
月半谈(一)redis-分布式锁与应用
771 / 12 / 创建于 3年前 /
 漫天风雨下西楼 的个人博客
漫天风雨下西楼 的个人博客
基于 redis 的分布式锁与基础应用
最近一直有在做一些抢购,限流方面的工作,这两周就打算写 业务中的锁与php、golang 实践方面的东西。
实践一 基于 Redis 锁的限流操作
针对于 发送验证码场景
- 要求是 单个手机号码 60秒内,只允许发送一次,来防止短信接口被无限次的恶意调用
先看看 一般逻辑写法
测试相关工具
- 测试框架为 Hyperf2.0 + php 7.2
- mysql 链接池 10-100
- redis 链接池 10-100
- 并发测试 工具为 Apache JMter 5.2.1
- 测试环境 为 contOS 7.7
- MySQL 5.6
- 比如有一张 send_records 表
idcodemobilecreated_atupdated_at字段
不加锁 DB 插入判定
public function testSend()
{
$mobile = $this->request->input('mobile', '13711111111');
$sendModel = DB::table('send_records');
$ok = $sendModel->where('mobile', $mobile)->where('created_at', '>', date('Y-m-d H:i:s', time() - 60))->exists();
// 存在则说明60秒内已经发送
if ($ok) {
return ['data' => [], 'msg' => 'send fail'];
}
$code = mt_rand(1000, 9999);
$sendModel->insert([
'mobile' => $mobile,
'code' => $code,
'created_at' => date('Y-m-d H:i:s'),
'updated_at' => date('Y-m-d H:i:s'),
]);
//send msg doing
//发短信 一些耗时操作
for ($i = 0; $i < 10000000; $i++) {
//....
}
return ['data' => [], 'msg' => 'ok'];
}采用 JMter 100 线程 1秒内 请求一次的 方式进行压测 ,

结果不出所料,在高并发下,数据库出现了重复的数据
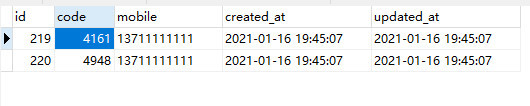
根据代码 逻辑来看, 就是在 第一步判定与第二步插入数据之间,出现了并发的请求,从而导致多个请求进入了发送的逻辑。
那这种写法有没有改良做法呢?
有呀, 那就是利用锁的机制 !
先看看改动最小的 MySQL 的行锁
加 MySQL行锁 再进行判定
public function testSendWithDBLock()
{
$mobile = $this->request->input('mobile', '13711111111');
Db::beginTransaction();
$sendModel = DB::table('send_records');
$ok = $sendModel->where('mobile', $mobile)
->where('created_at', '>', date('Y-m-d H:i:s', time() - 60))
->lockForUpdate()->first();
if ($ok) {
Db::rollBack();
return ['data' => [], 'msg' => 'send fail'];
}
$code = mt_rand(1000, 9999);
$sendModel->insert([
'mobile' => $mobile,
'code' => $code,
'created_at' => date('Y-m-d H:i:s'),
'updated_at' => date('Y-m-d H:i:s'),
]);
Db::commit();
//send msg doing
//发短信 一些耗时操作
for ($i = 0; $i < 10000000; $i++) {
//....
}
return ['data' => [], 'msg' => 'ok'];
}上述代码加入了MySQL 行锁,成功解决了并发问题!
那么这种写法有没有问题呢?
优点是代码改动下,也很清晰,但是这种写法的缺点也很明显
一个是依赖MySQL的锁机制,在高并发时这会消耗MySQL大量的资源,而MySQL作为底层存储,一旦挂掉势必会影响到其它业务,当锁住的表为核心表时,那就更加会是整个系统的瓶颈了
第二个是,在使用 行锁后,接口的TPS 出现了 50% 以上的跌幅
所以在预期有高并发时候,不推荐这种写法。
我们验证了锁的好处,那么就是想办法让 Redis 去模拟锁就好了,高性能的Redis 正好可以来满足性能与降低DB负载两方面的要求
Redis 模拟锁的错误写法
public function testSendByRedisLock()
{
$mobile = $this->request->input('mobile', '13711111111');
$redis = \Hyperf\Utils\ApplicationContext::getContainer()->get(\Hyperf\Redis\Redis::class);
$existKey = "serve:mobile:{$mobile}";
if ($redis->exists($existKey)) {
return ['data' => [], 'msg' => 'send fail'];
}
if (!$redis->setex($existKey, 60, "ok")) {
return ['data' => [], 'msg' => 'send fail'];
}
$code = mt_rand(1000, 9999);
DB::table('send_records')->insert([
'mobile' => $mobile,
'code' => $code,
'created_at' => date('Y-m-d H:i:s'),
'updated_at' => date('Y-m-d H:i:s'),
]);
//send msg doing
//发短信 一些耗时操作
for ($i = 0; $i < 10000000; $i++) {
//....
}
return ['data' => [], 'msg' => 'ok'];
}这个写法虽然并发上去了,但是会出现跟未使用DB 锁时候的一样,未能成功阻止并发的请求,因为 exist 与 setnx 两个操作 未能合并成原子的写法。
redis 在 2.6.12 版本 对 set 进行了优化,增加了 EX, PX, NX 与 XX 可选项来处理 这种情况
Redis 模拟锁的改良写法
$existKey = "serve:mobile:{$mobile}";
# 原来写法
if ($redis->exists($existKey)) {
return ['data' => [], 'msg' => 'send fail'];
}
if (!$redis->setex($existKey, 60, "ok")) {
return ['data' => [], 'msg' => 'send fail'];
}
# 改良写法
if (!$redis->set($existKey, "ok", ['NX', 'EX' => 60])) {
return ['data' => [], 'msg' => 'send fail'];
}自此 就使用 redis 就完美的模拟了锁的机制。至少能最大限度的解决我们最开始提出来的问题。
但是 上述写法还存在一些问题,如超时问题,还有 Redis 集群间的锁同步问题
实践二 基于 Redis 锁的 乱序转顺序执行操作
超时问题
问题描述为 : 如果一次只能有一个客户端去处理,上个客户端处理完成,下个客户端才能进来
模拟代码如下
$redis = \Hyperf\Utils\ApplicationContext::getContainer()->get(\Hyperf\Redis\Redis::class);
$existKey = "serve:mobile";
if (!$redis->set($existKey, "ok", ['NX', 'EX' => 2])) {
return ['data' => [], 'msg' => 'send fail'];
}
DB::table('send_records')->insert([
'mobile' => $mobile,
'code' => time(),
'created_at' => date('Y-m-d H:i:s'),
'updated_at' => date('Y-m-d H:i:s'),
]);
//doing something 大约执行3秒
for ($i = 0; $i < 100000000; $i++) {
//....
}
// down
$redis->del($existKey);那如果使用上述的Redis锁,一个客户的处理 完成后会去解锁,因为使用的是同一个Key,如果A客户进入超时那么就会解掉B的🔒
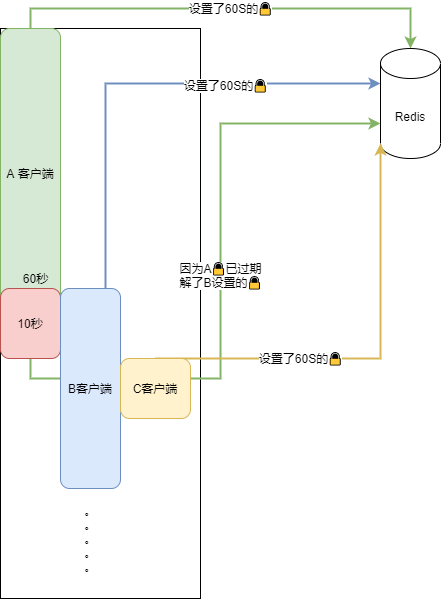
这样无限套下去锁就失效了,同时可能会存在多个进程/线程/协程 同时在处理。

我将压测时间延长,就得到了上图,349 的锁 被 348 给解了 所以 出现了 349 跟 351 同时执行的问题。
所以对于应用来说,解锁应该判断是否是当初自己设置的锁,通过设置的唯一值来判定
如:
$redis = \Hyperf\Utils\ApplicationContext::getContainer()->get(\Hyperf\Redis\Redis::class);
$existKey = "serve:mobile";
$value = \Hyperf\Utils\Coroutine::id() . mt_rand(1000, 9999);
if (!$redis->set($existKey, $value, ['NX', 'EX' => 2])) {
return ['data' => [], 'msg' => 'send fail'];
}
DB::table('send_records')->insert([
'mobile' => $mobile,
'code' => time(),
'created_at' => date('Y-m-d H:i:s'),
'updated_at' => date('Y-m-d H:i:s'),
]);
//doing something 大约执行3秒
for ($i = 0; $i < 100000000; $i++) {
//....
}
// down
$script = 'if redis.call("get",KEYS[1]) == ARGV[1]
then
return redis.call("del",KEYS[1])
else
return 0
end';
$redis->eval($script, $existKey, $value);这里用到了 lua 脚本 来保证原子性, 通过协程号来生成唯一值(这个也不是唯一的,只是相对来说,比较安全,分布式部署的需要加入机器的mac地址之类的唯一编号来做进一步区分),但是这种操作也只是相对安全,当 A超时,A、B 客户端同时执行时,其实就不是串行化执行了,需要评估对于业务的影响。
Redis 集群与 Redlock 问题
上面我们讨论了超时问题,那么最后一个问题就是,当 Redis 不是单机而是集群时,上述的锁机制就可能因为同步机制的不稳定而导致 出现多台Redis 上 存在 不同的🔒的情况。针对于 这种情况,Redis 作者提出了 Redlock 算法来保证集群的一致性。
当前有N个完全独立的 Redis master 节点, 分别部署在不同的主机上,客户端设置锁的操作:
- 使用相同key和唯一值同时向这N个 Redis 节点请求锁, 锁的超时时间应该 远大于 整个请求的耗时时间
- 计算步骤1消耗的时间, 若总消耗时间超过超时时间, 则认为锁失败. 客户端需在大多数(超过一半)的节点上成功获取锁, 才认为是锁成功
- 如果锁成功了, 则该锁有效时间 = 锁原始有效时间 - 步骤1消耗的时间
- 如果锁失败了(超时或无法获取超过一半实例的锁), 客户端会到每个之前加锁失败节点释放锁
当然这个算法也有很大的争议,分布式设计比起单机来说,都存在一定的缺陷,就目前来说单机的Redis 锁已经能满足业务的需求,当单机 Redis 扛不住的时候,再考虑 其它的分布式🔒。
本来以为写起来应该很快,但实际上草稿都快写了半天,这大概就是关于 Redis 锁的相关操作,下次我们可以聊一下基于ETCD的分布式锁 跟锁的算法相关的问题。
本作品采用《CC 协议》,转载必须注明作者和本文链接






























 关于 LearnKu
关于 LearnKu




推荐文章: