
可用于解析 Excel 文件的程序语言
14 / 0 / 创建于 3年前
 cainiao_M 的个人博客
cainiao_M 的个人博客
Excel文件是常见的数据文件,数据分析过程中经常会用到。有时我们需要用程序代码对 Excel 文件进行一些自动化处理,这需要程序语言能够方便地解析 Excel 数据。
可以用于解析和处理 Excel 文件的程序语言一般有以下几种:
1、 常规高级编程语言,比如 Java
2、 Excel VBA
3、 Python
4、 esProc SPL
本文依次介绍以上几种程序语言解析Excel文件的特点,重点放在如何将Excel文件读出为结构化数据,之后是用来再计算或是入库或是其它用途,就只作简单介绍。
一、 高级语言(以Java为例)
高级语言几乎都可以读取Excel数据文件,但要看有没有第三方提供专业的API来读取,若是没有,就需要程序员自己去了解Excel数据文件的结构,编写程序来读取数据,工作量非常大。幸运的是, Apache为Java提供了开源包poi用以读写Excel文件,它能读取每个单元格的数据和属性。让我们来看看用poi如何将Excel文件读成结构化的数据。
先看一个很简单的文件:第一行是列标题,第二行开始直到最后一行都是数据行。文件内容如下图:
用java调用poi读取数据,写出来的程序是这样:
DataSet ds = null; //此类用来保存从Excel中读取的数据,需要自己编写
HSSFWorkbook wb = new HSSFWorkbook( new FileInputStream( “simple.xls” ) );
HSSFSheet sheet = wb.getSheetAt( 0 ); //假定要读取的数据在第一个sheet中
int rows = sheet.getLastRowNum();
int cols = sheet.getRow(0).getLastCellNum();
ds = new DataSet( rows, cols );
for( int row = 0; row <= rows; row++ ) {
HSSFRow r = sheet.getRow( row );
for( int col = 0; col <= cols; col++ ) {
HSSFCell cell = r.getCell( col );
int type = cell.getCellType();
Object cellValue; //单元格数据值对象
switch( type ) { //根据单元格数据类型,将格值处理成对应的Java对象
case HSSFCell.CELL_TYPE_STRING:
……
case HSSFCell.CELL_TYPE_NUMERIC:
……
……
//格值处理代码比较长,此处省略
}
if( row == 0 ) ds.setColTitle( col, (String)cellValue );
else ds.setCellValue( row, col, cellValue );
//如果是第一行,则将格值设成列标题,否则设成数据集单元格数据
}
}
这段代码只能读取最简单格式的Excel文件,中间还省略了很多格值处理的代码,但代码已经不短了。如果文件格式更复杂,比如有合并格、复杂的多行表头表尾、数据记录分散于多行、交叉表等,读取数据的程序代码就会变得更长更复杂。
可以看出,即使有了poi这样强大的开源包,使用Java来解析Excel仍然是非常麻烦的。
而且,高级语言只提供比较基础的底层函数,缺乏专业的结构化数据计算函数,比如数据集的过滤、排序、分组统计、连接等,都需要程序员自己去编写,因此即使数据读出来了,但要进行后续的计算,仍然有大量的工作要做。
二、 Excel VBA
VBA(Visual Basic for Applications)是Visual Basic的一种宏语言,主要能用来扩展Windows的应用程序功能,特别是Microsoft Office软件如Word、Excel、Access等。VBA用于Excel的目的是为了增强Excel的灵活性和数据处理能力。VBA可以直接获取单元格的数据,相当于天然有了解析能力,这一点比Java等高级语言方便了很多。但除此之外,它与高级语言一样,仍然缺乏专业的结构化计算函数,读取数据以后的后续计算,还是需要编写大量的程序代码。
比如写一段分组汇总(对sheet1的A列分组,对B列求和)的代码是这样的:
Public Sub test()
Dim Arr
Dim MyRng As Range
Dim i As Long
Dim Dic As Object
Set MyRng = Range(“A1”).CurrentRegion
Set MyRng = MyRng.Offset(1).Resize(MyRng.Rows.Count - 1, 2)
Set Dic = CreateObject(“Scripting.dictionary”)
Arr = MyRng
For i = 1 To UBound(Arr)
If Not Dic.exists(Arr(i, 1)) Then
Dic.Add Arr(i, 1), Arr(i, 2)
Else
Dic.Item(Arr(i, 1)) = Dic.Item(Arr(i, 1)) + Arr(i, 2)
End If
Next i
Sheet2.Range(“A1”) = “subject”
Sheet2.Range(“A2”).Resize(Dic.Count) = Application.WorksheetFunction.Transpose(Dic.keys)
Sheet2.Range(“B1”) = “subtotal”
Sheet2.Range(“B2”).Resize(Dic.Count) = Application.WorksheetFunction.Transpose(Dic.items)
Set Dic = Nothing
End Sub
毕竟我们解析Excel文件是为了后续计算和处理,仅仅解析本身是没有用处的。VBA能天然解析Excel文件,但后续处理能力并不方便。
三、 Python
Python pandas提供了读取Excel文件的接口,对于前述用Java读取的那个简单格式的Excel文件,用Python读取的代码如下:
import pandas as pd
file = ‘simple.xls’
data = pd.read_excel(file,sheet_name=’Sheet1’,header=0)
参数header=0表明第一行是列标题,data就是读出来的结构化数据集。
对于表头结构比较复杂的Excel,比如下图:
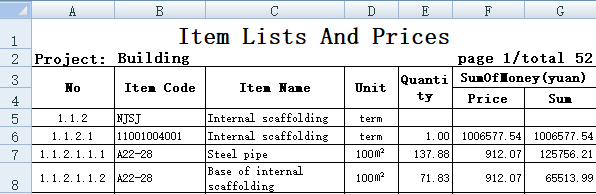
用Python读取这个文件的程序如下:
import pandas as pd
file = ‘complex.xls’
data = pd.read_excel(file,sheet_name=’Sheet1’,header=None,skiprows=[0,1,2,3])
data.columns=[‘No’, ‘ItemCode’, ‘ItemName’, ‘Unit’, ‘Quantity’, ‘Price’, ‘Sum’]
在读取时用参数指定没有表头且读数时跳过前面4行,从第5行数据区开始读(如果有表尾,还可以指定忽略最后几行),程序最后一行设置数据集data的列名。
Excel文件中还常有交叉表数据,例如下图:
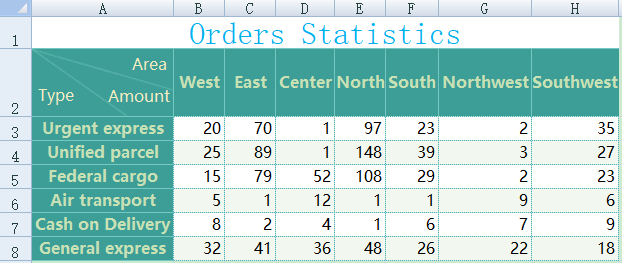
读取这个交叉表的程序如下:
import pandas as pd
file = ‘cross.xls’
data = pd.read_excel(file,sheet_name=’Sheet1’,header=1)
data = data.melt(id_vars=[‘Unnamed: 0’],
value_vars=[‘West’, ‘East’,’Center’, ‘North’,’South’, ‘Northwest’,’Southwest’],
var_name=’Area’,
value_name=’Amount’)
data.rename(columns={‘Unnamed: 0’: ‘Type’})
读出来的data数据如下图:

可以看出来,Python读取Excel文件的代码比较简单,比Java前进了一大步。而且pandas封装了不少结构化数据的处理函数,对于后续计算也比Java和VBA提供了较好的支持。如果是可读入内存的小文件,它可以很简单地处理。
可惜的是,pandas没有针对大文件提供直接分批处理的方法,无论读取还是运算仍然要自己写,非常麻烦。可参考Python 如何处理大文件。
四、 esProc SPL
esProc是专业的数据处理工具,提供了各种读取Excel文件的方法,其脚本语言SPL中封装了丰富的结构化数据计算函数,可以完美地支持各种后续计算、数据导出及入库等工作。
esProc读取Excel文件的程序非常简单,只要写一行代码就可以:
1、 简单格式
=file(“simple.xls”).xlsimport@t()
选项@t表示第一行是列标题
2、 复杂表头
=file(“complex.xls”). xlsimport(;1,5).rename(#1:No,#2:ItemCode,#3:ItemName,
#4:Unit,#5:Quantity,#6:Price,#7:Sum)
参数1,5表示读第1个sheet,从第5行开始读(也可以指定结束行),读数以后再用rename修改列名
3、 交叉表
=file(“cross.xls”).xlsimport@t(;1,2).rename(#1:Type).pivot@r(Type;Area,Amount)
pivot函数中以Type分组对表数据进行行列转置,选项@r表示将列数据转换为行数据,转换后新的列名分别为“Area”、“Amount”。
从代码上可以看出来,对于解析Excel文件,esProc SPL比Python pandas更为简洁。事实上,SPL做后续处理计算比pandas有更大优势,具体可参考桌面轻量级数据处理脚本。
而且,esProc还可以很方便地进行大文件数据的读取和计算,它提供游标机制,允许数据分析师用类似处理小数据量的语法,直观地处理较大的数据量,程序代码和处理小文件一样简单,比如简单格式的大数据量文件,用游标读数的程序代码是:
=file(“big.xlsx”).xlsimport@tc()
通过比较,我们可以看到,Python pandas和esProc SPL用于解析Excel文件的代码都很简练,而且也都具备丰富的结构化计算函数,可以实现日常工作中的数据处理。两者相比,esProc SPL更为简洁,并且还能方便地处理大文件。
本作品采用《CC 协议》,转载必须注明作者和本文链接


 关于 LearnKu
关于 LearnKu




推荐文章: