
一致性hash算法的一些理解
0 / 0 / 创建于 4年前 /
 kolin 的个人博客
kolin 的个人博客
之前对hash算法的认识就是 传一个key进去 然后计算出来一个值,还有就是nginx负载均衡策略中的ip_hash跟url_hash,也大概是传一个值进去算一个值出来,直到后来同学问了我一句,nginx的ip_hash算出来一个node1,那如果这个node掉线了,nginx会将这个请求打到其他可用节点上么?
基于上面这个问题 后来了解到了一致性hash算法,百度了一些相关文章后,下面基于查阅到的资料说下自己的理解。
百度上说一致性hash算法应该满足4个适应条件:
- 均衡性(平衡性)
- 单调性
- 分散性
- 负载
看完上面几个你可能也还一脸懵,没关系 我当时也是 下面来看一些具体的设计 看完你就懂了~
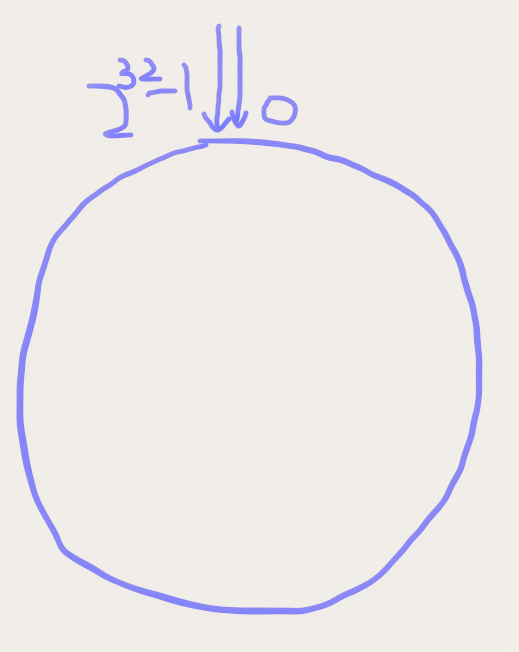
1、环形的hash空间
按照常用的hash算法来将对应的key哈希到一个具有2^32次方个节点的空间中,即0 ~ (2^32)-1的数字空间中。现在我们可以将这些数字头尾相连,想象成一个闭合的环形。大概是下面这样:
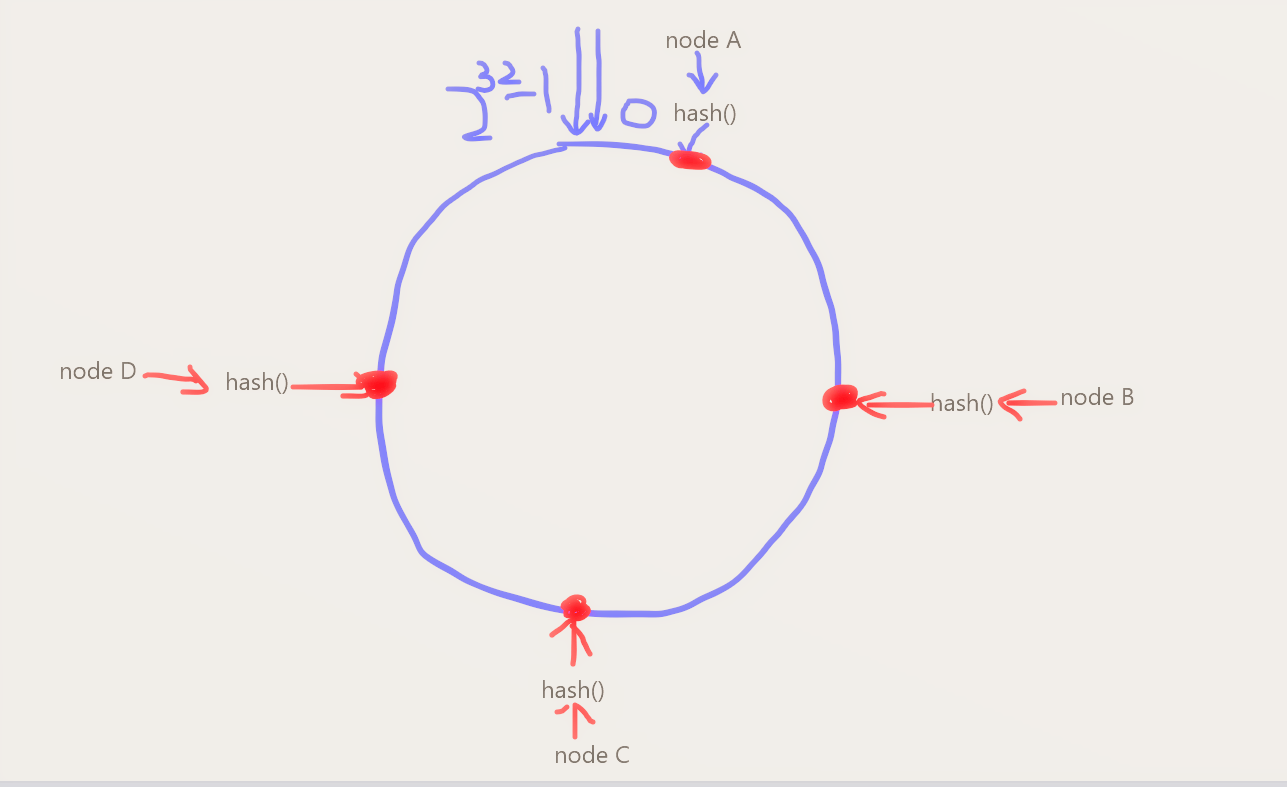
2、映射服务器节点
将服务器使用hash计算出一个值,具体可以使用服务器ip或一个唯一的主机名,这样每台机器就能在hash环上有一个确定的位置,下面是模拟了4台服务器在hash环上的落点:
3、映射请求
下面我们将RequestA,RequestB,RequestC,RequestD四个请求按照特定的hash函数计算出一个值,然后也分布到哈希环上,下面是示例:
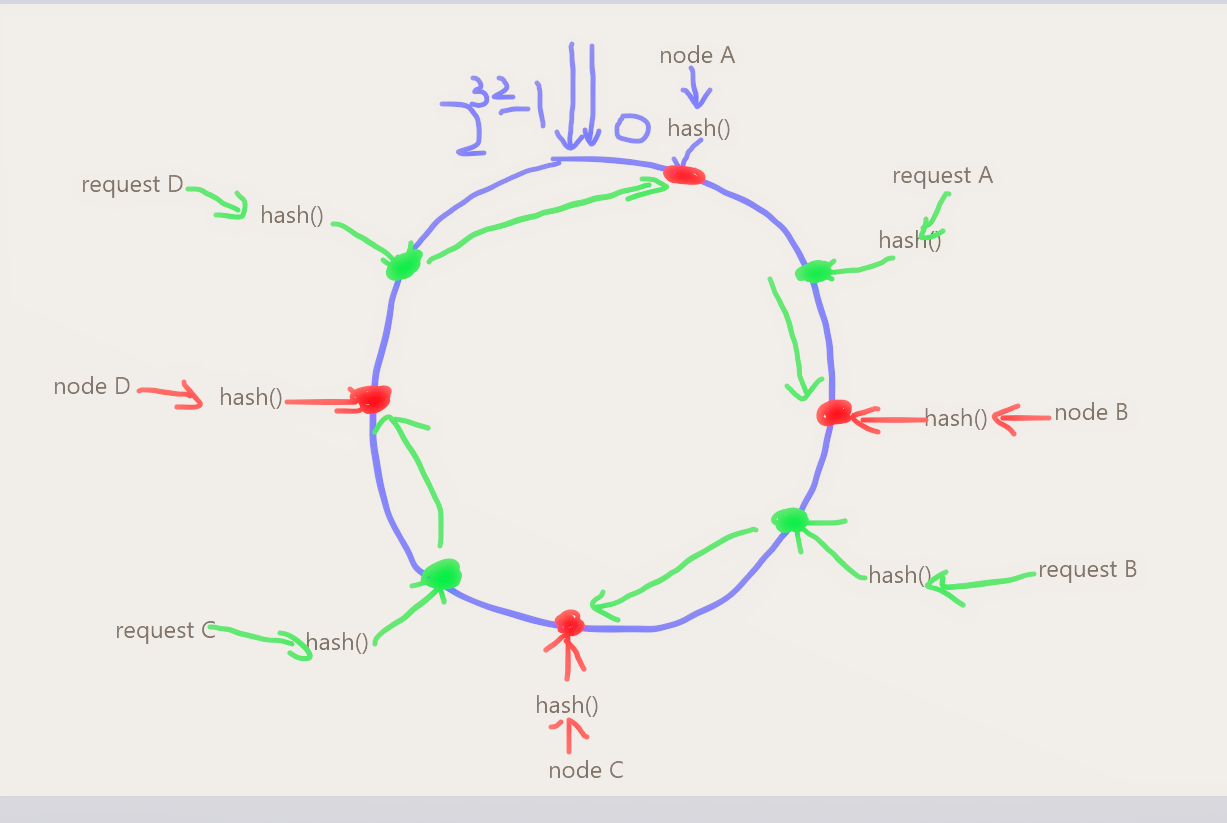
然后四个小绿点就从所在位置开始顺时针转,遇到的第一个服务器节点就是它应该定位到的服务器节点。
此时如果某个节点下线了,请求也能根据顺时针走向找到下一个可用的服务器节点。
4、虚拟节点
可以想象一下,当我们的服务器节点比较少时,那么就不可避免的会造成大量的请求向某一个节点倾斜,也就是失去了平衡性,所以一致性哈希算法引入了虚拟节点机制,也就是对每一个服务器节点多计算出几个hash值,计算出来的这些虚拟子节点也会分布到环上,但实际请求的时候还是会找到它对应真实存在的父节点,模拟出一种服务器节点很多的感觉,这样就解决了服务节点少时数据倾斜的问题。每个物理节点关联的虚拟节点数量就根据具体的生产环境情况在确定。
参考文章:https://zhuanlan.zhihu.com/p/98030096
本作品采用《CC 协议》,转载必须注明作者和本文链接





 关于 LearnKu
关于 LearnKu




推荐文章: