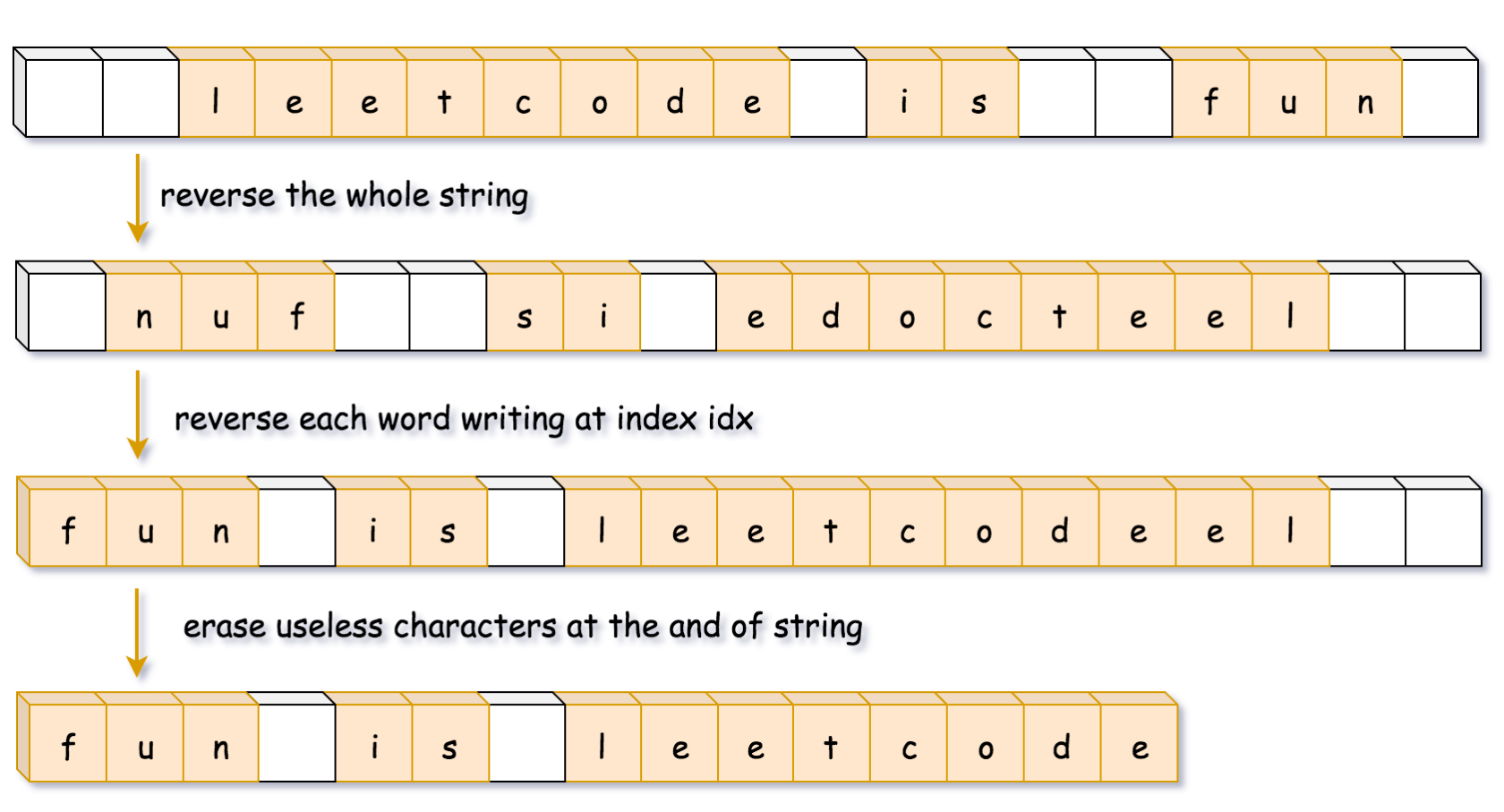
class Solution {
public:
string reverseWords(string s) {
reverse(s.begin(), s.end());
int n = s.length();
int index = 0;//标签,用于标记新字符串每两个单词之间的空白分隔符,初始化为0,第一个单词应该特殊处理
for (int start = 0; start < n; ++start) {
if (s[start] != ' ') {//当遇到非空字符时,说明是一个单词的开始,要开始进行单词平移操作,而此时有两种情况
if (index != 0) {//不为0说明不是是第一个单词,后面的每个单词前面都应该有个空白符,若是第一个单词就不留空白符直接进行平移操作
s[index++] = ' ';//前面说了index是应该留空白符的位置,留完空白指向重排后单词应该在的位置的开头,要向index搬运字母
}//第一个字符或者已经进行留空白操作后进行平移单词操作
int end = start;//因为start指向当前单词第一个字母,后面要进行反转操作,要复制一个变量end进行平移操作
while (s[end] != ' ' && end < n) {// 两种情况,若最后一个单词结尾没有空白字符,根据位置停止,其他情况根据空白符停止
s[index++] = s[end++];//平移操作,进行完后index指向了单词后分隔符位
}
reverse(s.begin() + index - (end - start), s.begin() + index);//end-start为单词长度,index减去后为单词首字母位置
start = end;//start作为记录已经使用完毕,将此时end指向位置再赋给start,这时是指向空白字符的
}
}
s.erase(s.begin() + index, s.end());//前面每次平移完index都指向单词后分隔符,操作完最后一个但此后不会再进if,index不变,擦除后面的空白符,
// 就算没有空白符,那么index和end重合,空集
return s;
}
};reverse()函数
reverse函数功能是逆序(或反转),多用于字符串、数组、容器。头文件是#include <algorithm>reverse函数用于反转在[first,last)范围内的顺序(包括first指向的元素,不包括last指向的元素),reverse函数无返回值
实现 strStr()
反转字符串
编写一个函数,其作用是将输入的字符串反转过来。输入字符串以字符数组 char[] 的形式给出。
不要给另外的数组分配额外的空间,你必须原地修改输入数组、使用 O(1) 的额外空间解决这一问题。
你可以假设数组中的所有字符都是 ASCII 码表中的可打印字符。
示例 1:
输入:[“h”,”e”,”l”,”l”,”o”]
输出:[“o”,”l”,”l”,”e”,”h”]
示例 2:
输入:[“H”,”a”,”n”,”n”,”a”,”h”]
输出:[“h”,”a”,”n”,”n”,”a”,”H”]
双指针
class Solution {
public:
void reverseString(vector<char> &s) {
int left = 0, right = s.size() - 1;//从左端和右端开始
while (left < right) {//终止循环条件:相遇重合或者左超过了右
swap(s[left], s[right]);
++left;
--right;
}
}
};数组拆分I
给定长度为 2n 的整数数组 nums ,你的任务是将这些数分成 n 对, 例如 (a1, b1), (a2, b2), ..., (an, bn) ,使得从 1 到 n 的 min(ai, bi) 总和最大。
返回该 最大总和 。
示例 1:
输入:nums = [1,4,3,2]
输出:4
解释:所有可能的分法(忽略元素顺序)为:
- (1, 4), (2, 3) -> min(1, 4) + min(2, 3) = 1 + 2 = 3
- (1, 3), (2, 4) -> min(1, 3) + min(2, 4) = 1 + 2 = 3
- (1, 2), (3, 4) -> min(1, 2) + min(3, 4) = 1 + 3 = 4
所以最大总和为 4
示例 2:
输入:nums = [6,2,6,5,1,2]
输出:9
解释:最优的分法为 (2, 1), (2, 5), (6, 6). min(2, 1) + min(2, 5) + min(6, 6) = 1 + 2 + 6 = 9
提示:
- 1 <= n <= 104
- nums.length == 2 * n
- -104 <= nums[i] <= 104
算法:排序
为了理解这种方法,让我们从不同的角度来看待问题。我们需要形成数组元素的配对,使得这种配对中最小的总和最大。因此,我们可以查看选择配对中最小值的操作,比如 (a,b) 可能会产生的最大损失 a−b (如果 a > b)。
如果这类配对产生的总损失最小化,那么总金额现在将达到最大值。只有当为配对选择的数字比数组的其他元素更接近彼此时,才有可能将每个配对中的损失最小化。
考虑到这一点,我们可以对给定数组的元素进行排序,并直接按排序顺序形成元素的配对。这将导致元素的配对,它们之间的差异最小,从而导致所需总和的最大化。
很容易想到,最大的数肯定不会有,那么和最大数匹配的数必须是第二大,如果是其他数,第二大数必定会被舍弃,而如果是第二大数,舍弃的数肯定比第二大小,所以最大和第二大匹配是局部最优解。再以此类推。
class Solution {
public:
int arrayPairSum(vector<int> &nums) {
sort(nums.begin(), nums.end());//从小到大排序
int ans = 0;
for (int i = 0; i < nums.size(); i += 2) {//每对数字左边的那个数
ans += nums[i];
}
return ans;
}
};两数之和II
给定一个已按照 升序排列 的有序数组,找到两个数使得它们相加之和等于目标数。
函数应该返回这两个下标值 index1 和 index2,其中 index1 必须小于 index2。
说明:
- 返回的下标值(index1 和 index2)不是从零开始的。
- 你可以假设每个输入只对应唯一的答案,而且你不可以重复使用相同的元素。
示例:
输入: numbers = [2, 7, 11, 15], target = 9
输出: [1,2]
解释: 2 与 7 之和等于目标数 9 。因此 index1 = 1, index2 = 2 。
解题思路:
使用双指针,一个指针指向值较小的元素,一个指针指向值较大的元素。指向较小元素的指针从头向尾遍历,指向较大元素的指针从尾向头遍历。
- 如果两个指针指向元素的和
sum == target,那么得到要求的结果; - 如果
sum > target,移动较大的元素,使sum变小一些,而左端的数不能更小,所以右指针左移一位,指向的数变小。 - 如果
sum < target,移动较小的元素,使sum变大一些,而右端的数不能更大,所以左指针右移一位,指向的数变大。 - 因为要求一个数只能用一次,所以循环终止条件
i==j - 题目给出的用例总会得到正确结果,所以循环结束随便返回个
vector就行。
数组中的元素最多遍历一次,时间复杂度为 O(N)。
只使用了两个额外变量,空间复杂度为 O(1)。
vector<int> twoSum(vector<int> &numbers, int target) {
int left = 0, right = numbers.size() - 1;
while (left < right) {
if (numbers[left] + numbers[right] == target) return {left + 1, right + 1};
else if (numbers[left] + numbers[right] < target) ++left;
else --right;
}
return {};
}移除元素
给你一个数组 nums 和一个值 val,你需要 原地 移除所有数值等于 val 的元素,并返回移除后数组的新长度。
不要使用额外的数组空间,你必须仅使用 O(1) 额外空间并 原地 修改输入数组。
元素的顺序可以改变。你不需要考虑数组中超出新长度后面的元素。
示例 1:
给定 nums = [3,2,2,3], val = 3,
函数应该返回新的长度 2, 并且 nums 中的前两个元素均为 2。
你不需要考虑数组中超出新长度后面的元素。
示例 2:
给定 nums = [0,1,2,2,3,0,4,2], val = 2,
函数应该返回新的长度 5, 并且 nums 中的前五个元素为 0, 1, 3, 0, 4。
注意这五个元素可为任意顺序。
你不需要考虑数组中超出新长度后面的元素。
说明:
为什么返回数值是整数,但输出的答案是数组呢?
请注意,输入数组是以「引用」方式传递的,这意味着在函数里修改输入数组对于调用者是可见的。
你可以想象内部操作如下:
// nums 是以“引用”方式传递的。也就是说,不对实参作任何拷贝
int len = removeElement(nums, val);// 在函数里修改输入数组对于调用者是可见的。
// 根据你的函数返回的长度, 它会打印出数组中 该长度范围内 的所有元素。
for (int i = 0; i < len; i++) {
print(nums[i]);
}
双指针
既然问题要求我们就地删除给定值的所有元素,我们就必须用 O(1) 的额外空间来处理它。如何解决?我们可以保留两个指针 slow 和 fast,其中 slow 是慢指针,fast 是快指针。
算法
当 nums[fast] 与给定的值相等时,递增 fast 以跳过该元素。只要 nums[fast] \neq val,我们就复制 nums[fast] 到 nums[slow] 并同时递增两个索引。重复这一过程,直到 slow 到达数组的末尾,该数组的新长度为 slow。
class Solution {
public:
int removeElement(vector<int> &nums, int val) {
int slow = 0, fast = 0;
for (; fast < nums.size(); ++fast) {
if (nums[fast] != val) {
nums[slow] = nums[fast];
++slow;
}
}
return slow;
}
};复杂度分析
时间复杂度:O(n),
假设数组总共有 n 个元素,i 和 j 至少遍历 2n 步。空间复杂度:O(1)。
最大连续1的个数
给定一个二进制数组, 计算其中最大连续1的个数。
示例 1:
输入: [1,1,0,1,1,1]
输出: 3
解释: 开头的两位和最后的三位都是连续1,所以最大连续1的个数是 3.
注意:
- 输入的数组只包含 0 和1。
- 输入数组的长度是正整数,且不超过 10,000。
双指针法
既然是双指针专题就强行双指针吧,重点在头指针是跳跃前进的,每次更新为tail+1
int findMaxConsecutiveOnes(vector<int> &nums) {
int ans = 0;//结果初始化为0
for (int head = 0; head < nums.size(); ++head) {//遍历数组,不能用while是因为在不等于1时head也要+1
if (nums[head] == 1) {//如果头指针处为1
int tail = head;
while (tail < nums.size() && nums[tail] == 1) {//从头指针处遍历到不为1的数
++tail;//尾指针最后指向数组末尾数字后面的位置或者连续个1后首个不为1的数字,也就是断裂点
}
ans = max(ans, tail - head);//比较新子数组大小和原本记录的最大值
head = tail;//头指针位置更新为尾指针处,即断裂点处,因为结束后还有++head操作,即最后更新为head+1
}
}
return ans;
}一次遍历法
用一个计数器 count 记录 1 的数量,另一个计数器 maxCount 记录当前最大的 1 的数量。
- 当我们遇到 1 时,
count加一。 - 当我们遇到 0 时:
- 将
count与maxCount比较,maxCoiunt记录较大值。 - 将
count设为 0。
- 返回
maxCount。
int findMaxConsecutiveOnes(vector<int> &nums) {
int maxCount = 0, count = 0;
for (int i = 0; i < nums.size(); ++i) {
if (nums[i] == 1) ++count;
else {
maxCount = max(maxCount, count);
count = 0;
}
}
return max(maxCount, count);//因为如果最后一个数字也是1,就不会再进入循环,也不会判0从而比较得出maxCount。因此循环结束后需要再比较一次。
}长度最小的子数组
给定一个含有 n 个正整数的数组和一个正整数 s ,找出该数组中满足其和 ≥ s 的长度最小的 连续 子数组,并返回其长度。如果不存在符合条件的子数组,返回 0。
示例:
输入:s = 7, nums = [2,3,1,2,4,3]
输出:2
解释:子数组 [4,3] 是该条件下的长度最小的子数组。
滑动窗口
什么一个数组上面找符合条件的最优连续数组呀啪就是一个滑动窗口,很快啊。
滑动窗口思想 就是不断的调节子序列的起始位置和终止位置,从而得出我们要想的结果。
算法步骤:
- 首先要维护一个全局变量:满足和≥s的最小子数组长度ans;
- 然后令窗口滑过整个数组,过程中不断更新ans;
窗口移动规则:
- 当窗口的值
≥s时:用min()更新ans,并通过窗口左指针的右移来缩小窗口。 - 当窗口的值
<s时:在不越界的前提下,通过窗口右指针的右移来扩大窗口。
返回值规则:
- 如果ans没有被赋值的话,说明没有符合条件的子序列,就返回0。
class Solution {
public:
int minSubArrayLen(int s, vector<int> &nums) {
if (nums.empty()) return 0;
int sum = 0;
int left = 0, right = 0;
int ans = nums.size() + 1;
while (right < nums.size()) {
sum += nums[right];
while (sum >= s) {
ans = min(ans, right - left + 1);
sum -= nums[left];
++left;
}
++right;
}
return ans == nums.size() - 1 ? 0 : ans;
}
};复杂度分析
时间复杂度:O(n),其中 n 是数组的长度。指针 \textit{left} 和 \textit{right} 最多各移动 n 次。
空间复杂度:O(1)。
有的人可能会觉得两层while循环为什么是O(n)时间复杂度,下面本人再瞎写个一层while循环的。
一层while循环瞎写版
int minSubArrayLen(int s, vector<int> &nums) {
int sum = 0;
int left = 0, right = 0;
while (right < nums.size() && sum < s) {
sum += nums[right++];
}
if (sum < s) return 0;//如果出了循环和还是小于s,相当于把所有数加起来都不满足,直接输出0
--right;//因为循环结束前right++了,所以是指向子数组末尾数字的后面,要right--令其指向末尾数字
int ans = right - left + 1;
while (right < nums.size()) {
if (sum >= s) {
ans = min(ans, right - left + 1);//更新ans
sum -= nums[left];//先减去最左端数字
++left;//指针右移
} else {
++right;//要先right++移动到要扩容的数字上
if (right == nums.size()) break;//因为可能越界,所以要加个判断
sum += nums[right];//加上最右端右边的数字
}
}
return ans;
}不用更新结果法
- 在第一个
while循环中先初始化窗口的长度,即从最左端开始满足>s的窗口。 - 之后的
while每次迭代中只缩小或者平移窗口,从不扩大窗口
- 如果当前窗口长度和
<s,则平移 - 如果当前窗口长度和
>=s,则右端缩小
- 这样窗口平移到最后,长度一定是过程中最小的长度,即使当前不满足和
>=s - 这样不需要去维护一个历史最小窗口的
min值
class Solution1 {
public:
int minSubArrayLen(int s, vector<int> &nums) {
int sum = 0;
int left = 0, right = 0;
while (right < nums.size() && sum < s) {
sum += nums[right++];//因为right是后++,当该循环结束,应该是上一轮的right是正确的右端,right指向的是右端右边的位置
}
if (sum < s) return 0;
while (right < nums.size()) {
if (sum < s) {
sum += nums[right];
++right;//因为right是后++,当该循环结束,应该是上一轮的right是正确的右端,right指向的是右端右边的位置,与上面规则一致
}
sum -= nums[left];
++left;//这时left指向最左端,但如果不满足下轮循环条件,应该是用left-1作左端,与下面规则一致
}
while (sum >= s) {
sum -= nums[left];
++left;//因为left是后++,当该循环结束,应该是上一轮的left是正确的左端,left其实指向的是第二个数字
}
return right - left + 1;//这个其实是(right-1)-(left-1)+1,一开始还挺绕的
}
};- 我太菜了,我觉得这个做法对于边界处理比较绕,不推荐。并且最后运行时间也没差别。
杨辉三角I
给定一个非负整数 numRows,生成杨辉三角的前 numRows 行。
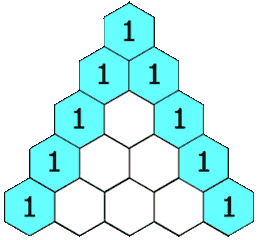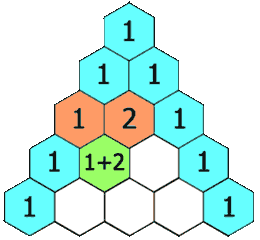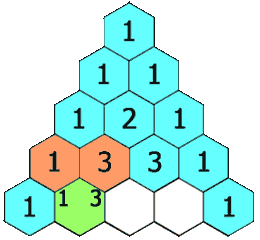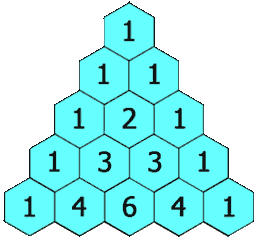
在杨辉三角中,每个数是它左上方和右上方的数的和。
示例:
输入: 5
输出:
[
[1],
[1,1],
[1,2,1],
[1,3,3,1],
[1,4,6,4,1]
]
题解:
简单题没什么好说的。
- 顺序模拟,第一行单独考虑。
放1->循环放ans[i - 1][j] + ans[i - 1][j + 1]->放1。
class Solution {
public:
vector<vector<int>> generate(int numRows) {
vector<vector<int>> ans(numRows);
for (int i = 0; i < numRows; ++i) {
ans[i].push_back(1);//放1
if (i == 0) continue;//第一行的话跳出本轮循环
for (int j = 0; j < i - 1; ++j) {//中间部分根据上一行相加
ans[i].push_back(ans[i - 1][j] + ans[i - 1][j + 1]);
}
ans[i].push_back(1);//再放1
}
return ans;
}
};- 或者每一行
resize()大小,用坐标赋值而不用push_back(),这样不用单独考虑第一行了。
class Solution {
public:
vector<vector<int>> generate(int numRows) {
vector<vector<int>> ret(numRows);
for (int i = 0; i < numRows; ++i) {
ret[i].resize(i + 1);
ret[i][0] = ret[i][i] = 1;
for (int j = 1; j < i; ++j) {
ret[i][j] = ret[i - 1][j] + ret[i - 1][j - 1];
}
}
return ret;
}
};杨辉三角II
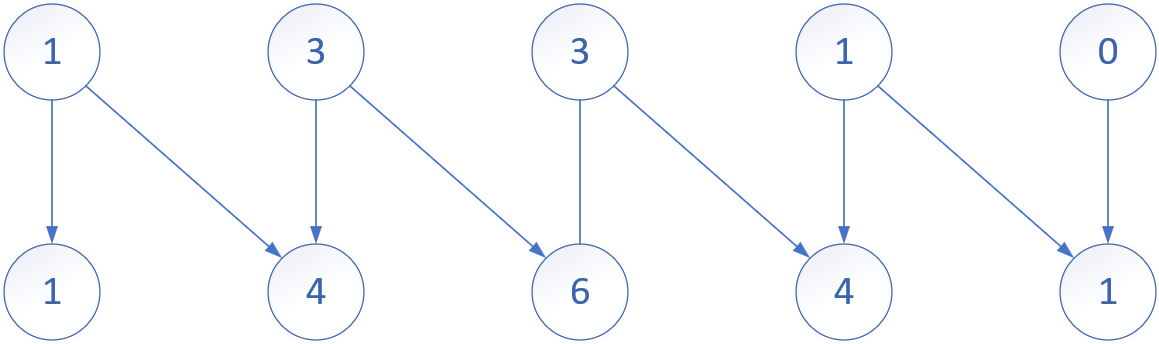
给定一个非负索引 k,其中 k ≤ 33,返回杨辉三角的第 k行。
在杨辉三角中,每个数是它左上方和右上方的数的和。
示例:
输入: 3
输出: [1,3,3,1]
进阶:
你可以优化你的算法到 O(k) 空间复杂度吗?
解法:
- 开辟k+1大小的结果数组,初始化为0。
- 从第1层开始遍历到第k层,每层都更新一次数组,这时还需要一次层遍历。
- 数组的最左端在最开始被初始化为1,也就是第一层初始化为1。
- 每层数组除了第一个位置,每个位置都被更新为上一层对应位置+对应位置前一位置的和。
vector<int> getRow(int rowIndex) {
vector<int> ans(rowIndex + 1);//因为这个题有第0行,所以开辟数组大小为rowIndex+1
ans[0] = 1;//第一个数字初始化为1
for (int i = 1; i <= rowIndex; ++i) {//因为这个题有第0行,所以边界最大为rowIndex
for (int j = i; j > 0; --j) {//要从右向左更新数组,否则会覆盖而不能正确更新
ans[j] += ans[j - 1];
}
}
return ans;
}反转字符串中的单词 III
给定一个字符串,你需要反转字符串中每个单词的字符顺序,同时仍保留空格和单词的初始顺序。
示例:
输入:“Let’s take LeetCode contest”
输出:“s’teL ekat edoCteeL tsetnoc”
提示:
- 在字符串中,每个单词由单个空格分隔,并且字符串中不会有任何额外的空格。
双指针
因为题目字符串每个单词中间只有一个空格,所以可以利用这一特性用双指针模拟遍历字符串,一个指向单词头,一个指向单词尾,遇到空格就reverse两指针之间的字符串。
class Solution {
public:
string reverseWords(string s) {
int head = 0, tail = 0;//因为前面没有空格,直接初始化为0指向单词开头
while (head < s.length()) {
while (s[tail] != ' ' && tail < s.length()) {
++tail;//将tail迭代到单词最后一个字母的后一个位置
}
reverse(s.begin() + head, s.begin() + tail);//注意reverse一个是字符串开头,一个是字符串末尾字符的后一个位置
++tail;//因为只有一个空格,直接后移一位就是下一个单词开头
head = tail;//tail与head重合,等待迭代
}
return s;
}
};寻找旋转排序数组中的最小值
假设按照升序排序的数组在预先未知的某个点上进行了旋转。例如,数组 [0,1,2,4,5,6,7] 可能变为 [4,5,6,7,0,1,2] 。
请找出其中最小的元素。
示例 1:
输入:nums = [3,4,5,1,2]
输出:1
示例 2:
输入:nums = [4,5,6,7,0,1,2]
输出:0
示例 3:
输入:nums = [1]
输出:1
提示:
- 1 <= nums.length <= 5000
- -5000 <= nums[i] <= 5000
- nums 中的所有整数都是 唯一 的
- nums 原来是一个升序排序的数组,但在预先未知的某个点上进行了旋转
二分查找
这题如果出肯定是想让用二分查找写,一开始本人写了个双指针遍历,平均复杂度也是O(N),仔细一想我真是弱智。
二分查找关键是找出什么情况下排除元素缩小范围,一开始以为和最左边或者最右边比较都行,但后来试验+思考发现只能比较最右边的数字。
因为对于1,2,3,4,5和2,3,4,5,1,mid都比最左边大,但要找的元素一个在右一个在左。
这受制于是从小到大排序并且找最小的元素。
int findMin(vector<int>& nums) {
int left=0,right=nums.size()-1;
while (left<right){//老规矩,小于号循环条件+排除范围找法
int mid=left+(right-left)/2;
if (nums[mid]<nums[right]){//如果比最右端小,要找的元素一定不在[mid+1,right]中
right=mid;
} else left=mid+1;//如果比最右端大,要找的元素一定不在[left,mid]中
}
return nums[left];//筛选出剩一个元素就是要找的
}
删除排序数组中的重复项
给定一个排序数组,你需要在 原地 删除重复出现的元素,使得每个元素只出现一次,返回移除后数组的新长度。
不要使用额外的数组空间,你必须在 原地 修改输入数组 并在使用 O(1) 额外空间的条件下完成。
示例 1:
给定数组 nums = [1,1,2],
函数应该返回新的长度 2, 并且原数组 nums 的前两个元素被修改为 1, 2。
你不需要考虑数组中超出新长度后面的元素。
示例 2:
给定 nums = [0,0,1,1,1,2,2,3,3,4],
函数应该返回新的长度 5, 并且原数组 nums 的前五个元素被修改为 0, 1, 2, 3, 4。
你不需要考虑数组中超出新长度后面的元素。
说明:
为什么返回数值是整数,但输出的答案是数组呢?
请注意,输入数组是以「引用」方式传递的,这意味着在函数里修改输入数组对于调用者是可见的。
你可以想象内部操作如下:
// nums 是以“引用”方式传递的。也就是说,不对实参做任何拷贝
int len = removeDuplicates(nums);// 在函数里修改输入数组对于调用者是可见的。
// 根据你的函数返回的长度, 它会打印出数组中该长度范围内的所有元素。
for (int i = 0; i < len; i++) {
print(nums[i]);
}
双指针法
数组完成排序后,我们可以放置两个指针 slow 和 fast,其中 slow 是慢指针,而 fast 是快指针。只要 nums[slow]=nums[fast],我们就增加 fast 以跳过重复项。
当我们遇到 nums[fast] \neq nums[slow] 时,跳过重复项的运行已经结束,因此我们必须把它(nums[fast])的值复制到 nums[slow + 1]。然后递增 slow,接着我们将再次重复相同的过程,直到 fast 到达数组的末尾为止。
int removeDuplicates(vector<int> &nums) {
if (nums.empty()) return 0;
int slow=0;
for (int fast = 1; fast < nums.size(); ++fast) {//每回合fast后移一位
if (nums[slow]!=nums[fast]){//遇到比当前不重复字符串末尾字符还大的数字了
nums[++slow]=nums[fast];//slow要先+1指向待填入的位置,因为slow始终比fast慢至少一个,所以不担心越界
}
}
return slow+1;//注意slow最后指向不重复字符串的最后一个字符,所以长度要+1
}复杂度分析
时间复杂度:O(n),假设数组的长度是 n,那么 slow 和 fast 分别最多遍历 n 步。
空间复杂度:O(1)。
本作品采用《CC 协议》,转载必须注明作者和本文链接



 关于 LearnKu
关于 LearnKu



