
redis 存储结构原理 1
0 / 0 / 创建于 4年前 /
 阿兵云原生 的个人博客
阿兵云原生 的个人博客
关于 redis 相信大家都不陌生了,之前有从 0 -1 分享过 redis 的基本使用方式,用起来倒是都没有啥问题了,不过还是那句话,会应用之后,我们必须要究其原理,知其然知其所以然
今天我们来分享一下关于 redis 的存储结构的原理
redis 的存储结构的原理
我们都知道 redis 是一个 K-V 内存数据库,类似于 memcache ,那么一般存储这种 K-V 键值对的数据结构是什么呢?
是 红黑树 , 那么我们对于红黑树的增删改查的时间复杂度是 O(logN),对于红黑树而言,只要内存足够,那么这个 N 是可以无限大的
这对于 redis 来说是没有办法满足 redis 的需求,那么我们是否可以将复杂度降低到 O(1) 呢,感兴趣的,我们可以来探索一下?

hash 表
能满足 O(1) 时间复杂度的数据结构有啥呢?我们是不是可以想到 hash 表
具体 hash 表是怎样的一种结构,前面有文章已经分享过一些,redis 基础性的数据结构可以查看历史文章:【Redis 系列】redis 学习四,set 集合,hash 哈希,zset 有序集合初步
redis 的 key 支持哪些类型?
redis 支持的 key 有:
- long
- double
- int
- string - 可见的字符串和二进制字符串,key 都是 string 类型
实际上最终到 redis 处理的时候,上述类型,都是对应按照 sring 类型进行存储的
这个 key 是有规律的 key,并且是强随机性的
redis 的 value 支持哪些类型?
- string
- list
- set
- zset
- hash
- Geospatial 地理位置
- Hyperloglog 基数统计
- Bitmap 位图场景
我们知道 O(1) 的索引时间复杂度,数组就是一个很好的例子,我们访问数组元素的时候,直接通过下标访问即可
那么对应 hash 表,其实就是 数组 + hash 函数 来进行处理的,数组的下标索引就是 hash 函数 对 key(字符串) 进行 hash 算法计算出来的一个整数
例如这样
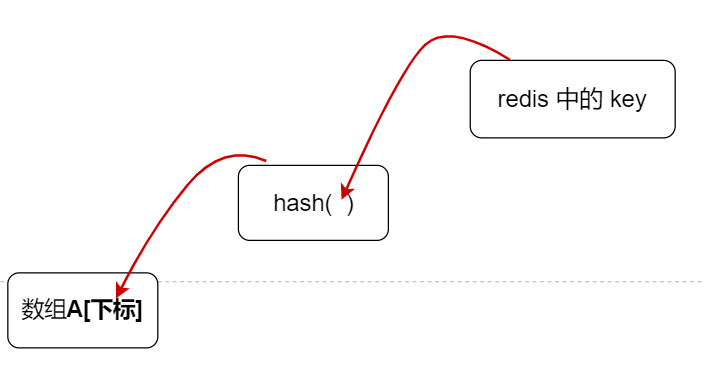
通过 hash 函数计算出来的整数是一个 64 位 的整型
hash 冲突
使用上述 hash 表的话,肯定会出现 hash 冲突,hash 冲突是什么样的效果呢?
就向上面的对 key (是一个各种组合的字符串),进行 hash 计算之后,得到一个整型的值,这个值是 64 位的整型
这也就意味着, key 的字符串组合是无限的,但是 64 整型的大小是固定的,总有有机会字符串计算出来的整数是会重复的,这个时候就出现了 hash 冲突
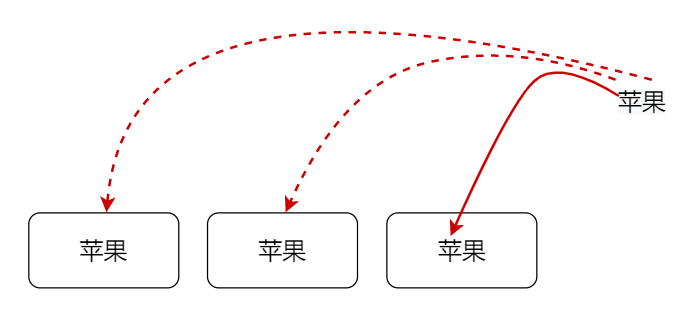
咱们可以举一个类型的形象例子:
假如说有 3 个盒子,4 个苹果,苹果要装在盒子里面,那么至少有一个抽屉是会放 2 个苹果,图下图所示,那么放 2 个苹果的这个抽屉就出现了 hash 冲突,就需要解决
例如放到我们的 hash 表中,数组大小我们设定了长度为 3,那么所有的整数我们都要对 3 取余,然后就结果对号入座
解决 hash 冲突
根据上述情况,出现了 hash 冲突,我们需要如何处理呢,如何才能解决 hash 冲突?
解决冲突的方式:
- 使用链表,也就是链地址法 , 数组 + 链表的 方式
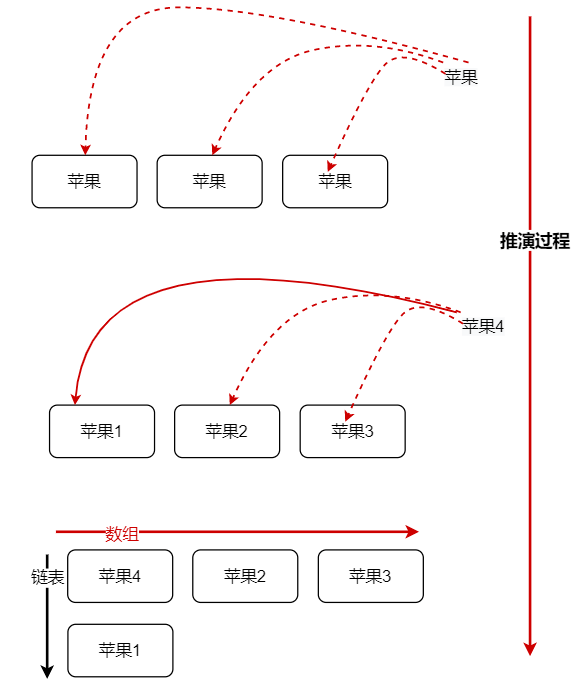
将出现冲突的元素,插入到以原有冲突元素作为链表头的链表中,使用头插法
一般是使用头插法, 这是遵循缓存淘汰算法的逻辑原理 LRU
数据库也是使用的头插法,表示新插入的数据,是最近就要使用的
- 再使用一个 hash 函数来进行计算,得出另一个值,这是 再 hash 法
- 再加一个数组来存放冲突的数据(这种方式不太好)
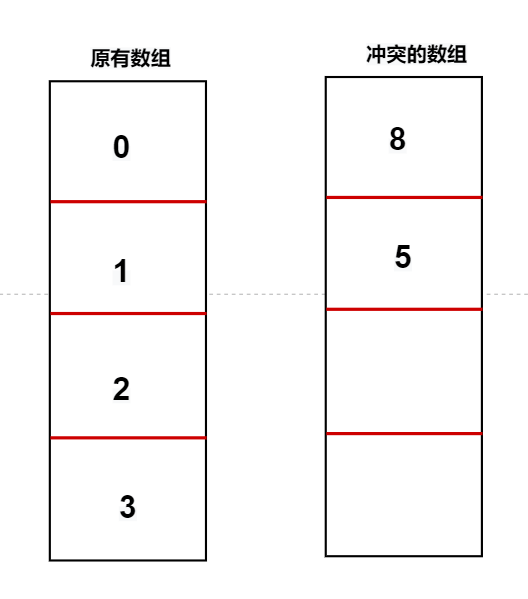
原有数组的每一个坑占一个放一个萝卜,如果有冲突出现,那么就把出现冲突的元素放到冲突数组中,并记下他所在冲突数组的索引位置,这个比较麻烦,不可持续
扩容和缩容
那么当咱们数据量比较大的时候,发生 hash 冲突的情况就会比较多,若大部分时间都是去解决冲突了,那么非常低效的,因此需要扩容
扩容的原则又是如何扩容的呢?
扩容的时候是,当持久化的数据量大于数组长度的时候,就会进行翻倍的扩容,例如上述 数组长度为 3 ,当我们有 4 个 或者 5 个数据的时候,数组的长度会扩到 6,12, 24 … 这样的来进行翻倍扩容
那么 缩容的时候,是不是也是要进行翻倍缩容的?
我们可以来看看效果,如果是翻倍缩容的话
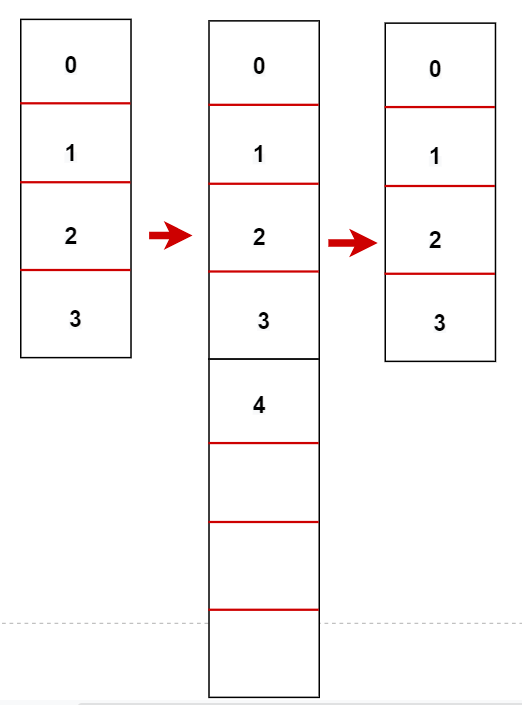
如果是翻倍缩容的话,就会出现这么一个情况,原有数组长度为 4,如果数据变成 5 个,就会翻倍扩容数组长度为 8,如果数据又变回 4 个,那么数组长度又会翻倍缩容到长度为 4
就会出现上述的这类情况,可能会存在一会扩容,一会缩容,这是非常消耗资源和性能和,因此定了一个数据是 当数据量小于数组长度的 10% 的时候,会进行缩容
本次暂且分享这么多,下一部分分享具体的 hash 表在 redis 中的数据结构,和具体的实现方式
今天就到这里,学习所得,若有偏差,还请斧正
欢迎点赞,关注,收藏
朋友们,你的支持和鼓励,是我坚持分享,提高质量的动力

好了,本次就到这里
技术是开放的,我们的心态,更应是开放的。拥抱变化,向阳而生,努力向前行。
我是小魔童哪吒,欢迎点赞关注收藏,下次见~
本作品采用《CC 协议》,转载必须注明作者和本文链接





 关于 LearnKu
关于 LearnKu




推荐文章: