
笔记 - 深入理解GPM模型
2 / 0 / 创建于 4年前 /
 ChenAfrica 的个人博客
ChenAfrica 的个人博客
线程模型
在现代操作系统中,线程是处理器调度和分配的基本单位,进程作为资源拥有的基本单位,每个进程是由私有的虚拟地址空间、代码、数据和其他系统资源组成。线程是进程内部的一个执行单元。每一个进程至少有一个主执行线程,它无需由用户去主动创建,是由系统自动创建的。用户根据需要在应用程序中创建其它线程,多个线程并发地运行于同一个进程中。
无论语言层面何种并发模型,到了操作系统层面,一定是以线程的形态存在的。而操作系统根据资源访问权限不同,体系架构可分为用户空间和内核空间;内核空间主要操作访问CPU资源、I/O资源、内存资源等硬件资源,为上层应用程序提供最基本资源,用户空间呢就是上层应用程序的固定活动空间,用户空间不可以直接访问资源,必须通过“系统调用”、“库函数”活“Shell脚本”来调用内核空间提供的资源
线程可以视为进程中的控制流,一个进程至少会包括一个线程,因为其中至少会有一个控制流持续运行。因而,一个进程的第一个线程会随着这个进程的启动而创建,这个线程称为该进程的主线程。当然一个进程也可以包含多个线程。这些线程都是由当前今晨中已存在的线程创建出来的,并且即使某个或某些任务被阻塞,也不会影响其他其他任务正常执行,这可以大大改善程序的响应时间和吞吐量。另一方面,线程不可能独立进程存在。它的生命周期不可能逾越其所属进程的生命周期。
线程的实现模型主要有3个,分别是:用户级线程模型、内核级线程模型和两级线程模型。他们之间最大的差异就在于线程与内核调度实体之间的对应关系上。顾名思义,内核调度实体是可以被内核的调度器调度的对象。在很多文献和书中,它也称为内核级线程,是操作系统内核的最小调度单元。
- 内核级线程模型
用户线程与KES是一对一的关系,大部分变成语言的线程库(如linux的pthread,java的java.lang,Thread,C++11的std::thread等等)都是对操作系统的线程的一层封装,创建出来的每个线程与一个不同的KSE静态关联,因此其调度完全由调度器来做。这种方式实现简单,直接借助OS提供的线程能力,并且不同用户线程之间一般也不会相互影响,但其创建,销毁以及多个线程之间的上下文切换等操作都是直接由OS层面亲自来做,在需要使用大量线程的场景下对OS的性能影响会大。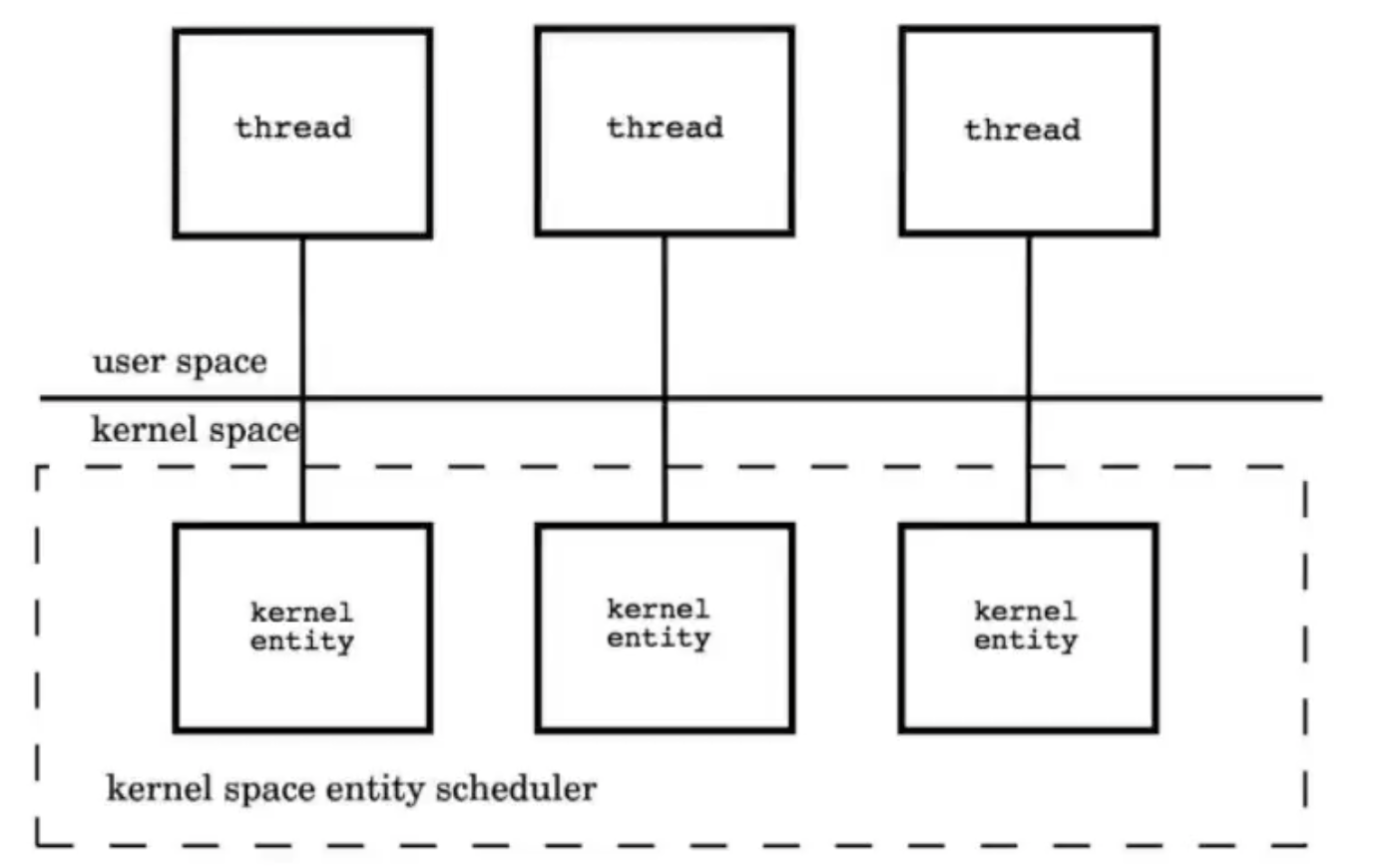
- 用户级线程模型
用户线程与KSE是多对1关系(M:1),这种线程的创建,销毁以及多个线程之间的协调等操作都是由用户自己实现的线程库来负责,对OS内核透明,一个进程中所有创建的线程都与同一个KSE在运行时动态关联。现在有许多语言实现的 协程 基本上都属于这种方式。这种实现方式相比内核级线程可以做的很轻量级,对系统资源的消耗会小很多,因此可以创建的数量与上下文切换所花费的代价也会小得多。但该模型有个致命的缺点,如果我们在某个用户线程上调用阻塞式系统调用(如用阻塞方式read网络IO),那么一旦KSE因阻塞被内核调度出CPU的话,剩下的所有对应的用户线程全都会变为阻塞状态(整个进程挂起)。 所以这些语言的协程库会把自己一些阻塞的操作重新封装为完全的非阻塞形式,然后在以前要阻塞的点上,主动让出自己,并通过某种方式通知或唤醒其他待执行的用户线程在该KSE上运行,从而避免了内核调度器由于KSE阻塞而做上下文切换,这样整个进程也不会被阻塞了。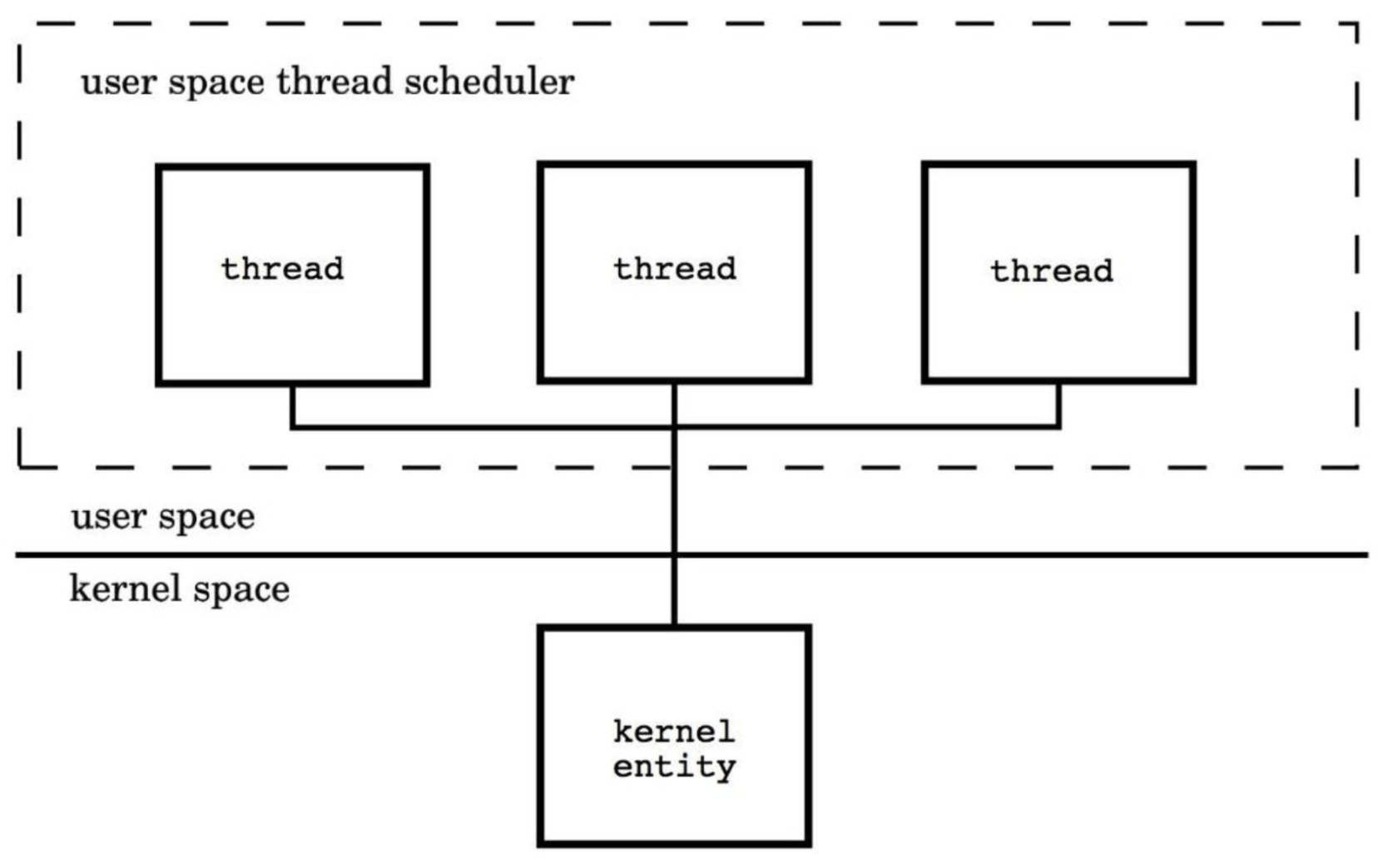
- 两级线程模型
用户线程与KSE是多对多关系(M:N),这种实现综合了前两种模型的优点,为一个进程中创建多个KSE,并且线程可以与不同的KSE在运行时进行动态关联,当某个KSE由于其上工作的线程的阻塞操作被内核调度出CPU时,当前与其关联的其余用户线程可以重新与其他KSE建立关联关系。当然这种动态关联机制的实现很复杂,也需要用户自己去实现,这算是它的一个缺点吧。Go语言中的并发就是使用的这种实现方式,Go为了实现该模型自己实现了一个运行时调度器来负责Go中的”线程”与KSE的动态关联。此模型有时也被称为 混合型线程模型,即用户调度器实现用户线程到KSE的“调度”,内核调度器实现KSE到CPU上的调度。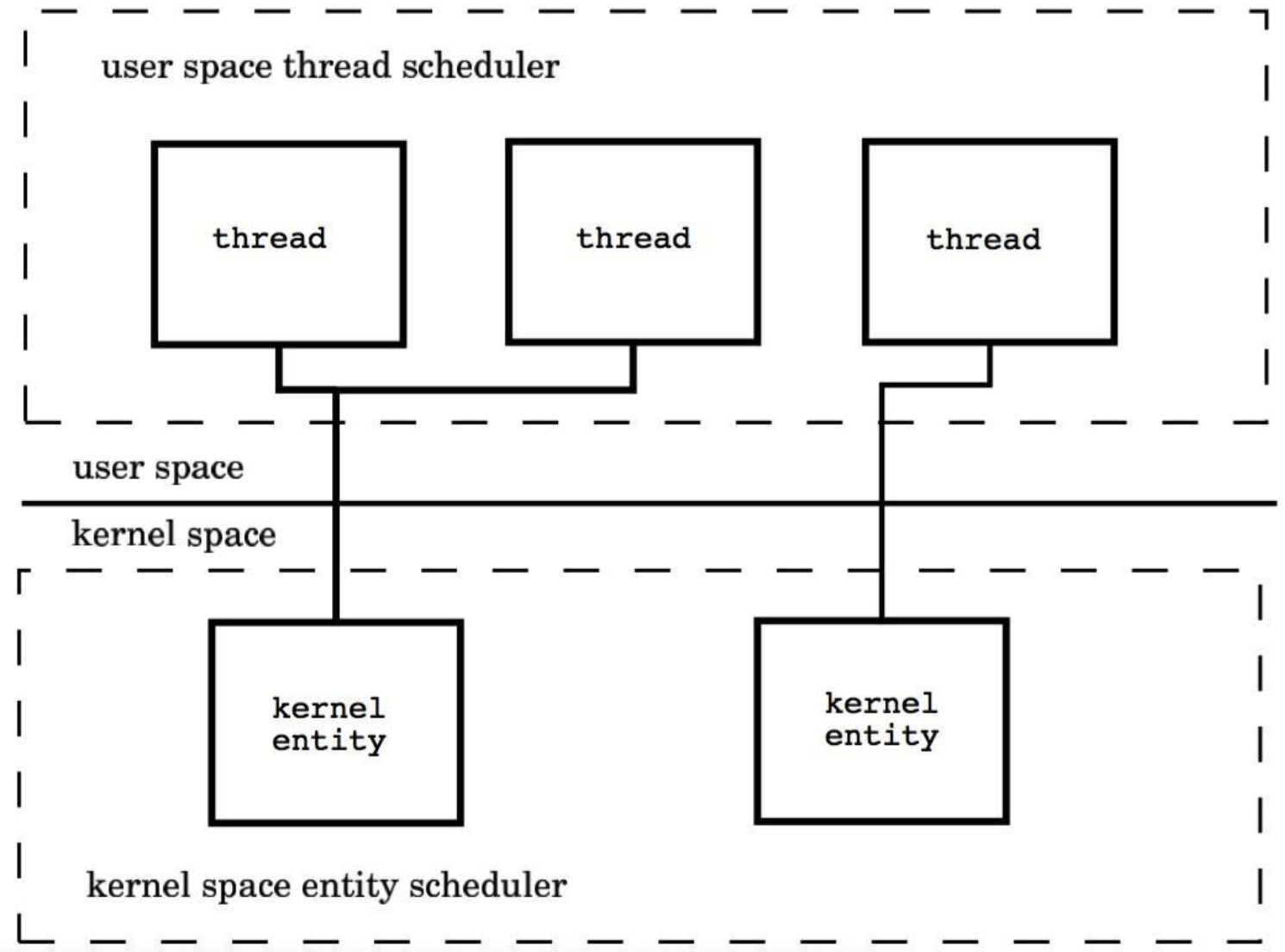
Go并发调度: G-P-M模型
在操作系统提供的内核线程之上,Go搭建了一个特有的两级线程模型。goroutine机制实现了M:N的线程模型,goroutine机制是协程(coroutine)的一种实现,golang内置调度器,可以让多核CPU中每个CPU执行一个协程。
- 调度器是如何工作的
理解goroutine机制的原理,关键是理解Go语言schedule的实现
Go语言中支撑整个scheduler实现的主要有4个重要结构,分别是M、G、P、Sched,前三个定义在runtime.h中,Sched定义在proc.c中。
- Sched结构是调度器,它维护有存储M和G的队列以及调度器的一些状态信息等
- M结构是Machine,系统线程,它由操作系统管理的,goroutine就是跑在M之上的;M是一个很大的结构,里面维护小对象内存cache(mcache)、当前执行的goroutine、随机数发生器等等非常多的信息。
- P结构是Processor,处理器,它的主要用途就是用来执行goroutine的,它维护了一个goroutine队列,即runqueue。Processor是让我们从N:1调度到M:N调度的重要部分。
- G是goroutine实现的核心结构,它包含了栈,指令指针,以及其他对调度goroutine很重要的信息,例如其阻塞的channel。
在单核处理器的场景下,所有goroutine运行在同一个M系统线程中,每一个M系统线程维护一个Processor,任何时刻,一个Processor中只有一个goroutine,其他goroutine在runqueue中等待。一个goroutine运行完自己的时间片后,让出上下文,回到runqueue中。 多核处理器的场景下,为了运行goroutines,每个M系统线程会持有一个Processor。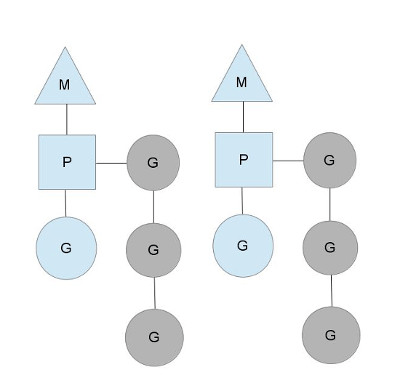
在正常情况下,scheduler会按照上面的流程进行调度,但是线程会发生阻塞等情况,看一下goroutine对线程阻塞等的处理。
- 线程阻塞
当正在运行的goroutine阻塞的时候,例如进行系统调用,会再创建一个系统线程(M1),当前的M线程放弃了它的Processor,P转到新的线程中去运行。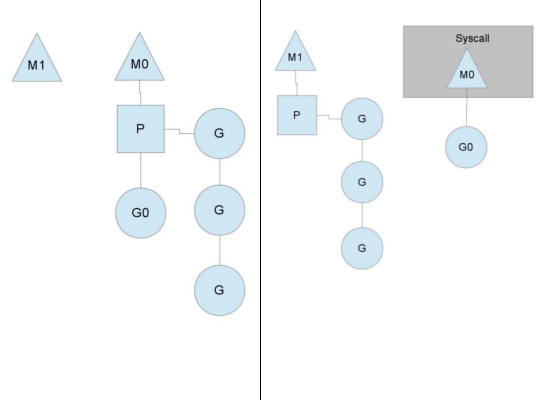
- runqueue
当其中一个Processor的runqueue为空,没有goroutine可以调度。它会从另外一个上下文偷取一半的goroutine。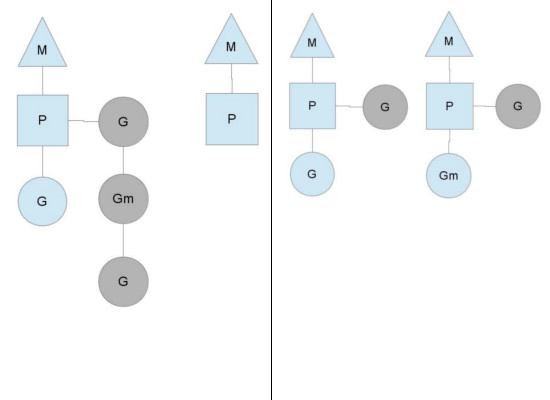
其图中的G,P和M都是Go语言运行时系统(其中包括内存分配器,并发调度器,垃圾收集器等组件,可以想象为Java中的JVM)抽象出来概念和数据结构对象: G:Goroutine的简称,上面用go关键字加函数调用的代码就是创建了一个G对象,是对一个要并发执行的任务的封装,也可以称作用户态线程。属于用户级资源,对OS透明,具备轻量级,可以大量创建,上下文切换成本低等特点。 M:Machine的简称,在linux平台上是用clone系统调用创建的,其与用linux pthread库创建出来的线程本质上是一样的,都是利用系统调用创建出来的OS线程实体。M的作用就是执行G中包装的并发任务。Go运行时系统中的调度器的主要职责就是将G公平合理的安排到多个M上去执行。其属于OS资源,可创建的数量上也受限了OS,通常情况下G的数量都多于活跃的M的。 P:Processor的简称,逻辑处理器,主要作用是管理G对象(每个P都有一个G队列),并为G在M上的运行提供本地化资源。
本作品采用《CC 协议》,转载必须注明作者和本文链接





 关于 LearnKu
关于 LearnKu




推荐文章: