
 程序员老狼 的个人博客
程序员老狼 的个人博客
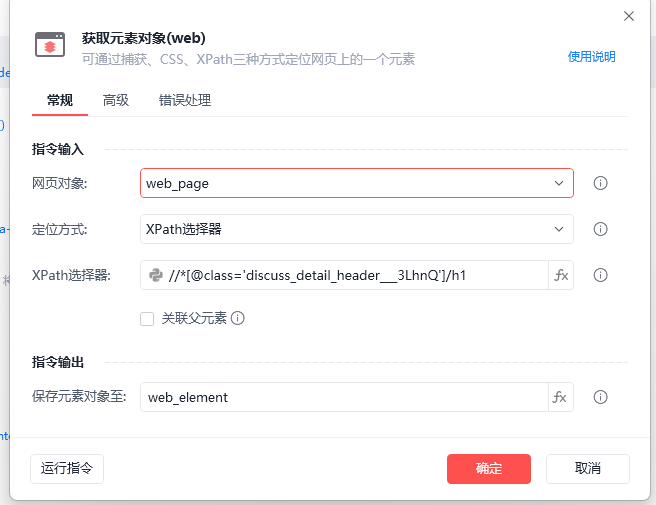
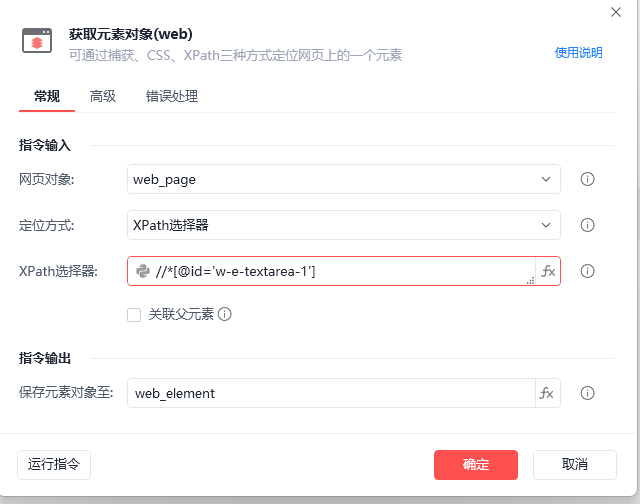
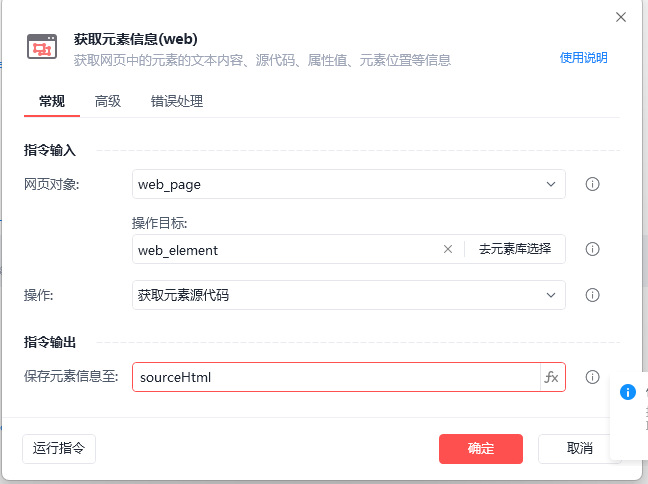
讨论数量:
(= ̄ω ̄=)··· 暂无内容!



 请登录
请登录





 关于 LearnKu
关于 LearnKu
推荐文章: