
Go语言 WaitGroup 源码知多少
0 / 0 / 创建于 3年前
 阿兵云原生 的个人博客
阿兵云原生 的个人博客
前面的文章我们写协程的时候有用到 WaitGroup
我们的写法大概是这样的
func main() {
...dothing()
wg := sync.WaitGroup{}
// 控制 多个子协程的声明周期
wg.Add(xx)
for i := 0; i < xx; i++ {
go func(ctx context.Context) {
defer wg.Done()
...dothing()
}(ctx)
}
...dothing()
// 等待所有的子协程都优雅关闭
wg.Wait()
fmt.Println("close server ")
}可以看出,sync.WaitGroup 主要是用来等待一批协程关闭的,例如上面的 主协程 等待 所有子协程关闭,自己才进行退出
那么我们今天就来探究一下 sync.WaitGroup 的源码实现吧
探究源码实现
sync.WaitGroup 的使用上述 dmeo 已经给出,看上去用起来也很简单
使用 Add 函数是添加等待的协程数量
使用 Done 函数是通知 WaitGroup 当前协程任务完成了
使用 Wait 函数 是等待所有的子协程关闭
咱打开源码
源码路径:src/sync/waitgroup.go ,总共源码 141 行

单测文件 src/sync/waitgroup_test.go 301 行
源码文件总共 4 个函数, 1 个结构体
- type WaitGroup struct {
- func (wg *WaitGroup) state() (statep *uint64, semap *uint32) {
- func (wg *WaitGroup) Add(delta int) {
- func (wg *WaitGroup) Done() {
- func (wg *WaitGroup) Wait() {
我们逐个来瞅一瞅这几个函数都做了那些事情
type WaitGroup struct {
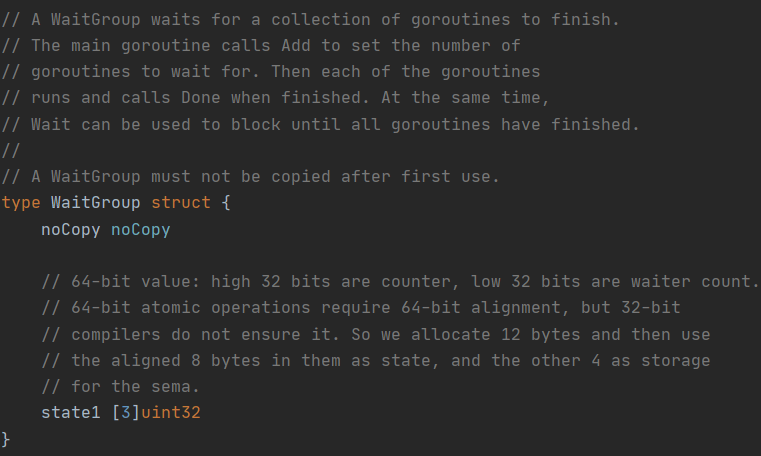
WaitGroup 等待一组 goroutine 完成,主 goroutine 调用 Add 来设置等待的 goroutines
然后是每一个协程调用 ,当完成时运行并调用 Done
与此同时,Wait 可以被用来阻塞,直到所有 goroutine 完成
WaitGroup 在第一次使用后不能被复制
我们可以看到 WaitGroup 结构体有 2 个成员
- noCopy
是 go 语言的源码中检测禁止拷贝的技术,如果检测到我们的程序中 WaitGroup 有赋值的操作,那么程序就会报错
- state1
可以看出 state1 是一个元素个数为 3 个数组,且每个元素都是 占 32 bits
在 64 位系统里面,64位原子操作需要64位对齐
那么高位的 32 bits 对应的是 counter 计数器,用来表示目前还没有完成任务的协程个数
低 32 bits 对应的是 waiter 的数量,表示目前已经调用了 WaitGroup.Wait 的协程个数
那么剩下的一个 32 bits 就是 sema 信号量的了(后面的源码中会有体现)
func (wg *WaitGroup) state() (statep *uint64, semap *uint32) {
继续看源码
// state returns pointers to the state and sema fields stored within wg.state1.
func (wg *WaitGroup) state() (statep *uint64, semap *uint32) {
if uintptr(unsafe.Pointer(&wg.state1))%8 == 0 {
return (*uint64)(unsafe.Pointer(&wg.state1)), &wg.state1[2]
} else {
return (*uint64)(unsafe.Pointer(&wg.state1[1])), &wg.state1[0]
}
}
此处我们可以看到 , state 函数是 返回存储在 wg.state1 中的状态和 sema字段 的指针
这里需要重点注意 state() 函数的实现,有 2 种情况
- 第 1 种 情况是,在 64 位系统下面,返回 sema字段 的指针取的是 &wg.state1[2] ,说明 64 位系统时,state1 数据排布是 : counter , waiter,sema
- 第 2 种情况是,32 位系统下面,返回 sema字段 的指针取的是 &wg.state1[0] ,说明 64 位系统时,state1 数据排布是 : sema ,counter , waiter
具体原因细心的 胖鱼 可能有点想法,
为什么在不同的操作系统里面,数据结构中的 state1 数组数据排布还不一样?
我们仔细看一下上述的源码
64 位系统时:
return (*uint64)(unsafe.Pointer(&wg.state1)), &wg.state1[2]
32 位系统时
return (*uint64)(unsafe.Pointer(&wg.state1[1])), &wg.state1[0]
golang 这样用,主要原因是 golang 把 counter 和 waiter 合并到一起统一看成是 1 个 64位的数据了,因此在不同的操作系统中
由于字节对齐的原因,64位系统时,前面 2 个 32 位数据加起来,正好是 64 位,正好对齐
对于 32 位系统,则是 第 1 个 32 位数据放 sema 更加合适,后面的 2 个 32 位数据就可以统一取出,作为一个 64 位变量

Add 函数主要功能是将 counter +delta ,增加等待协程的个数:
我们可以看到 Add 函数,通过 state 函数获取到 上述 64位的变量(counter 和 waiter) 和 sema 信号量后,通过 atomic.AddUint64 函数 将 delta 数据 加到 counter 上面
这里为什么是 delta 要左移 32 位呢?
上面我们有说到嘛, state 函数拿出的 64 位变量,高 32 bits 是 counter,低 32 bits 是waiter,此处的 delta 是要加到 counter 上,因此才需要 delta 左移 32 位
func (wg *WaitGroup) Done() {
// Done decrements the WaitGroup counter by one.
func (wg *WaitGroup) Done() {
wg.Add(-1)
}Done 函数没有什么特别的,直接上调用 Add 函数来实现的
func (wg *WaitGroup) Wait() {
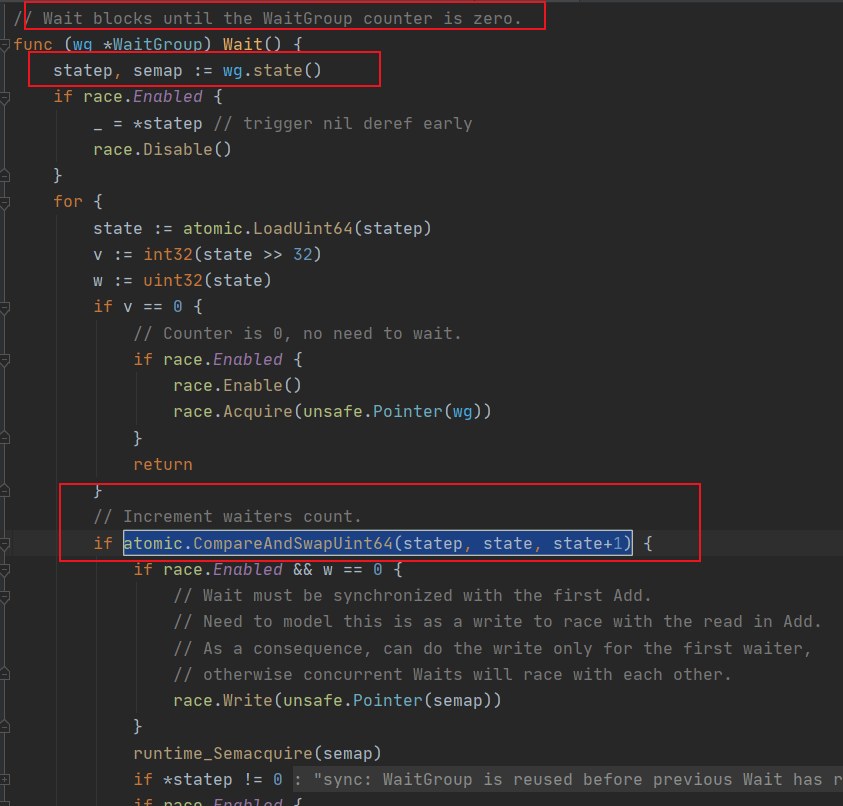
Wait 函数 主要是增加 waiter 的个数:
阻塞等待 WaitGroup 中couter 的个数变成 0
函数主要是通过 atomic.CompareAndSwapUint64 函数 CAS (比较并且交换)的方式来操作 waiter 的。
很明显该逻辑是 必须要是 true,才能走到里面的实现,进行 runtime_Semacquire(semap) 操作,若是 false ,则需要在循环里面继续再来一次
Waitgroup .go 的具体实现虽然才 141 行 ,里面的具体细节我们还需要反复深究,学习其中的设计原理,例如 state1 结构体成员的设计思想,就非常的巧妙,无需将它拆成 3 个成员,进而无需再操作值的时候加锁,这样性能就得以很好的展现
慢慢的学习好的思想,日拱一卒
欢迎点赞,关注,收藏
朋友们,你的支持和鼓励,是我坚持分享,提高质量的动力

好了,本次就到这里
技术是开放的,我们的心态,更应是开放的。拥抱变化,向阳而生,努力向前行。
我是阿兵云原生,欢迎点赞关注收藏,下次见~
本作品采用《CC 协议》,转载必须注明作者和本文链接






 关于 LearnKu
关于 LearnKu




推荐文章: