
replicaSet,DaemonSet and Job
3 / 0 / 创建于 3年前
 阿兵云原生 的个人博客
阿兵云原生 的个人博客

ReplicaSet
上一篇讲到的 ReplicationController 是用于复制和在异常的时候重新调度节点的 K8S 组件,后面 K8S 又引入了 ReplicaSet 资源来替代 ReplicationController
ReplicationController 和 ReplicaSet 有什么区别呢?
ReplicationController 和 ReplicaSet 的行为是完全相同的,但是 ReplicaSet 的 pod 选择器表达能力更强
- ReplicationController 只允许包含某个标签的匹配 pod
- ReplicaSet 可以包含特定标签名的 pod ,例如 env=dev 和 env=pro 一起匹配
- ReplicaSet 还可以匹配缺少某个标签的 pod
总之,无论 ReplicationController 匹配的标签值是多少,ReplicationController 都无法基于标签名来进行匹配,例如 匹配env=* ReplicationController 就不行,但是 ReplicaSet 可以
写一个 ReplicaSet Demo
rs 是 ReplicaSet 的简称,写一个 ReplicaSet 的 demo
- api 版本是 apps/v1
此处的 api 版本和之前我们写到的有些许不一样,这里解释一下
此处的 apps 代表的是 api 组的意思
这里的 v1 代表的是 apps 组下的 v1 版本,此处就和我们平时写的 路由一样
- 副本数 3 个
- 选择器指定匹配标签为 app=xmt-kubia ,(ReplicationController 是直接写在 selector 后面)
- 模板拉取的镜像是 xiaomotong888/xmtkubia
kubia-rs.yaml
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: kubia-rs
spec:
replicas: 3
selector:
matchLabels:
app: xmt-kubia
template:
metadata:
labels:
app: xmt-kubia
spec:
containers:
- name: rs-kubia
image: xiaomotong888/xmtkubia
ports:
- containerPort: 8080
部署 rs
kubectl create -f kubia-rs.yaml

部署 rs 后,我们可以看到,通过 Kubectl get rs 查看新建的 rs 基本信息
对于原本就有的 3 个标签为 app=xmt-kubia 的 pod 没有影响, rs 也没有多创建 pod ,这没毛病
rs 也是会去搜索环境内的匹配的标签对应的 pod 个数,然后和自己配置中的期望做比较,若 期望的大,则增加 pod 数量,若期望的小,则减少 pod 数量
感兴趣的朋友 也可以使用 kubectl describe 查看一下这个 rs ,和 rc 没有什么区别
ReplicaSet 可以这样用
上面的例子我我们可以看到的 RepilicaSet 使用 matchLabels 的时候 好像和 ReplicationController 没有什么区别,那么现在我们可以来丰富一下我们的选择,我们可以使用 matchExpressions
例如我们在 yaml 加入 matchExpressions 的时候,我们可以这样来写
省略多行...
selector:
matchExpressions:
- key: env
operator: In
values:
- dev
省略多行...例如上面 yaml 代码段的含义是:
- 匹配的标签 key 是 env
- 运算符是 In
- 匹配的 env 对应的 值是有 dev 即可
key
具体的标签 key
operator
运算符,有这 4 个
- In
Label 的值必须与其中一个制定的 values 匹配
- NotIn
Label 的值必须与任何制定的 values 不匹配
- Exists
pod 必须包含一个制定的名称的标签,有没有值不关心,这个时候不要指定 values 字段
- DoesNotExist
pod 的标签名称不得包含有指定的名称,这个时候不要指定 values 字段
注意
如果我们指定了多个表达式,那么需要这些表达式都是 true 才可以生效,才可以正确匹配
删除 rs
删除 rs 的时候和删除 rc 的做法是一样的,默认的话都是会删除掉 rs 管理的 pod ,如果我们不需要删除对应的 pod ,那么我们也可以加入 --cascade=false 或者 –cascade=orphan
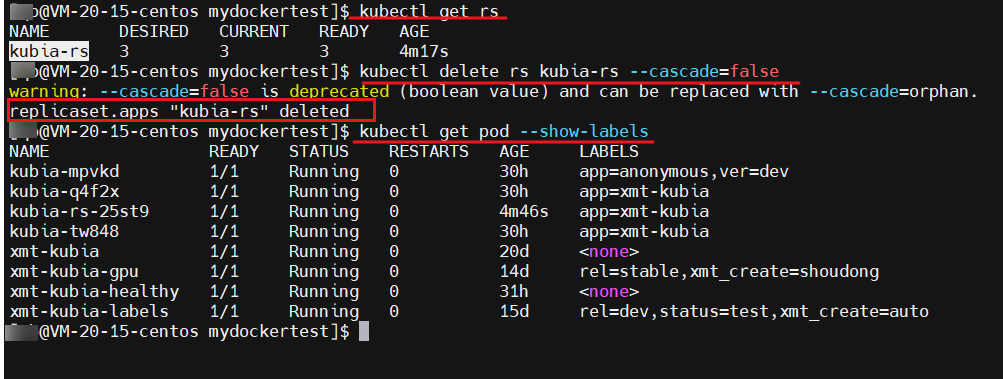
按照上述方式指定之后,删除 rs ,就不会对 pod 有任何影响
DaemonSet
前面说到的 ReplicationController 和 ReplicaSet 都是在 k8s 集群中部署特定的数量的 pod,但是 pod 具体是运行在哪个节点上的,不太关心。
现在我们可以来分享一个 DaemonSet ,它也是 k8s 中的一种资源
当我们希望我们的 pod 正好在每一个节点运行一个的时候,可以使用 DaemonSet 资源来进行管理
DaemonSet 没有副本数的概念,他是检查每个节点里面是否有自己管理的标签对应的 pod,若有就维持,若没有就创建
如下是一个 ReplicaSet 和 DaemonSet 管理内容和方式的简图:

图中,我们可以看出 DaemonSet 是每个节点分别部署一个 pod ,但是ReplicaSet 只是保证整个集群中自己管理对应标签的 pod 数量是 4 个即可
DaemonSet 的 小案例
DaemonSet 资源也是使用的 apps/v1 api 版本
匹配标签 app=ssd
pod 模板中我们设置该 pod 指定运行在 标签为 disk=ssdnode 的节点上运行 ,可以通过 nodeSelector 关键字来指定

镜像拉取的是 xiaomotong888/xmtkubia
daemonset.yaml
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: kubia-ds
spec:
selector:
matchLabels:
app: ssd
template:
metadata:
labels:
app: ssd
spec:
nodeSelector:
disk: ssdnode
containers:
- name: rs-kubia
image: xiaomotong888/xmtkubia
ports:
- containerPort: 8080部署 DaemonSet
我们使用命令部署 DaemonSet
kubectl create -f daemonset.yaml
查看 ds 的信息, ds 是 DaemonSet 的简称
kubectl get ds
使用命令查看 node 节点情况
kubectl get nodes
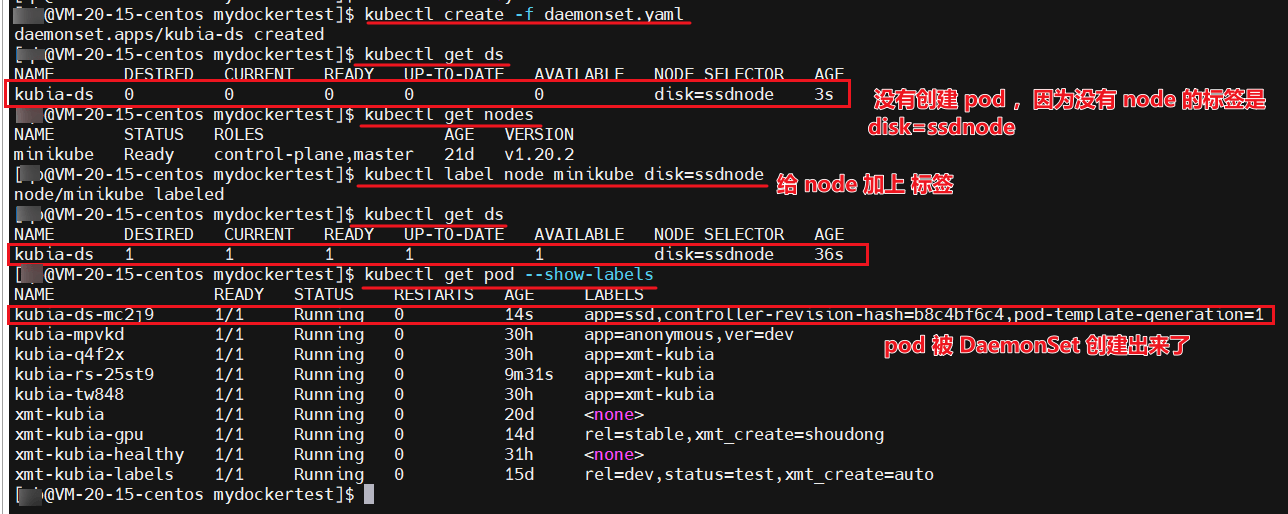
通过上图我们可以看出,部署完 DaemonSet 资源之后,每一项参数都是 0
原因是,DaemonSet 查找环境中没有标签是 disk=ssdnode 的节点
给指定的 node 加上标签 disk=ssdnode
kubectl label node minikube disk=ssdnode
加上标签之后,我们可以看到上述图片, DaemonSet 资源的各项参数变成了 1,查看 pod 的时候,也看到了对应的 pod 资源
此处演示使用的是 minikube ,因此只有一个 节点
再次修改 node 的标签
我们再次修改 node 标签,那么之前的 pod 是不是会被终止掉呢?我们来试试吧
kubectl label node minikube disk=hddnode –overwrite

果然没毛病老铁,当我们修改环境中指定节点的标签后,由于 DaemonSet 资源搜索环境中没有自己配置中指定的标签对应的节点,因此,刚才的 pod 就会被销毁掉
Job
再来介绍一下 k8s 中的 Job 资源
Job 资源是运行我们运行一种 pod,一旦程序运行 ok,pod 就会推出,job 就结束了,他不会重启 pod
当然,job 管理的 pod ,如果在运行过程中,发生了异常,我们是可以配置 Job 重启 pod 的
如下画了一个 ReplicaSet 和 Job 管理 pod 的简图:
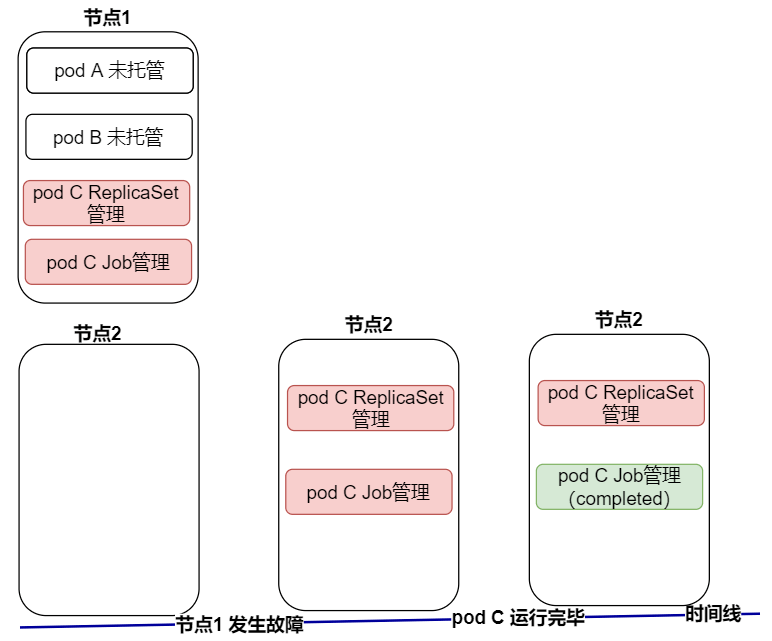
上图中我们可以看到,被 ReplicaSet 和 Job 资源管理的 pod,当节点发生异常或者 pod 自身发生异常的时候,这些 pod 是会被重启的,不需要人为的去操作
但是没有被上述资源管理的 pod,一旦发生异常,就没有人负责重启了
Job 案例
创建一个 Job 的资源,也是通过 yaml 的方式
- 类型为 Job
- 模板中的重启策略设置为 失败的时候重启 restartPolicy: OnFailure , 此处的策略不能设置为 Always,设置成 Always 是会总是重启 pod 的
- 拉取的镜像是 luksa/batch-job
这个镜像是 docker hub 上的镜像,拉出来程序启动之后,运行 2 分钟会结束程序
myjob.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: batchjob
spec:
template:
metadata:
labels:
app: batchjob-xmt
spec:
restartPolicy: OnFailure
containers:
- name: xmt-kubia-batch
image: luksa/batch-job部署 Job
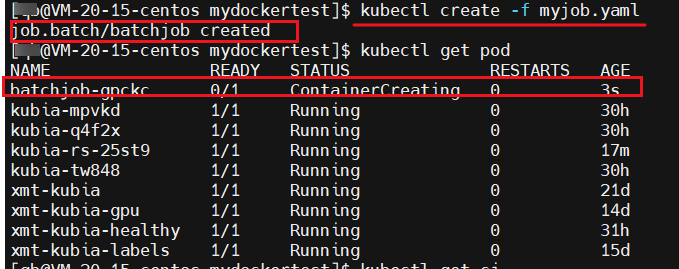
kubectl create -f myjob.yaml
可以看到 Job 资源已经部署成功了,且 pod 已经是在创建中了
pod 运行过程中,我们查看一下这个 pod 的日志
kubectl logs -f batchjob-gpckc
可以看到程序有开始日志的输出
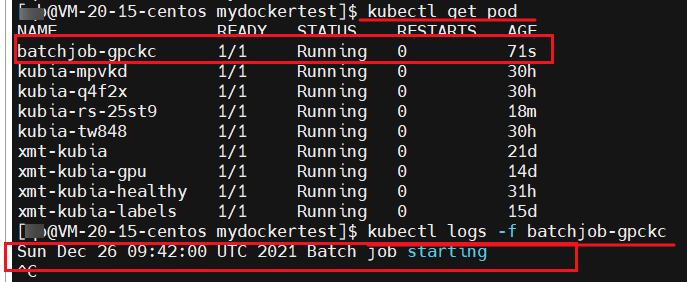
等到 pod 运行 2 分钟左右的时候,我们可以继续查看日,程序已经成功结束了,且我们的 pod 也进行了 Completed 状态 ,该 Job 也结束了
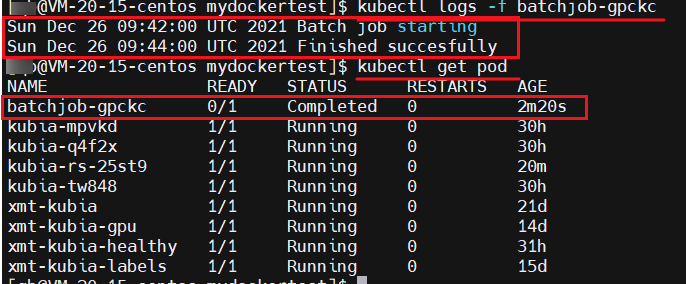
上述说到的 Job 资源,也可以设置多个 pod 实例,可以设置多个 pod 实例并行运行,也可以设置串行运行,就看我们的业务需求是什么样的了
串行的话,我们可以这样来写 yaml:
在定义 Job 资源的时候,配置上 completions 即可, Job 资源就会一个挨着一个的创建 pod 运行,pod 运行结束后,再创建下一个 pod
apiVersion: batch/v1
kind: Job
metadata:
name: batchjob
spec:
completions: 10
template:
省略多行...并行的话我们可以这样来写 yaml:
设置并行的话,我们只需要在上面的 yaml 上加入 parallelism 配置即可,表示并行运行多少个 pod
apiVersion: batch/v1
kind: Job
metadata:
name: batchjob
spec:
completions: 10
parallelism: 4
template:
省略多行...CronJob
上面的 Job 管理的 pod,都是启动一次,运行一次,或者是控制运行的次数,那么,我们能不能控制周期性的运行 一个 pod 呢?
k8s 中当然是可以的了,我们就可以使用 k8s 中的 CronJob 资源来完成我们的想法
我们只需要在 yaml 文件中写好 CronJob 的配置即可,指定好 pod 运行的周期时间即可
CronJob 的 demo
- 资源类型是 CronJob
- 运行的周期是
"* * * * *", 表示 每隔 1 分钟运行一次 pod
cronjob.yaml
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: mycronjob
spec:
schedule: "* * * * *"
jobTemplate:
spec:
template:
metadata:
labels:
app: cronjob-xmt
spec:
restartPolicy: OnFailure
containers:
- name: cronjobxmt
image: luksa/batch-job此处我们设置的是每一分钟运行一次 pod ,我们要是有别的需求也可以自行设定,上述 5 个 * 含义如下:
- 分钟
- 小时
- 天
- 月
- 星期
例如,我需要设置每个星期一的,8 点起床,就可以这样写
“0 8 * * 1”
部署 CronJob
kubectl create -f cronjob.yaml
查看 CronJob
kubectl get cj
部署 cj 后,我们可以看到 cj 已经起来了,但是好像还没有对应的 pod 被创建,cj 是 CronJob 简称
当然是不会有 pod 被创建的了,需要等 1 分钟才会创建
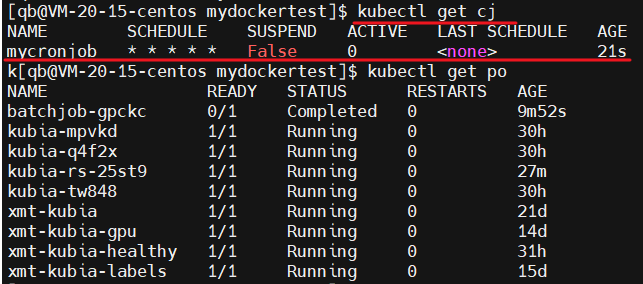
再次查看我们的 cj ,我们可以看到 ACTIVE 已经是 1 了,说明已经通过 cj 创建了 1 个 pod
我们来查看 pod ,果然是创建成功了一个 pod,且已经在运行中了,没毛病老铁

我们在使用 CronJob 资源的时候,会遇到这么一种情况:
启动的 Job 或者 pod 启动的时候相对比较晚的时候,我们可以这样来设定一个边界值
当我们的 pod 开始启动的时间不能晚于我们预定时间的过多,我们可以设置成 20s,如果晚于这个值,那么该 job 就算是失败
我们可以这样来写 yaml:
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: mycronjob
spec:
schedule: "* * * * *"
startingDeadlineSeconds: 20
jobTemplate:
省略多行...以上就是本次的全部内容了,分别分享了 ReplicaSet,DaemonSet,Job,CronJob,感兴趣的朋友行动起来吧
今天就到这里,学习所得,若有偏差,还请斧正
欢迎点赞,关注,收藏
朋友们,你的支持和鼓励,是我坚持分享,提高质量的动力

好了,本次就到这里
技术是开放的,我们的心态,更应是开放的。拥抱变化,向阳而生,努力向前行。
我是阿兵云原生,欢迎点赞关注收藏,下次见~
本作品采用《CC 协议》,转载必须注明作者和本文链接





 关于 LearnKu
关于 LearnKu



