
MySQL学习之基础架构
289 / 3 / 创建于 3年前 /
 thinkabel 的个人博客
thinkabel 的个人博客

一、背景
为什么我先学习MySQL的基础架构呢? 原因很简单, 当我们需要了解一项新事物的时候, 我们只有站在宏观的层面, 才能层层的去理解问题, 举个例子, 我们要看一个框架的源码, 一开始钻研进去研究, 发现就有点 “丈二的和尚摸不着头脑”。因为我们没有自己的了解他,不知道他的入口在哪?
看一个事儿千万不要直接陷入细节里,你应该先鸟瞰其全貌,这样能够帮助你从高维度理解问题
<MySQL 45 讲>
二、MySQL 基本架构
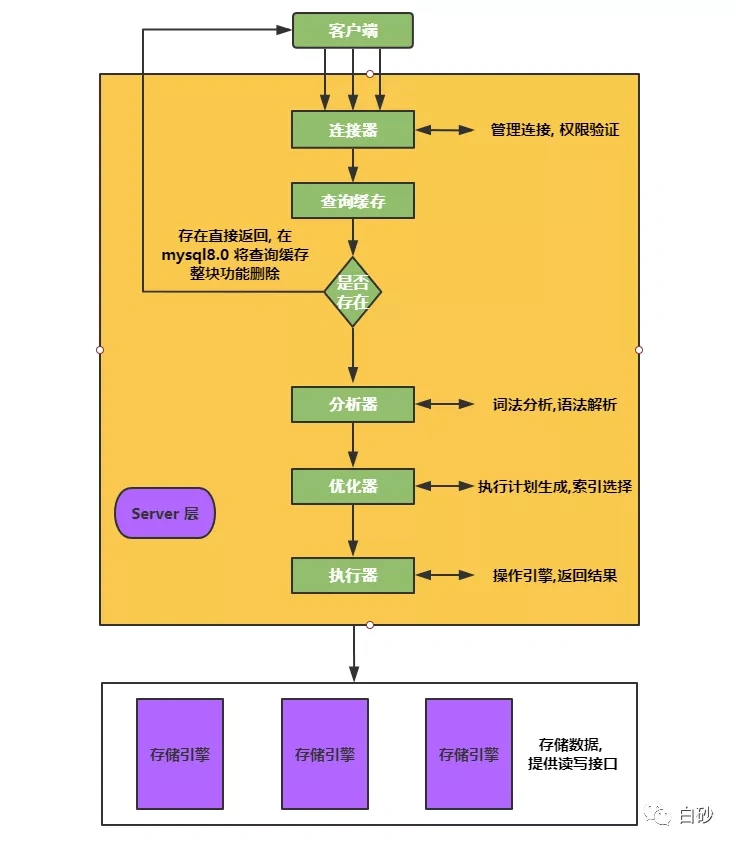
(MySQL 逻辑架构图)
从图中我们可以清晰的看到, SQL 语句在MySQL的各个功能模块中的执行过程, 总结一下可以分为 Server 层 和 存储引擎 两个部分。
Server层
Server层包括连接器、查询缓存、分析器、优化器、执行器等,涵盖了 MySQL 的大多数核心服务功能, 以及所有的内置函数 (如 时间, 日期, 数学函数 等), 所有跨存储引擎的功能都在这实现, 存储过程, 视图, 触发器等.
存储引擎
存储引擎负责数据的存储和提取。架构模式是插件式的,支持InnoDB, MyISAM, Memory等 多个存储引擎. MySQL 5.5.5 版本开始, InnoDB 成为默认存储引擎。
连接器
功能作用:负责跟客户端建立连接、获取权限、维持和管理连接,如用户名密码认证通过,连接器会到权限表里面查出你拥有的权限。之后,这个连接里面的权限判断逻辑,都将依赖于此时读到的权限。修改完成后,只有再新建的连接才会使用新的权限设置
连接对象:MySQL 在执行过程中临时使用的内存是管理在连接对象里面的,这些资源会在连接断开的时候才释放。
注意点:
在用户成功连接后,即使你用管理员账号对该用户进行了权限更改,也不会影响已经存在连接的权限。如果想要权限生效,只有在新建的连接才会使用新的权限设置。
在这里我们要了解两个点:长连接和短连接的概念。
数据库里面,长连接是指连接成功后,如果客户端持续有请求,则一直使用同一个连接。短连接则是指每次执行完很少的几次查询就断开连接,下次查询再重新建立一个。
长链接在数据库中,每次建立连接是比较复杂的,所以在使用中尽量减少建立连接的动作,就是使用长链接。
长连接引发的思考:
风险问题:MySQL在执行过程中临时使用的内存是管理在连接里面的, 这些资源只有断开的时候才会释放, 长连接累积下来,可能会导致内存占用过大,被系统强行杀掉(OOM)
解决方案:定期断开长链接,使用一段时间,或者执行一个占用内存大的查询后,断开连接,在进行重连。如果使用的是MySQL5.7或者更新的版本, 在每次执行比较大的操作后,通过 mysql_reset_connection**重新初始化连接资源**, 这个过程中不需要重连和进行权限验证的,但是会恢复到刚刚创建的状态。
查询缓存
存储方式:是以** key-value**的形式进行缓存在内存中的,key 是查询的语句,value 是查询的结果。如果你的查询能够直接在这个缓存中找到 key,那么这个 value 就会被直接返回给客户端。
风险:大多数情况下我会建议你不要使用查询缓存,为什么呢?因为查询缓存往往弊大于利。查询缓存的失效非常频繁,只要有对一个表的更新,这个表上所有的查询缓存都会被清空。MySQL 8.0 版本直接将查询缓存的整块功能删掉了,也就是说 8.0 开始彻底没有这个功能了。
分析器
词法分析:识别出 SQL 语句里面的字符串分别是什么,代表什么,把** SQL** 语句中字符串 T *识别成“表名 *T,把字符串** ID** 识别成 列ID
语法分析:根据词法分析的结果,语法分析器会根据语法规则,判断你输入的这个 SQL 语句是否满足 MySQL 语法
优化器
- 功能作用:优化器是在表里面有多个索引的时候,决定使用哪个索引;或者在一个语句有多表关联(join)的时候,决定各个表的连接顺序
优化器
查询语句:
调用 InnoDB 引擎接口取这个表的第一行,判断 ID 值是不是 5,如果不是则跳过,如果是则将这行存在结果集中
调用引擎接口取 下一行,重复相同的判断逻辑,直到取到这个表的最后一行
执行器将上述遍历过程中所有满足条件的行组成的记录集作为结果集返回给客户端
更新语句
执行器先找引擎取 ID=2 这一行,ID 是主键,引擎直接用树搜索找到这一行,如果 *ID=2 *这一行所在的数据页本来就在内存中,就直接返回给执行器,否则,需要先从磁盘读入内存,然后再返回。
执行器拿到引擎给的行数据,把这个值加上** 1,比如原来是 **N,现在就是 N+1,得到新的一行数据,再调用引擎接口写入这行新数据
引擎将这行新数据更新到内存中,同时将这个更新操作记录到** redo log** 里面,此时 redo log 处于 prepare 状态。然后告知执行器执行完成了,随时可以提交事务
执行器生成这个操作的 binlog,并把 binlog 写入磁盘
执行器调用引擎的提交事务接口,引擎把刚刚写入的 redo log 改成提交(commit)状态,更新完成
本作品采用《CC 协议》,转载必须注明作者和本文链接













 关于 LearnKu
关于 LearnKu




推荐文章: