
MongoDB 操作文档 查询文档
1 / 0 / 创建于 4年前 /
 HuDu 的个人博客
HuDu 的个人博客
一、查询文档
1、查询所有
MongoDB 查询数据的语法格式如下:
db.uesr.find() # 等同于 db.user.find({})
# 根据 name 去重
db.user.distinct("name")find() 方法以非结构化方式来显示所有文档。
如果你需要以易读的方式来读取数据,可以使用 pretry() 方法,语法格式如下:
db.user.find().pretty()
pretty() 函数以格式化的方式来显示所有文档注:在MongoDB中,用到方法都得用 $ 符号开头
2、比较运算符
=、!= ('$ne')、> ('$gt')、< ('$lt')、>= ('$gte')、<= ('$lte')# 1、select * from user where id = 3
db.user.find({"id":3})
# 2、select * from user where id != 3
db.user.find({"_id":{"$ne":3}})
# 3、select * from user where id > 3
db.user.find({"_id":{"$gt":3}})
# 4、select * from user where id < 3
db.user.find({"_id":{"$lt":3}})
# 5、select * from user where id >= 3
db.user.find({"_id":{"$gte":3}})
# 6、select * from user where id <= 3
db.user.find({"_id":{"$lte":3}})3、逻辑运算
MongoDB 中字典内用逗号分隔多个条件是 and 关系,或者直接用 $and,$or,$not(与或非)
# 逻辑运算:$and,$or,$ont
# 1、select * from user where id >= and id <= 4;
db.user.find({"id":{"$gte":3,"$lte":4}})
# 2、select * from user where id >= 3 and id <= 4 and age >= 4;
db.user.find({
"_id":{"$gte":3,"$lte":4},
"age":{"$gte":4}
})
db.user.find({
"$and":[
{"_id":{"$gte":3,"$lte":4}},
{"age":{"$gte":4}}
]
})
# 3、select * from user where id >=0 and id <= 1 or id >=4 or name = "test"
db.user.find({
"$or":[
{"_id":{"$gte":0,"$lte":1}},
{"_id":{"$lte":4}},
{"name":"test"}
]
})
# 4、select * from user where id % 2 = 1;
db.user.find({"_id":{"$mod":[2,1]}})
# 5、select * from user where id % 2 != 1;
db.user.find({"_id":{"$not":{"$mod":[2,1]}}})4、$type 操作符
MongoDB 中可以使用的类型如下表所示:
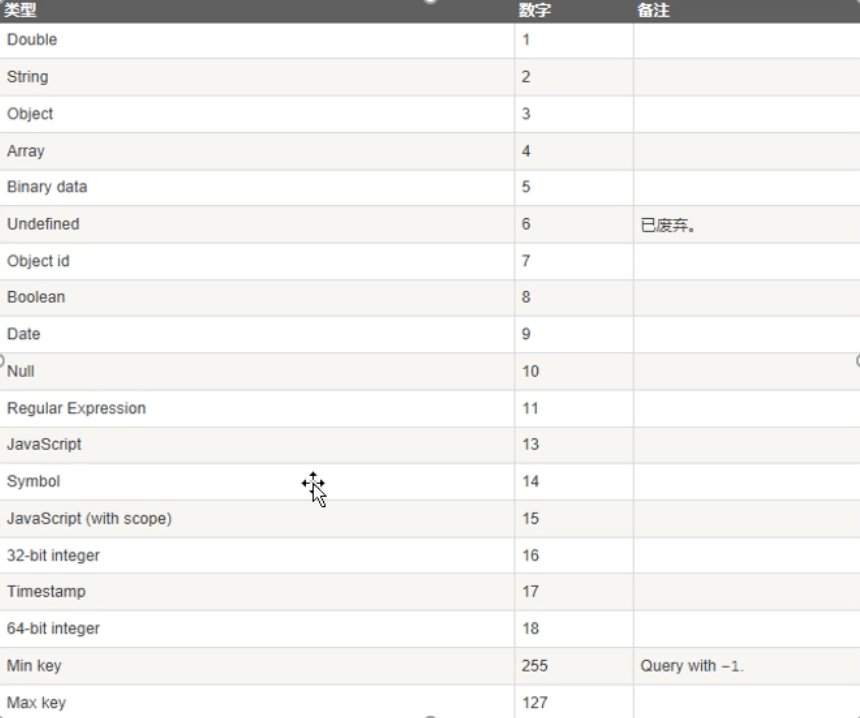
# 查询 name 是字符串类型的数据
db.user.find({name:{$type:2}}).pretty()5、正则
# 1、select * from user where name regexp '^z.*?(u|i)$'
# 匹配规则:z开头、n或u结尾,不区分大小写
db.user.find({name:/^z.*?(u|n)/i})6、投影
MongoDB 投影意思是只选择必要的数据而不是选择一整个文件的数据。
在 MongoDB 中,当执行 find()方法,那么它会显示一个文档所有字段。要限制这一点需要设置字段列表值 1 或 0
1 用来显示字段而 0 用来隐藏字段,_id 会默认显示出来。
# 1、select name,age from user where id = 3;
db.user.find({'_id':3},{'_id':0,'name':1,'age':1})
# 2、select name,age from user where name regexp "^z.*(n|u)$";
db.user.find({
"name":/^z.*(n|u)$/i
},
{
"_id":0,
"name":1,
"age":1
}
)7、数组
# 查询数组相关
# 查询 hobbies 中有 dancing 的人
db.user.find({
"hobbies":"dancing"
})
# 查看既有 dancing 爱好又有 tea 爱好的人
db.user.find({
"hobbies":{"all":["dancing","tea"]}
})
# 查看索引第二个爱好为 dancing 的人(索引从 0 开始计算)
db.user.find({
"hobbies.1":"dancing"
})
# 查看所有人的第1个到第3个爱好,第一个{}表示查询条件为所有,第二个是显示条件(左闭右开)
db.user.find(
{},
{
_id:0,
name:0,
age:0
addr:0
hobbies:{"$slice":[0,2]}
}
)
# 查看所有人的最后两个爱好,第一个{}表示查询条件为所有,第二个是显示条件(左闭右开)
db.user.find(
{},
{
_id:0,
name:0,
age:0
addr:0
hobbies:{"$slice":-2}
}
)
# 查询子文档有 "country":"China"的人
db.user.find(
{
"addr.country":"China"
}
)8、排序
在 MongoDB 中使用 sort() 方法来对数据排序, sort() 方法可以通过参数指定排序的字段,并使用 1 和 -1 来指定排序的方式,其中 1 为升序排序,而 -1 是用于降序排序
# 按照姓名正序
db.user.find().sort({name:1})
# 按照年龄到序序,id正序
db.user.find().sort({age:-1,_id:1})9、分页
limit 表示取多少个 document,skip代表跳过几个document
分页公式:db.user.find().skip((pageNumber-1)*pageSize).limit(pageSize)
db.user.find().limit(2).skip(0) # 前两个
db.user.find().limit(2).skip(2) # 第三个和第四个
db.user.find().limit(3).skip(4) # 第五个和第六个10、统计
# 查询 _id 大于 3 的人数
# 方式一
db.user.count({_id:{"$gt":3}})
# 方式二
db.user.find({_id:{"$gt":3}}).count()二、聚合
我们在查询时可定会用到聚合,在 MongoDB 中聚合为 aggregate,集合函数主要用到 $match $group $avg $project $concat,可以加"$match"也可以不加$match
2.1、Aggregate与法
基本格式:db.COLLECTION_NAME.aggregate(pipeline,options)参数说明
| 参数 | 类型 | 描述 |
|---|---|---|
| pipeline | array | 一系列数据聚合擦耦走或阶段。在版本 2.6 中更改:该方法仍然可以将流水线阶段作为单独的参数接受,而不是作为数组中的元素;但是,如果不将管道指定为数组,则不能指定 options 参数。目前所使用的 4.0.4 版本必须使用数组 |
| options | document | 可选。aggreate() 传递给聚合命令的其它选项,2.6 版本中新增功能:仅当将管道指定为数组时才可用 |
2.6 中的新增功能,仅当将管道指定为数组时才可用。
注意:使用 db.collection.aggregate() 直接查询会提示错误,但是传入一个空数组如 db.collection.aggregate([]) 则不会报错,且会和 find 一样返回所有文档。2.2、$match 和 $group
相当于 sql 语句中的 where 和 group by
{"$match":{"字段":"条件"}},可以使用任何常用的查询操作符 $gt,$lt,$in等
{"$group":{"_id":分组字段,"新的字段名":聚合操作符}}
# select * from db1.emp where post = "公务员"
db.emp.aggregate([{"$match":{"post":"公务员"}}])
# select * from db1.emp where id > 3 group by post;
db.emp.aggregate([
{"$match":{_id:{"$gt":3}}},
{"$group":{_id:"$post","avg_salary":{"$avg":"$salary"}}}
])
# select * from db1.emp where id > 3 group by post having avg(salary) > 10000;
db.emp.aggregate([
{"$match":{_id:{"$gt":3}}},
{"$group":{_id:"$post","avg_salary":{"$avg":"$salary"}}},
{"$match":{"avg_salary":{"$gt":10000}}}
])
{"$group":{_id:分组字段,"新的字段":聚合操作符}}
将分组字段传给 $group 函数的 _id 字段即可
{"$group":{_id:"$sex"}} # 按照性别分组
{"$group":{_id:"$post"}} # 按照职位分组
{"$group":{_id:{"state":"$state","city":"$city"}}} # 按照多个字段分组,比如按照州市分组
# 分组后聚合得结果,类似于 sql 中聚合函数的聚合操作符:$sum,$avg,$max,$min,$first,$last
# select post,max(salary) from db1.emp group by post;
db.emp.aggregate([{"$group":{_id:"$post","max_salary":{"$max":"$salary"}}}])
# 取每个部门最大薪资与最低薪资
db.emp.aggregate(["$group":{_id:"$post","max_salary":{"$max":"$salary"},"min_salary":{"$min":"$salary"}}])
# 如果字段是排序后的,那么 $first,$last 会很有用,比如$max 和 $min 效率高
db.emp.aggregate(["$group":{_id:"$post","first_id":{"$first":"$_id"}}}])
# 求每个部门的工资
db.emp.aggregate([{"$group":{_id:"$post","count":{"$sum":"$salary"}}},{"$sort":{"count":1}}])
# 求每个部门人数
db.emp.aggregate([{"$group":{_id:"$post","count":{"$sum":1}}},{"$sort":{"count":1}}])
# 数组操作符
{"$addToSet":expr} # 不重复
{"$push":expr} # 重复
# 查询岗位名以及各岗位的员工姓名:select post,group_concat(name) from db.emp group by post;
# 重复的也查询出来
db.emp.aggregate([{"$group":{_id:"$post","names":{"$push":"$name"}}}])
# 查询不重复的,如果有重复的保留一个
db.emp.aggregate([{"$group":{_id:"$post","names":{"$addToSet":"$name"}}}])2.3、$project
用于投射,即设定该该键值对是否保留,1为保留,0位不保留,可对原有键值对做操作后增加自定义表达式(查询哪些要显示的列)
{"$project":{"要保留的字段名":1,"要去掉的字段名":"0","新增字段名":" 表达式"}}
# select name,post,(age+1) as new_age from db1.emp;
db.emp.aggregate([
{
$project:{
"name":1,
"post:"1,
"new_age":{"$add":["$age",1]}
}
}
])2.4、$sort 和 $limit 和 $skip
排序:{"$sort":{"字段名称":1,"字段名":-1}} #1 升序,-1 降序
限制:{"$limit":n}
跳过:{"$skip":n} # 跳过多少个文档
# 取平均工资最高的前两个部门
db.emp.aggregate([
{
"$group":{_id:"$post","平均工资":{"$age":"$salary"}}
},
{
"$sort":{"平均工资":-1}
},
{
"$limit":2
}
])
# 取平均工资最高的第二个部门
db.emp.aggregate([
{
"$group":{_id:"$post","平均工资":{"$avg":"$salary"}}
},
{
"$sort":{"平均工资":-1}
},
{
"$limit":2
},
{
"$skip":1
}
])2.5、$sample
随机取几个:$sample
# 随机获取 3 个文档
db.emp.aggregate([
{$sample:{size:3}}
])2.6、$concat 和 $substr 和 $toLower 和 $toUpper
{"$substr":[$值为字符串的字段名,起始位置,截取几个字节]}
# 指定的表达式或字符串连接在一起返回,只支持字符串拼接
{"$concat":[expr1,expr2,...,exprN]}
{"$toLower":expr} # 转小写
{"$toUpper":expr} # 转大写
# 截取字符串
db.emp.aggregate([
{
$project:{
_id:0
"str":{$substr:["$sex",0,2]}
}
}
])
# 拼接
db.emp.aggregate([
{
$project:{
"name":1
"post":1,
"name_sex":{$concat:["$name","测试","$sex"]}
}
}
])
# 将性别的英文转为大写
db.emp.aggreagate([$project:{"sex":{"$toUpper":"$sex"}}])本作品采用《CC 协议》,转载必须注明作者和本文链接





 关于 LearnKu
关于 LearnKu



