
正则表达式(三)
11 / 0 / 创建于 1年前 /
 HuDu 的个人博客
HuDu 的个人博客
四、边界断言
4.1、普通边界断言
边界断言指一段表达式前后是否满足指定条件,该条件由一个子表达式组成,基于前后字符能否匹配来计算布尔值。因断言部分不会消耗匹配字符,固又称为零宽断言。示例
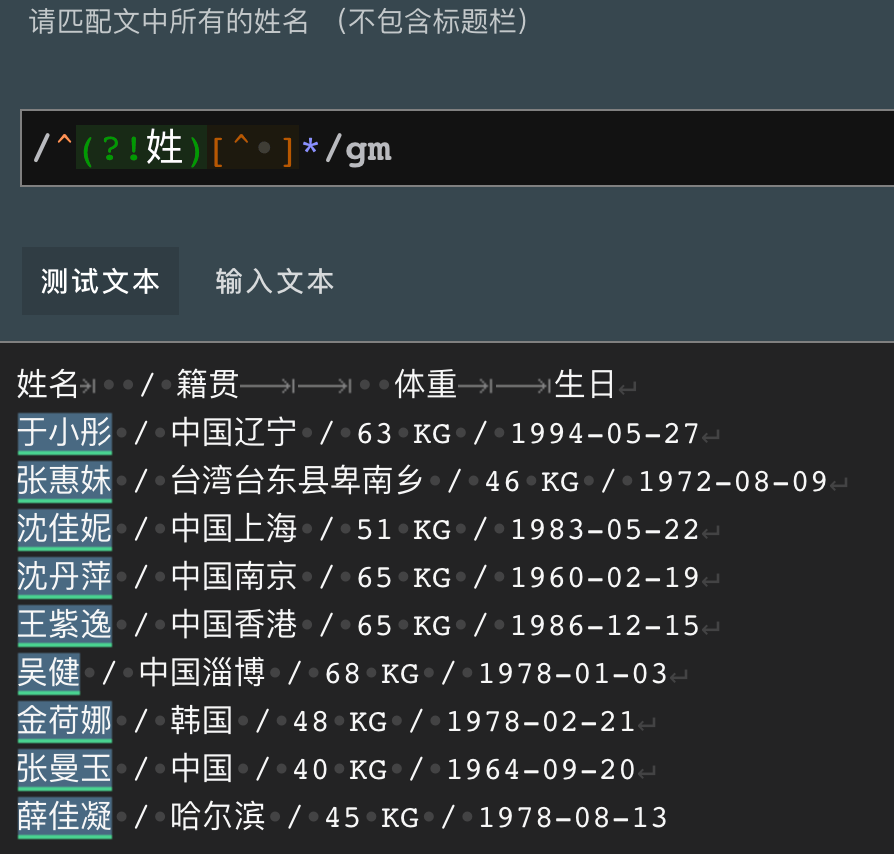
曾小红,男、编号007,举重运动员,28岁,体重56KG,身高175cm。最好成绩:挺举98KG\d{3}是不严谨的,它会把编号也匹配到结果中。修改正则为:\d{3}cm 可以精确得到结果,但同时把单位cm也包含进去了。这时就可以使用边界断言,断言数字后面是cm,正确的写法是:\d{3}(?=cm),只会返回结果175. 所断言的cm不会包含进来。
上例如果要更严谨一点,也可以往后进行断言,如 (?<=身高)\d{3}(?=cm),表示数字前面必须是“身高”


边界断言包含以下四种语法
| 语法 | 描述 | 兼容性 |
|---|---|---|
(?= ...) 前置断言 |
判定一段表达式前面是否满足条件 | |
(?! ...) 前置否定断言 |
判定一段表达式前面是否不满足条件 | |
(?<= ...) 后置断言 |
判定一段表达式后面是否不满足条件 | js中部分浏览器不支持 |
(?<! ...) 后置否定断言 |
判定一段表达式后面是否不满足条件 | js中部分浏览器不支持 |
注意:后置断言非常消耗性能,所以不推荐使用无限大的量词如:* + {n,}。举例 (?<=.+)aa 就是是错误的,必须改成一个有限范围如: (?<=.{1,200})aa
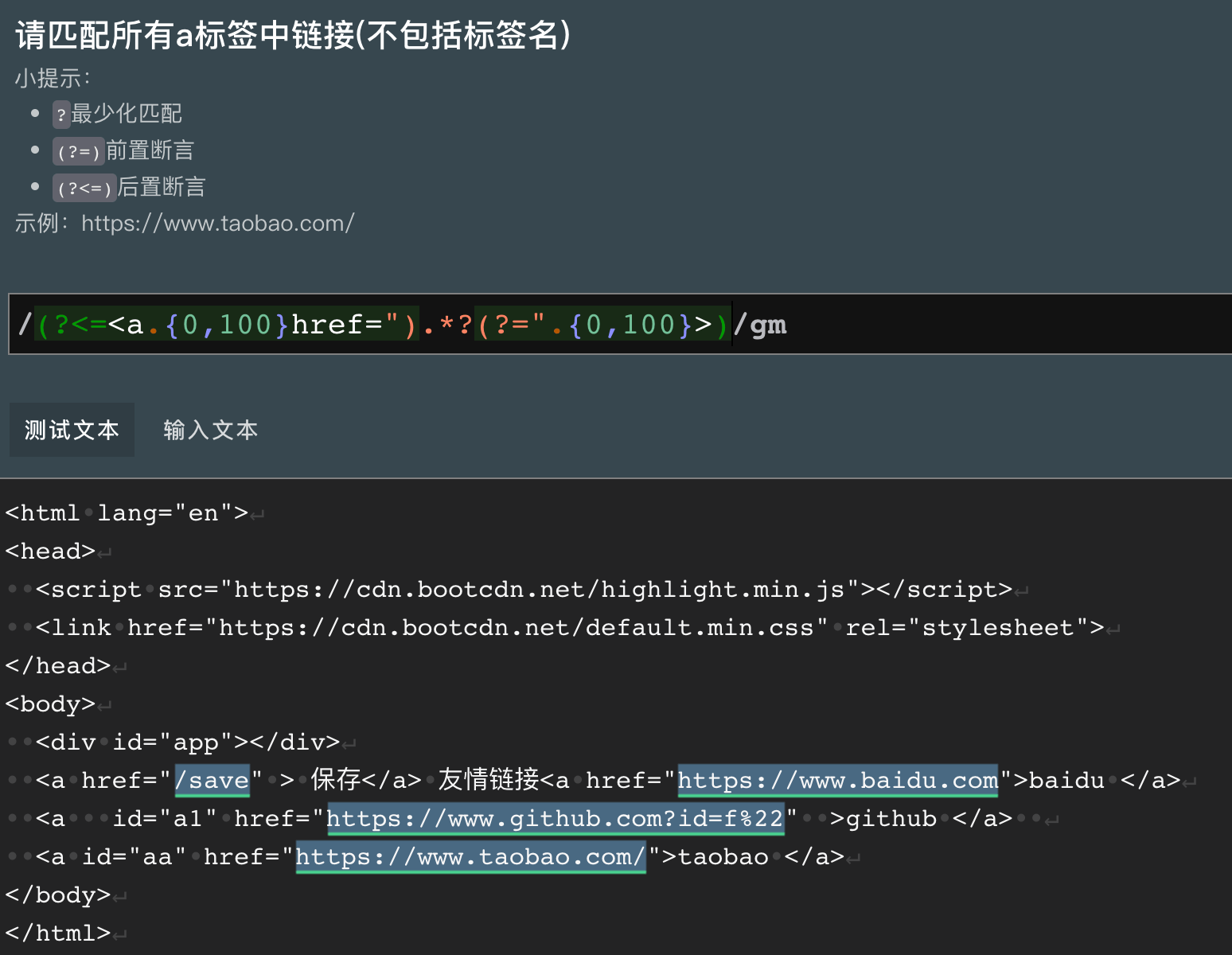
- 正则:
/(?<=<a.{1,100}href=\").*?(?=\")/gm
4.2、高级特性
- 零宽断言:断言条件本身不会消耗字符
- 多边界断言:一个正则可同时存在多个边界断言。根据其所处位置来决定断言的边界。
- 条件组合:多个子断言可以进行布尔运算如:
&&||(),h(?=条件1)(?=条件2)且运算,指必须同时满足多个条件h(?=(?=条件1)(?=条件2))且运算,条件1与条件2组成一个新条件,并且两个条件都必须满足h(?=(?=条件1)|(?!条件2))或运算,满足条件1或者 不满足 条件2h(?=表达式1|(?=条件1)(?!条件2))混合运算,表示满足表达式1或者同时满足条件1、2
- 任意边界:可以是任意合法的表达式边界,甚至可以是空字符边界。

首先,匹配正确的内容的正则为/#([\da-f]{6};|[\da-f]{3};),然后是匹配不正确的,即/#(?![\da-f]{6};|[\da-f]{3};),因为需要匹配内容所以正则为/#(?![\da-f]{6};|[\da-f]{3};).{0,7}
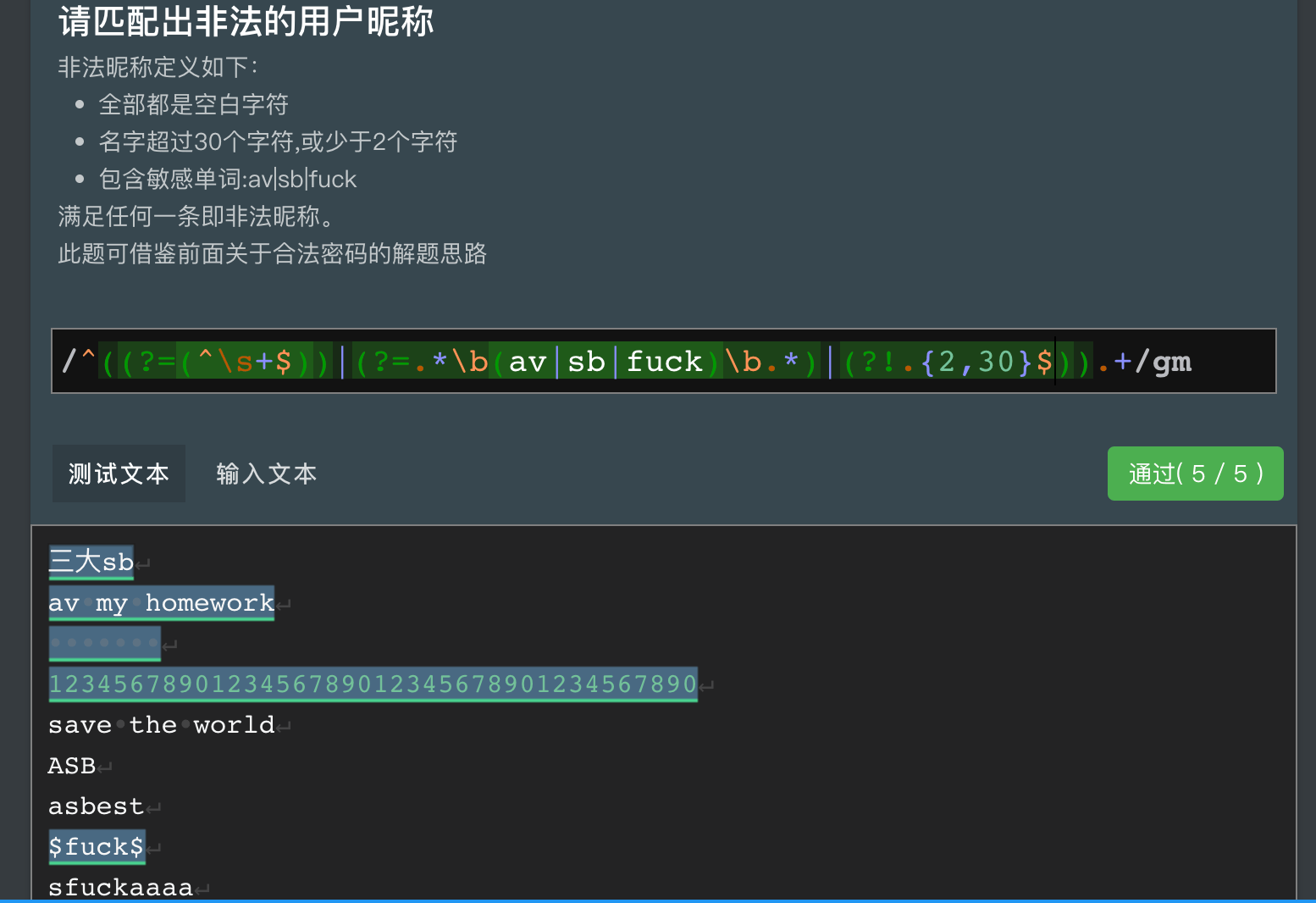
现有如下需求
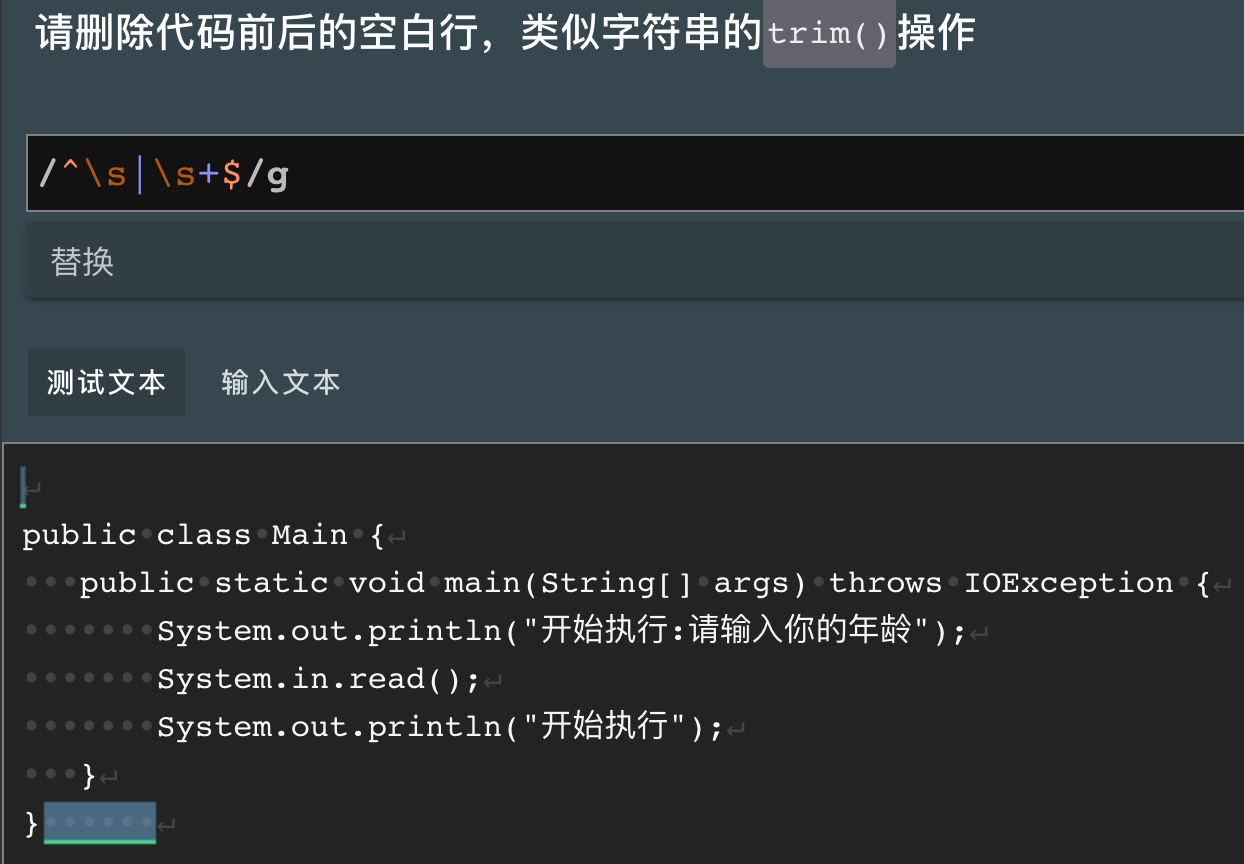
检测用户密码是否符合以下要求:
- 密码长度是8-20位
- 大小写字母以及数字必须都有一个。
实现上述需就可以采用分而治之的思路,把每个条件分别进行计算:
- 验证长度:
(?=^.{8,20}$),表示总字符长度在8至20之间。^$是两个特殊字符,这里分别表示文本的开头与结尾,将在后续章节专门学习。 - 验证大写字母:
(?=.*[A-Z]),表示文中任意地方至少出现一次大写字母。 - 验证小写字母:
(?=.*[a-z]),表示文中任意地方至少出现一次小写字母。 - 验证数字:
(?=.*\d),表示文中任意地方至少出现一次数字。 - 最后组合条件并追加内容
(?=^.{8,20}$)(?=.*[A-Z])(?=.*[a-z])(?=.*[\d]).+
五、特殊边界断言
前面学习了边界断言,通过断言表达式前后的内容,来决定是否匹配。但在一些特殊场景中断言无法进行,比如断言文本开头,目前所学正则没有一个字符可用来表示文本开头,自然无法进行断言。
但这类使用场景是真实存在的,而且还很频繁。比如:判断一段文本是否以”hello”开头。为了实现这类需求,正则中用^ 表示文本的开头,它是一个特殊边界断言,^hello即匹配”hello”字符,并且它在文本的开头。
^ 这里并不表示某个具体字符,而是一个后置断言,断言为文本的开头。^hello等价于(?<=^)Hello,你可以认为^相当于是(?<=^)简写。就像*是{0,}简写一样。
在正则中的文本边界、行边界、单词边界即为特殊边界断言,本质上还是边界断言,用于计算出布尔值,并且也不消耗字符。其语法如下表:
| 语法 | 描述 | 兼容性 |
|---|---|---|
^ 文本开头 |
默认情况下,表示断言文本开头 | |
$文本结尾 |
默认情况下,表示断言文本结尾 | |
^ 行开头 |
被m修饰后,^表示行的开头,等价于(?<=\n|\A) |
|
$ 行结尾 |
被m修饰后,$表示行的结尾,等价于(?=\n|\Z) |
|
\A 文本开头 |
断言文本开头 | Javascript 不支持 |
\Z 文本结尾 |
断言文本结尾 | Javascript 不支持 |
\b单词开头或结尾 |
断言单词开头或结尾 | |
\B |
\b 否定式,非单词开头或结尾 ,等价于(?<!\b) 或(?!\b) |
m是一个行边界修饰符,它决定^$匹配机制,加入m表示行边界,否则就是文本边界。关于修饰符将会在后面详细讲到。
5.1、文本边界
文本边界,即整个字符串开始与结束位置,它有两种表示方式:\A \Z和 ^ $ 都分别断言为开头和结尾。遗憾的是\A \Z在javascript中不支持,^ $ 有时又要用来表示行的开头和结尾。因为正则开发之初就是为单行做匹配的,行边界即文本边界,用^ $表示没毛病,后来正则支持匹配多行了,^ $ 产生了歧义所以用m修饰符加以修正。
为了避免混淆,我建议如果是做单元匹配,全部用^$表示行边界和文本边界。如果是多行尽量用\A\Z表文本边界,用^$表示行边界。
由于本教程是基于javascript引擎,所以只能用 ^$ 表示文本边界。
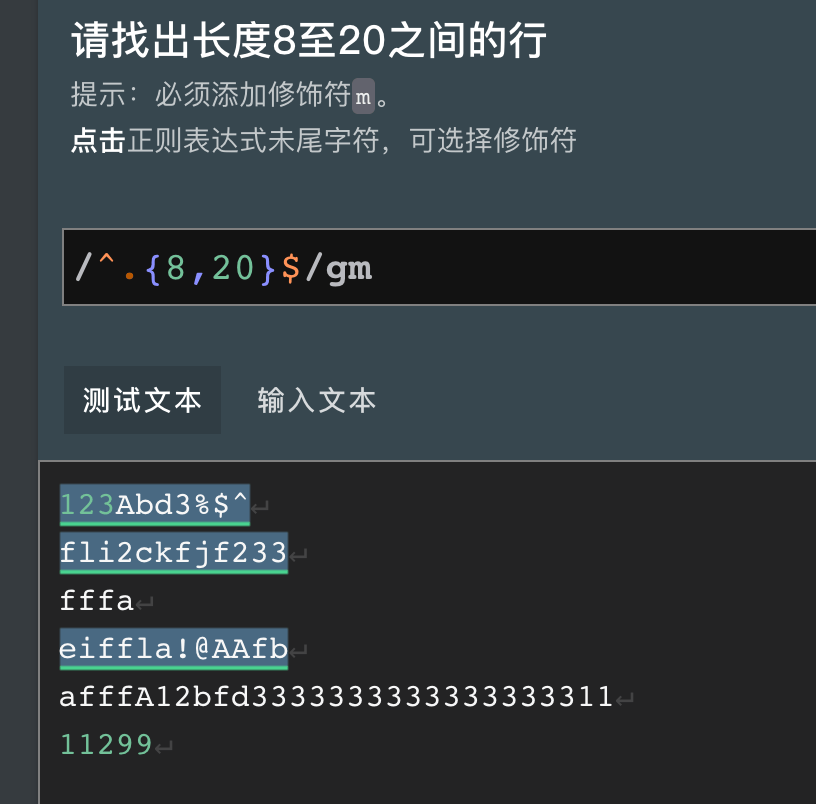
5.2、行边界
行边界,文本中每行的开始和结束位置,分别使用^和$表示,同时得还得加上行边界修饰符m。
^是一个简写后置断言,相当于(?<=\n),断言表达式后置必须是换行符,但这两者又不能完全等价,因为在文本开头,即使没有\n^也能匹配。$是一个简写的前置断言,相当于(?=\n),断言表达式前置必须是换行符,但这两者又不能完全等价,因为在文本结尾,即使没有\n$也能匹配。
在javascipt中没有\A 和\Z ,如果需要同时表达文本边界,与行边界如何做呢?可以这么实现,在未加m修饰情况下, 用^ $表示文本边界,用(?<=\n|^)与(?=\n|$)分别表示行首、行尾即可。

5.3、单词边界
\b是一个极为特殊的边界断言,它既断言单词开头,也断言单词的结尾。当我们需要匹配完整单词的就需要使用它:比如匹配 this is uncle 中 is,如果直接用is匹配结果就是:this is uncle。正确写法是\bis\b ,前后两个\b分别表示单词开头与结尾。
上述只是一个简单案例,事实上理解\b远没这么简单,因为一个单词的边界,比起行边界要复杂的多,比如分析下文中匹配所有单词:
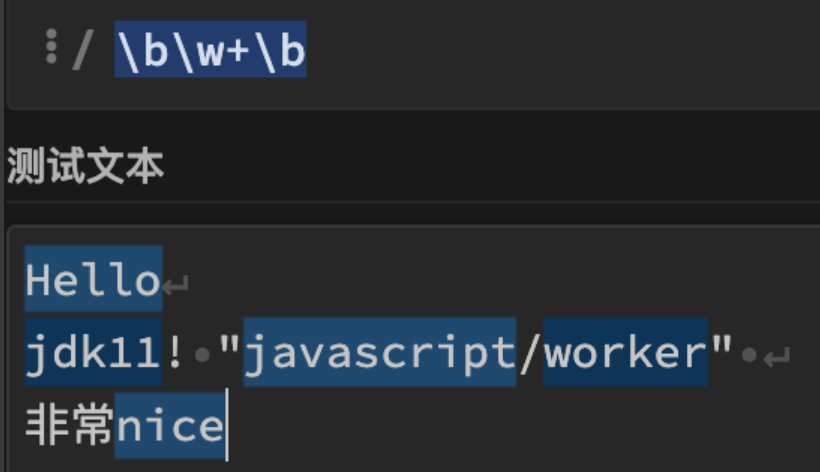
上文中总共匹配了5个单词,每个单词的边界都不相同:有本文开头,有的是行首,也有标点符号! 或",甚至中文也成了单词边界。有点乱, 如果仔细一点我们就能发现其中规律,所有的单词都是\w+ 表示,如果它的前后出现一个非单词字符即\W,代表这就是边界了。此外如果前后是^ $ \A \Z 也可以说是到边界了。
单词边界本质上还是一个边界断言,符合边界断言所有特性:计算布尔值、不消耗字符等。\b断言单词的前后是一个\W字符,或是一个其它边界(行边界,文本边界)。
以下两个表达式:\bhello\b 与(?<=^|\W|\A)Hello(?=$|\W|\Z) 希望能助你理解\b本质,
\b 兼容性问题
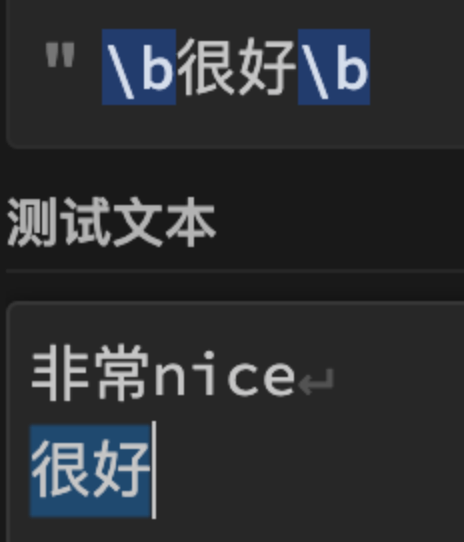
在java 与python中 \b 支持Unincode 汉字 ,如:\b很好\b 可以匹配下文:
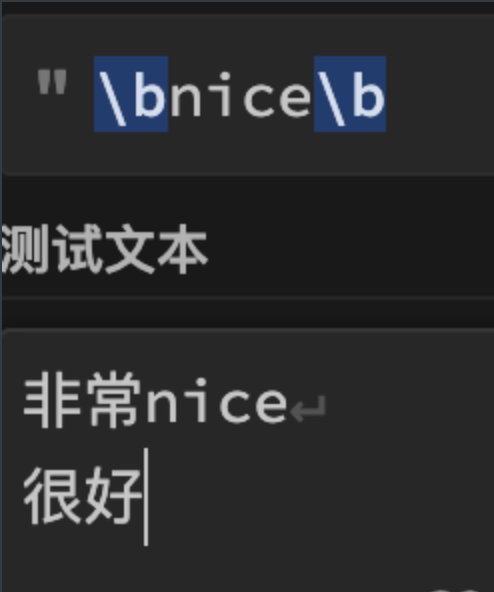
但这也有弊端,比如想要匹配上文中的\bnice\b就无法匹配,因为它认为汉字不是单词的分割。
六、修饰符
很多地方把修饰符,称作模式,听着顺口但表述并不准确。修饰符用于影响表达式的匹配逻辑, 比如i修饰符表示正则勿略大小写,而g要求正则匹配全部结果,默认情况下的正则只会匹配第一个结果。下表中列出了各语言中常见的修饰符
| 修饰符 | 描述 | 兼容性 |
|---|---|---|
global 全局匹配 |
默认只返回匹配到的第一个结果,加上g匹配全部可匹配结果 |
|
insensitive 勿略大小写 |
不区分大小写 | |
multi line 行边界修饰符 |
此模式下^和$可以分别匹配行首和行尾,默认情况下只能匹配文本开头与结尾 |
|
single line .通配修饰符 |
此模式下.能匹配任意字符,包括换行符 |
|
extended 注释修饰符 |
忽略空白字符,可以多行书写,并使用#进行注释说明 | javascript不支持 |
g全局匹配
默认情况正则引擎匹配到第一个结果之后就结束了,加上g之后就会匹配全部可匹配结果。
i勿略大小写
这是最好理解的一个修饰符。

m行边界修饰符
很多地方把它叫 多行模式,让我误以为它的作用就是让正则把字符串按行拆分,然后在一行一行的匹配,事实上它的作用是于定义^与$边界断言的作用范围。默认情况下^$分别表示文本的开头与结尾,加上之后表示行首与行尾,也包括文本开头与结尾。一般的正则表达式应用都会加上m修饰符。
s 点通配符
s并不是所谓的单行模式,而是用来定义.是否包括换行?默认情况下不包括换行,加上之就包括换行符。工作中不建议使用该修饰符,会让结果变得不可预期。可以用[\D\d] 来代替.通配符。
x注释修饰符
正则让人头痛一点就是字符太难以阅读,x注释修饰符可以一定程度上降低复杂性,该修饰符下正则的空行将被勿略,并且可以通过添加# 表示注释。如下面这个示例就是启用了x
<span> #标签开头
.*? #最少化匹配中间任意内容
<\/span> #标签结尾由于x会勿略所有空白字符,所有类似 空格 tab制表符换行都需要使用\s代替。
注释还有另一种写法(?#注释内容) 它不需x修饰符的支持,不过这种写法在javascrip 与java中不支持。
工具中默认修饰符
在使用类似idea,vs code,或notepad++等工具时,其正则都添加了gmi三个修饰符,而且除了i大小写勿略,其它都不可以改变。
本作品采用《CC 协议》,转载必须注明作者和本文链接



 关于 LearnKu
关于 LearnKu



