
MongoDB 存储引擎
0 / 0 / 创建于 3年前
 阿兵云原生 的个人博客
阿兵云原生 的个人博客
简单回顾
上次我们说到了关于 mongodb 的集群,分为主从集群和分片集群,对于分片集群中的分片这里需要注意如下几点,一起来回顾一下:
- 对于热点数据
某些分片键(分片键是集合中每个文档中存在的索引字段或复合索引字段)会导致所有的 读或者写请求 都操作在单个数据块或者分片上,这样就会导致单个分片服务器负荷过重,那么自增长的分片键容易导致写的问题
- 对于不可分割的数据块
对于粗粒度的分片键,可能会导致许多文档使用相同的分片键
这样的话这些文档就不能被分割为多个数据块,这就会限制了mongodb 的均匀分布数据能力
- 对于查询障碍
分片键与查询是没有关联的,这样会造成糟糕的查询性能
对于以上注意点,咱们做到心中有数,实际工作中遇到类似的问题,就可以尝试学着处理了
今天我们简单了解一下 mongodb 的存储引擎是个啥
存储引擎
说到 mongodb 的存储引擎,我们要知道是在 mongodb 3.0 的时候引入了可插拔存储引擎的概念
现在主要有这几个引擎:
- WiredTiger 存储引擎
- inMemory 存储引擎
在存储引擎刚出来的时候,默认是使用的 MMAPV1 存储引擎的
MMAPV1 引擎,看名字我们大概就知道他是使用的是 mmap 来做的,运用的是 linux 内存映射的原理
现在不使用 MMAPV1 引擎,是因为 WiredTiger 存储引擎更优,例如对比一下 WiredTiger 就有如下优势:
- WiredTiger 读写操作性能更好
WiredTiger 能更好的发挥多核系统的处理能力
WiredTiger 锁的粒度更小
MMAPV1引擎使用表级锁,当某个单表上有并发的操作,吞吐就会受到限制
而 WiredTiger 使用文档级的锁 ,这就带来并发及吞吐的提高
- WiredTiger 压缩方式更好
WiredTiger 使用前缀压缩,比起 MMAPV1 更节省对内存空间的损耗
并且 WiredTiger 还提供压缩算法, 这样就可以大大降低对硬盘资源的消耗
WiredTiger 引擎 的写入原理
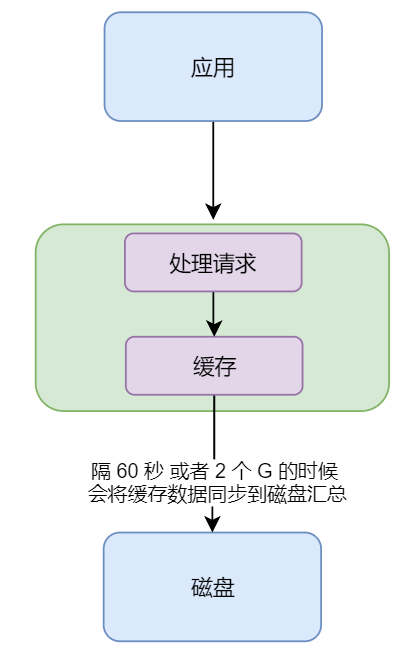
通过上图我们可以看出, WiredTiger 写入磁盘的原理也是很简单的
- 应用请求来到 mongodb ,mongodb 做处理,并将结果存入缓存中
- 当缓存中达到 2 个 G 的时候,或者 当 60 s 定时器到时间的时候,就会将缓存中的数据刷到磁盘中去
细心的 xdm 就知道,那么如果现在正好是 59 秒,1个多 G 的时候,缓存中的数据还没有同步到磁盘中,mongodb 就异常挂掉了,那么 mongodb 岂不是会丢失数据?
我们用手指头都可以想到,mongodb 的设计者怎么会让这种情况存在,那么必然会有解决方案,如下
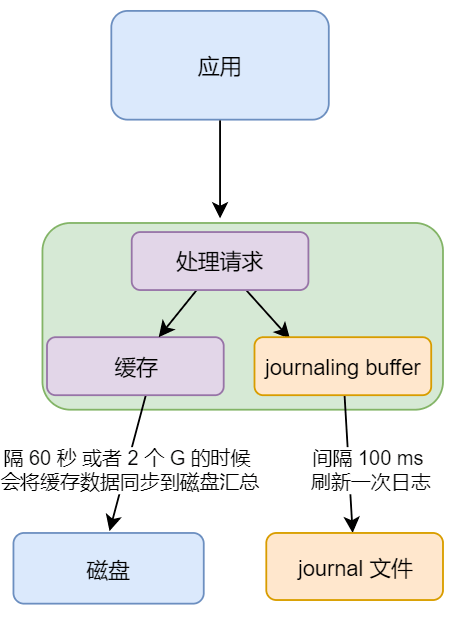
如上图,图中多了一个 journaling buffer 和 journal 文件
- journaling buffer
存放 mongodb 增删改 指令的缓冲区
- journal 文件
类似于关系数据库中的事务日志
引入 Journaling 的目的是:
Journaling 能够使 mongodb 数据库由于意外故障后快速恢复
Journaling 日志功能
Journaling 的日志功能,看上去有点像是 redis 中的 aof 持久化一样,也只能说是类似
在 mongodb 2.4 的时候,就已经是 默认会开启 Journaling日志功能 的,我们启动 mongod 实例的时候,服务就会去检查是否需要恢复数据
因此就不会有上述 mongodb 丢数据的情况了
另外这里我们要知道,journaling 的日志功能,当 mongodb 需要进行写操作的时候,也就是 增,删,改的时候,journaling 是会写日志的,这会影响性能
但是 mongodb 读取操作的时候,是不会记录到缓存中的,因此也不会记录到 journaling 日志中,因此读操作没有影响
今天就到这里,学习所得,若有偏差,还请斧正
欢迎点赞,关注,收藏
朋友们,你的支持和鼓励,是我坚持分享,提高质量的动力

好了,本次就到这里
技术是开放的,我们的心态,更应是开放的。拥抱变化,向阳而生,努力向前行。
我是阿兵云原生,欢迎点赞关注收藏,下次见~
本作品采用《CC 协议》,转载必须注明作者和本文链接





 关于 LearnKu
关于 LearnKu




推荐文章: