
爬取网页文章
0 / 0 / 创建于 4年前
 charliecen 的个人博客
charliecen 的个人博客
最近写了一个爬取网易养生的一些文章,只爬取首页,暂时没有翻页。后续有空再更新吧,下面是代码:
爬虫代码
import requests
from lxml import etree
from config import db
import urllib.request
import re, os, uuid, time
def run():
data = parse()
insert(data)
# 解析页面
def parse():
url = 'https://jiankang.163.com/special/yangsheng_n/?1'
res = requests.get(url)
if res.status_code == 200:
print("请求成功")
else:
print("请求失败")
return
html = etree.HTML(res.content)
news_list = html.xpath('//div[@class="news_one havepic"]')
data = []
if news_list:
for news in news_list:
# 内容链接
content_url = news.xpath('./div[@class="news_main_info"]/h2/a/@href')[0]
# print(content_url)
content = source = ''
# 内容获取
if content_url:
res_content = requests.get(content_url)
# res_content.encoding = 'ISO-8859-1'
if res_content.status_code == 200:
print("请求内容成功")
else:
print("请求内容失败")
return
content_html = etree.HTML(res_content.content)
# 文章来源
article_source = content_html.xpath('//div[@class="post_main"]/div[@class="post_info"]/text()')[0] \
.strip().encode('iso-8859-1').decode('utf-8')
source_list = article_source.split(':')
source = source_list[-1].strip()
# return
# 文章内容
article_content = content_html.xpath('//div[@class="post_main"]/div[@class="post_content"]/div['
'@class="post_body"]/p')
# 内容合并
if article_content:
for p in article_content:
# 判断内容是否有图片
images = p.xpath('./img/@src')
if images is not None and len(images) > 0:
# pass
# 下载图片
filePaths = download_img(images)
if filePaths is not None and len(filePaths) > 0:
for file in filePaths:
content += '<img src="' + file + '">'
# 内容获取
text = p.xpath('./text() | ./a/text()')
# 大于1,则说明有a标签
if len(text) > 1:
p_text = ''.join(text)
elif text is not None and len(text) == 1:
p_text = text[0]
else:
p_text = ''
content += p_text.strip().encode('iso-8859-1').decode('utf-8') + "\n"
source_img = news.xpath('./div[@class="news_main_info"]/a/img/@src')
local_img = download_img(source_img)[0]
# 文章数据
article = {
# 标题
'title': news.xpath('./div[@class="news_main_info"]/h2/a/text()')[0],
# 链接
'link': news.xpath('./div[@class="news_main_info"]/h2/a/@href')[0],
# 图片
'source_img': source_img[0],
# 副标题
'sub_title': news.xpath('./div[@class="news_main_info"]/p/text()')[0].strip(),
# 标签
'tags': news.xpath('./div[@class="news_sub_info"]/p[@class="keywords"]/a/text()'),
# 发布时间
'publish_time': news.xpath('./div[@class="news_sub_info"]/p[@class="pubtime"]/text()')[0].strip(),
# 来源, 爬取网站的地址
'source': news.xpath('./div[@class="news_sub_info"]/div[@class="news_share"]/ul/@data-source')[0],
# 内容
'content': content,
# 真实来源, 爬取网站内容的源地址
'real_source': source,
# 本地地址
'local_img': local_img,
# 远程地址
'oss_img': '',
}
data.append(article)
return data
# 插入文章和标签
def insert(data):
DB = db.DB()
cur = DB.cursor()
tags_field = {'article_id', 'name', 'status'}
tags_value = data[0]['tags']
del data[0]['tags']
# 字段
field = ', '.join('`{}`'.format(k) for k in data[0].keys())
# 值
values = ', '.join('%({})s'.format(k) for k in data[0].keys())
for j, i in enumerate(data):
# 先插入文章
# 判断文章是否存在
sql_exists = "select id from dl_articles where title = '%s'" % (i.get('title'))
print(sql_exists)
cur.execute(sql_exists)
# 存在记录,则直接跳过
if len(cur.fetchall()) > 0:
print("文章已存在")
continue
# return
# 插入文章记录
insert_article_sql = "insert into %s (%s) values (%s)" % ('dl_articles', field, values)
try:
cur.execute(insert_article_sql, i)
DB.commit()
print("插入文章成功")
except Exception as e:
print("插入文章失败")
print(str(e))
DB.rollback()
return
# 插入文章的id
article_id = cur.lastrowid
# 文章id小于1,则插入失败
if article_id < 1:
continue
# 插入tags
if j == 0:
tags = tags_value
else:
tags = i.get('tags')
if len(tags) > 0:
for t in tags:
select_tags_sql = "select id from dl_tags where `article_id` = %s and `name` = '%s'" % (article_id, t)
print(select_tags_sql)
# return
try:
cur.execute(select_tags_sql)
tag_ids = cur.fetchall()
except Exception as e:
print("查询标签失败")
print(str(e))
return
# 已存在文章对应的标签
if len(tag_ids) > 0:
continue
# 插入标签
insert_tags_sql = "insert into %s (`article_id`, `name`, `status`) values %s" % (
'dl_tags', (article_id, t, 0))
print(insert_tags_sql)
# return
try:
cur.execute(insert_tags_sql)
DB.commit()
print("插入标签成功")
except Exception as e:
print("插入标签失败")
print(str(e))
DB.rollback()
# 下载图片
def download_img(images):
data = []
ym = time.strftime("%Y%m", time.localtime())
d = time.strftime("%d", time.localtime())
path = './download/images/' + ym + '/' + d
if not os.path.exists(path):
os.makedirs(path)
suffix_list = ['jpg', 'png', 'jpeg']
suffix = 'jpg'
if type(images) == list and len(images) > 0:
for img in images:
print(img)
for s in suffix_list:
if re.search(s, img):
suffix = s
break
uid = str(uuid.uuid4())
filename = uid + '.' + suffix
filepath = path + '/' + filename
urllib.request.urlretrieve(img, filepath)
data.append(filepath)
return data
执行代码
> python .\main.py
请求成功
请求内容成功
http://cms-bucket.ws.126.net/2021/0929/0128808cj00r0647z000mc0009c0070c.jpg?imageView&thumbnail=150y100
请求内容成功
https://nimg.ws.126.net/?url=http%3A%2F%2Fcms-bucket.ws.126.net%2F2021%2F0928%2F6734e010j00r04eeu00kpc000k0032dc.jpg&thumbnail=660x2147483647&quality=80&type=jpg
http://cms-bucket.ws.126.net/2021/0928/9027cb39j00r04egc000qc0009c0070c.jpg?imageView&thumbnail=150y100
请求内容成功
http://cms-bucket.ws.126.net/2021/0926/b982d3aaj00r01tgi000nc0009c0070c.jpg?imageView&thumbnail=150y100
请求内容成功
http://cms-bucket.ws.126.net/2021/0925/a96809c3j00qzzq84000pc0009c0070c.jpg?imageView&thumbnail=150y100
请求内容成功
http://cms-bucket.ws.126.net/2021/0924/6cff9112j00qzx3np001ac0009c0070c.jpg?imageView&thumbnail=150y100
请求内容成功
http://cms-bucket.ws.126.net/2021/0923/7c8f7b5bj00qzvkee000sc0009c0070c.jpg?imageView&thumbnail=150y100
请求内容成功
http://cms-bucket.ws.126.net/2021/0923/86cdbf99j00qzv050000jc0009c0070c.jpg?imageView&thumbnail=150y100
请求内容成功
http://cms-bucket.ws.126.net/2021/0922/11309378j00qzt3ny002yc0009c0070c.jpg?imageView&thumbnail=150y100
请求内容成功
https://nimg.ws.126.net/?url=http%3A%2F%2Fcms-bucket.ws.126.net%2F2021%2F0917%2F02364e55j00qzl25900dec000k001vgc.jpg&thumbnail=660x2147483647&quality=80&type=jpg
http://cms-bucket.ws.126.net/2021/0917/b6c35977j00qzl26s0011c0009c0070c.jpg?imageView&thumbnail=150y100
请求内容成功
http://cms-bucket.ws.126.net/2021/0916/0679e91fp00qzj54e001rc0009c0070c.png?imageView&thumbnail=150y100
select id from dl_articles where title = '记好这些要诀,不吃安眠药也能睡个好觉'
插入文章成功
select id from dl_tags where `article_id` = 1 and `name` = '安眠药'
insert into dl_tags (`article_id`, `name`, `status`) values (1, '安眠药', 0)
插入标签成功
select id from dl_tags where `article_id` = 1 and `name` = '失眠'
insert into dl_tags (`article_id`, `name`, `status`) values (1, '失眠', 0)
插入标签成功
...图片存储
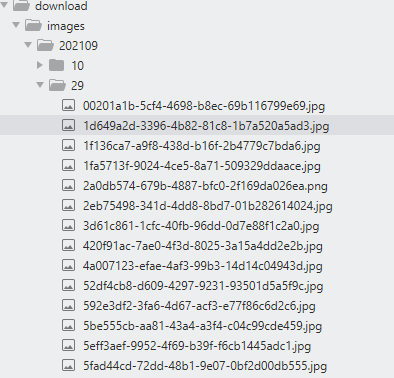
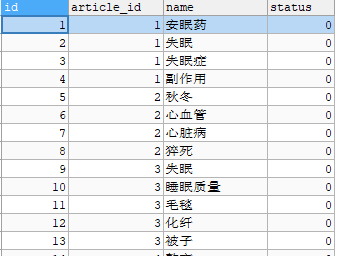
文章存储

标签存储
本作品采用《CC 协议》,转载必须注明作者和本文链接






 关于 LearnKu
关于 LearnKu




推荐文章: