
TiDBv6.0与TiDBv5.1.2 TiKV 节点重启后 leader 平衡加速,提升业务恢复速度对比测试
21 / 0 / 创建于 1年前
 TiDBCommunityTechPortal 的个人博客
TiDBCommunityTechPortal 的个人博客
1.目标:
试用TiDB v5.1.2与TiDB v6.0.0 TiKV 节点重启后 leader 平衡加速,提升业务恢复速度对比
2.硬件配置:
| 角色 | cup/内存/硬盘 | |
|---|---|---|
| TiDB&PD | 16核/16G内存 /SSD200G | 3台 |
| TiKV | 16核/32G内存 /SSD500G | 3台 |
| Monitor | 16核/16G内存/ SSD50G | 1台 |
3.拓扑文件配置
TiDBv5.1.2拓扑文件参数配置
server_configs:
pd:
replication.enable-placement-rules: true
tikv:
server.grpc-concurrency: 8
server.enable-request-batch: false
storage.scheduler-worker-pool-size: 8
raftstore.store-pool-size: 5
raftstore.apply-pool-size: 5
rocksdb.max-background-jobs: 12
raftdb.max-background-jobs: 12
rocksdb.defaultcf.compression-per-level: ["no","no","zstd","zstd","zstd","zstd","zstd"]
raftdb.defaultcf.compression-per-level: ["no","no","zstd","zstd","zstd","zstd","zstd"]
rocksdb.defaultcf.block-cache-size: 12GB
raftdb.defaultcf.block-cache-size: 2GB
rocksdb.writecf.block-cache-size: 6GB
readpool.unified.min-thread-count: 8
readpool.unified.max-thread-count: 16
readpool.storage.normal-concurrency: 12
raftdb.allow-concurrent-memtable-write: true
pessimistic-txn.pipelined: true
tidb:
prepared-plan-cache.enabled: true
tikv-client.max-batch-wait-time: 2000000TiDBv6.0.0拓扑文件参数配置
只比TiDBv5.1.2拓扑文件参数配置多了storage.reserve-space: 0MB,可以忽略这个参数的设置
server_configs:
pd:
replication.enable-placement-rules: true
tikv:
server.grpc-concurrency: 8
server.enable-request-batch: false
storage.scheduler-worker-pool-size: 8
raftstore.store-pool-size: 5
raftstore.apply-pool-size: 5
rocksdb.max-background-jobs: 12
raftdb.max-background-jobs: 12
rocksdb.defaultcf.compression-per-level: ["no","no","zstd","zstd","zstd","zstd","zstd"]
raftdb.defaultcf.compression-per-level: ["no","no","zstd","zstd","zstd","zstd","zstd"]
rocksdb.defaultcf.block-cache-size: 12GB
raftdb.defaultcf.block-cache-size: 2GB
rocksdb.writecf.block-cache-size: 6GB
readpool.unified.min-thread-count: 8
readpool.unified.max-thread-count: 16
readpool.storage.normal-concurrency: 12
raftdb.allow-concurrent-memtable-write: true
pessimistic-txn.pipelined: true
storage.reserve-space: 0MB
tidb:
prepared-plan-cache.enabled: true
tikv-client.max-batch-wait-time: 20000004.TiUP部署TiDBv5.1.2和TiDBv6.0.0
5.测试TiKV 节点重启后 leader 平衡时间方法
给集群TiDBv5.1.2和TiDBv6.0.0插入不同数据(分别是100万,400万,700万,1000万),并查看TiKV 节点重启后 leader平衡时间
sysbench oltp_common
--threads=16
--rand-type=uniform
--db-driver=mysql
--mysql-db=sbtest
--mysql-host=$host
--mysql-port=$port
--mysql-user=root
--mysql-password=password
prepare --tables=16 --table-size=10000000通过以下这种方式查询表数据:
select
(select count(1) from sbtest1) "sbtest1",
(select count(1) from sbtest2) "sbtest2",
(select count(1) from sbtest3) "sbtest3",
(select count(1) from sbtest4) "sbtest4",
(select count(1) from sbtest5) "sbtest5",
(select count(1) from sbtest6) "sbtest6",
(select count(1) from sbtest7) "sbtest7",
(select count(1) from sbtest8) "sbtest8",
(select count(1) from sbtest9) "sbtest9",
(select count(1) from sbtest10) "sbtest10",
(select count(1) from sbtest11) "sbtest11",
(select count(1) from sbtest12) "sbtest12",
(select count(1) from sbtest13) "sbtest13",
(select count(1) from sbtest14) "sbtest14",
(select count(1) from sbtest15) "sbtest15",
(select count(1) from sbtest16) "sbtest16"
FROM dual等待插入完成后,查看Grafana监控下PD->Statistics-balance->Store leader count 各个TiKV leader 平均后,重启其中一台TiKV, 通过Grafana监控图表中Store leader count看leader平衡时间,如下图:
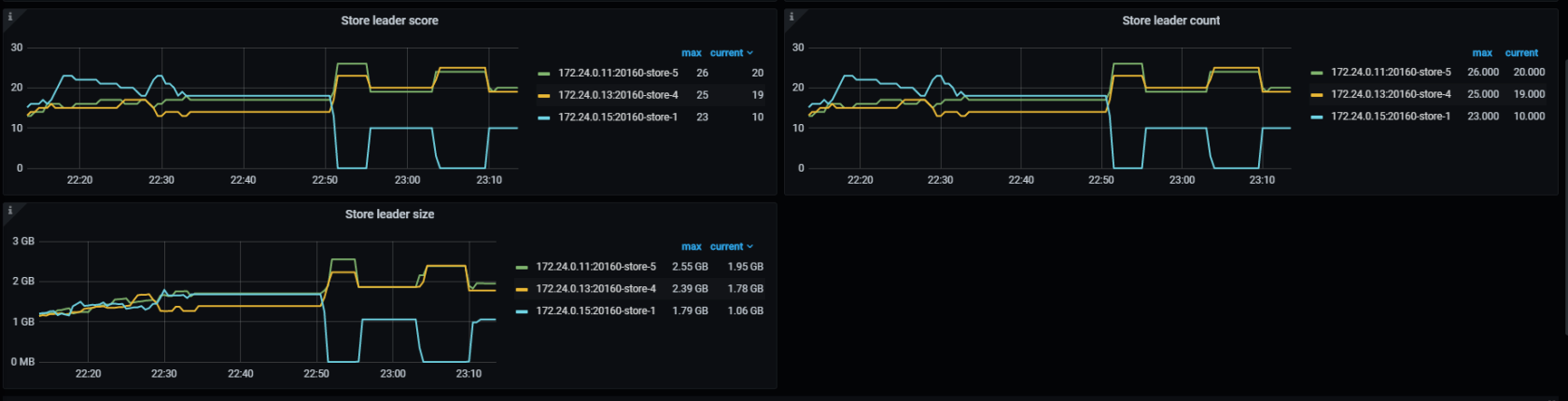
注:
重启可以通过systemctl stop tikv-20160.service和systemctl start tikv-20160.service模拟实现6.测试结果
对比数据图
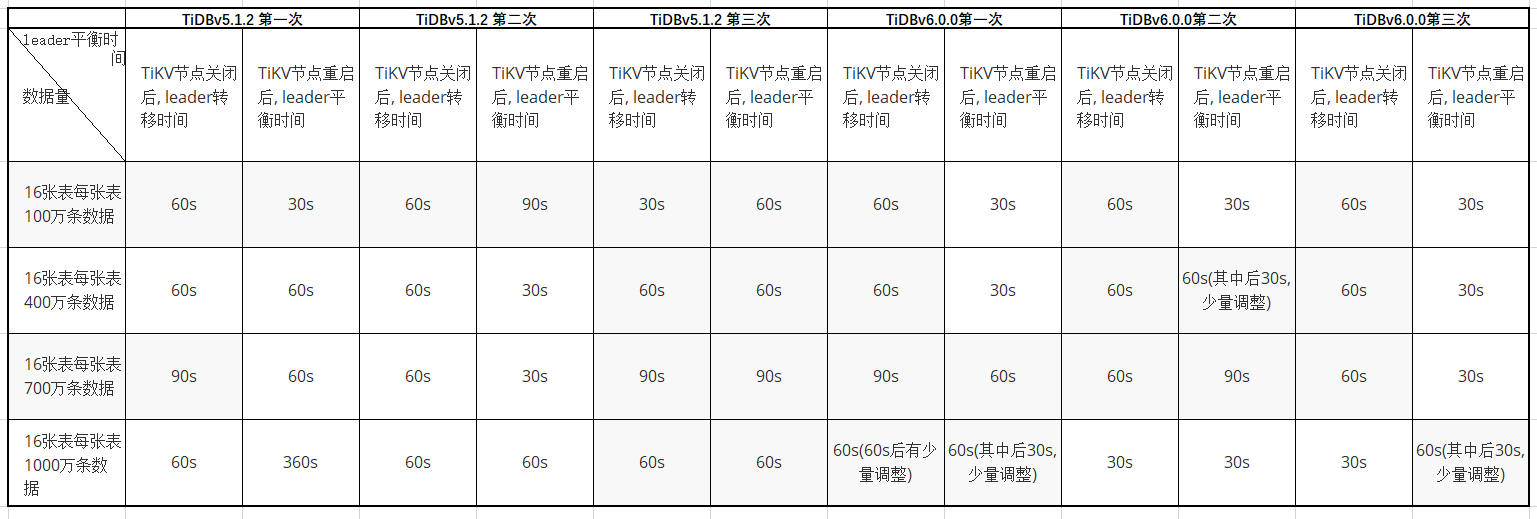
从表中对比数据得到:
1.大体上确实是TiDBv6.0 TiKV 节点重启后 leader 平衡加速了,比TiDBv5.1.2快了进30s。
2.从表中的数据看到:TiDBv6.0 TiKV 节点重启后,不管数据多少基本30s就完成了leader 平衡。
2.从表中也可以看到,TiDBv6.0 leader 平衡完了后,也会出现少量leader调整,这种情况少有。
3.TiDBv6.0 TiKV关闭后,leader 平衡时间基本上与TiDBv5.1.2没变化。
以上TiDB v5.1.2与TiDB v6.0.0 TiKV 节点重启后 leader 平衡加速, 提升业务恢复速度的对比,是没有修改balance-leader-scheduler 策略的情况下做的,可以看到默认情况下是有提升的,如想要获取更大的加速效果,请按以下操作:
1.通过PD Control调整集群参数。
2.scheduler config balance-leader-scheduler介绍
用于查看和控制 balance-leader-scheduler 策略。
从 TiDB v6.0.0 起,PD 为 balance-leader-scheduler 引入了 Batch 参数,用于控制 balance-leader 执行任务的速度。你可以通过 pd-ctl 修改 balance-leader batch 配置项设置该功能。
在 v6.0.0 前,PD 不带有该配置(即 balance-leader batch=1)。在 v6.0.0 或更高版本中,balance-leader batch 的默认值为 4。如果你想为该配置项设置大于 4 的值,你需要同时调大 scheduler-max-waiting-operator(默认值 5)。同时调大两个配置项后,你才能体验预期的加速效果。
>> scheduler config balance-leader-scheduler set batch 3 // 将 balance-leader 调度器可以批量执行的算子大小设置为 3参考文档:docs.pingcap.com/zh/tidb/v6.0/pd-c...
原文链接:tidb.net/blog/0cbf5031 原文作者:@ngvf
本作品采用《CC 协议》,转载必须注明作者和本文链接


 关于 LearnKu
关于 LearnKu




推荐文章: