
XXL-JOB内部机制大揭秘,任务飞起来!
3 / 0 / 创建于 2年前
 MissYou-Coding 的个人博客
MissYou-Coding 的个人博客

前言
废话少说,直接进入正题。
相信大家对XXL-JOB都很了解,故本文对源码不进行过多介绍,侧重的是看源码过程中想到的几个知识点 ,不一定都对,请大神们批评指正。
基于 Spring Boot + MyBatis Plus + Vue & Element 实现的后台管理系统 + 用户小程序,支持 RBAC 动态权限、多租户、数据权限、工作流、三方登录、支付、短信、商城等功能
XXL-JOB简介
XXL-JOB是一个轻量级分布式任务调度平台,其核心设计目标是开发迅速、学习简单、轻量级、易扩展。现已开放源代码并接入多家公司线上产品线,开箱即用。XXL-JOB分为调度中心、执行器、数据中心,调度中心负责任务管理及调度、执行器管理、日志管理等,执行器负责任务执行及执行结果回调。
基于 Spring Cloud Alibaba + Gateway + Nacos + RocketMQ + Vue & Element 实现的后台管理系统 + 用户小程序,支持 RBAC 动态权限、多租户、数据权限、工作流、三方登录、支付、短信、商城等功能
任务调度 - “类时间轮”的实现
时间轮
时间轮出自Netty中的HashedWheelTimer,是一个环形结构,可以用时钟来类比,钟面上有很多bucket,每一个bucket上可以存放多个任务,使用一个List保存该时刻到期的所有任务,同时一个指针随着时间流逝一格一格转动,并执行对应bucket上所有到期的任务。任务通过取模 决定应该放入哪个bucket。和HashMap的原理类似,newTask对应put,使用List来解决 Hash 冲突。
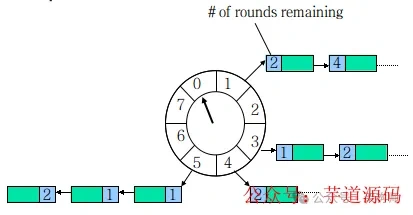
以上图为例,假设一个bucket是1秒,则指针转动一轮表示的时间段为8s,假设当前指针指向 0,此时需要调度一个3s后执行的任务,显然应该加入到(0+3=3)的方格中,指针再走3s次就可以执行了;如果任务要在10s后执行,应该等指针走完一轮零2格再执行,因此应放入2,同时将round(1)保存到任务中。检查到期任务时只执行round为0的,bucket上其他任务的round减1。
当然,还有优化的“分层时间轮”的实现,请参考https://cnkirito.moe/timer/。
XXL-JOB中的“时间轮”
XXL-JOB中的调度方式从
Quartz变成了自研调度的方式,很像时间轮,可以理解为有60个bucket且每个bucket为1秒,但是没有了round的概念。具体可以看下图。
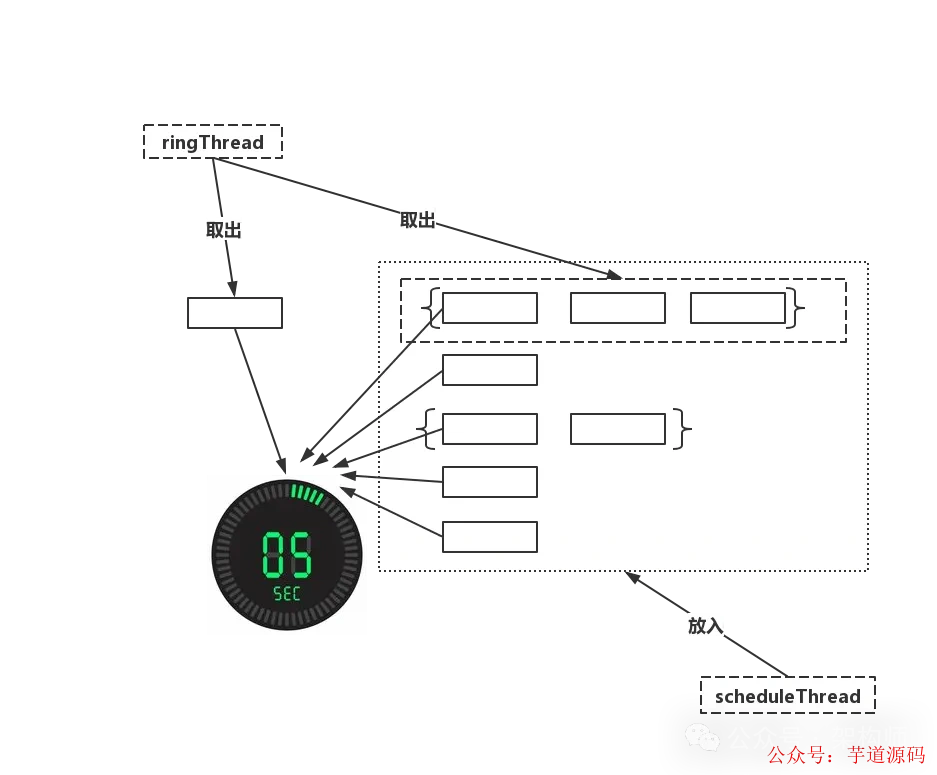
- XXL-JOB中负责任务调度的有两个线程,分别为
ringThread和scheduleThread,其作用如下。
❝
1、scheduleThread:对任务信息进行读取,预读未来5s 即将触发的任务,放入时间轮。2、ringThread:对当前
bucket和前一个bucket中的任务取出并执行。
- 下面结合源代码看下,为什么说是“类时间轮”,关键代码附上了注解,请大家留意观看。
`// 环状结构
private volatile static Map<Integer, List> ringData = new ConcurrentHashMap<>();
// 任务下次启动时间(单位为秒) % 60
int ringSecond = (int)((jobInfo.getTriggerNextTime()/1000)%60);
// 任务放进时间轮
private void pushTimeRing(int ringSecond, int jobId){
// push async ring
List ringItemData = ringData.get(ringSecond);
if (ringItemData == null) {
ringItemData = new ArrayList();
ringData.put(ringSecond, ringItemData);
}
ringItemData.add(jobId);
}
// 同时取两个时间刻度的任务
List ringItemData = new ArrayList<>();
int nowSecond = Calendar.getInstance().get(Calendar.SECOND);
// 避免处理耗时太长,跨过刻度,向前校验一个刻度;
for (int i = 0; i < 2; i++) {
List tmpData = ringData.remove( (nowSecond+60-i)%60 );
if (tmpData != null) {
ringItemData.addAll(tmpData);
}
}
// 运行
for (int jobId: ringItemData) {
JobTriggerPoolHelper.trigger(jobId, TriggerTypeEnum.CRON, -1, null, null);
}
`
一致性Hash路由中的Hash算法
大家也知道,
XXL-JOB在执行任务时,任务具体在哪个执行器上运行是根据路由策略来决定的,其中有一个策略是一致性Hash策略(源码在ExecutorRouteConsistentHash.java),自然而然想到了一致性Hash算法 。一致性Hash算法 是为了解决分布式系统中负载均衡的问题时候可以使用Hash算法让固定的一部分请求落到同一台服务器上,这样每台服务器固定处理一部分请求(并维护这些请求的信息),起到负载均衡的作用。
普通的余数hash(hash(比如用户id)%服务器机器数)算法伸缩性很差,当新增或者下线服务器机器时候,用户id与服务器的映射关系会大量失效。一致性hash则利用hash环对其进行了改进。
一致性Hash算法 在实践中,当服务器节点比较少的时候会出现上节所说的一致性hash倾斜的问题,一个解决方法是多加机器,但是加机器是有成本的,那么就加虚拟节点 。
下图为带有虚拟节点的Hash环,其中ip1-1是ip1的虚拟节点,ip2-1是ip2的虚拟节点,ip3-1是ip3的虚拟节点。
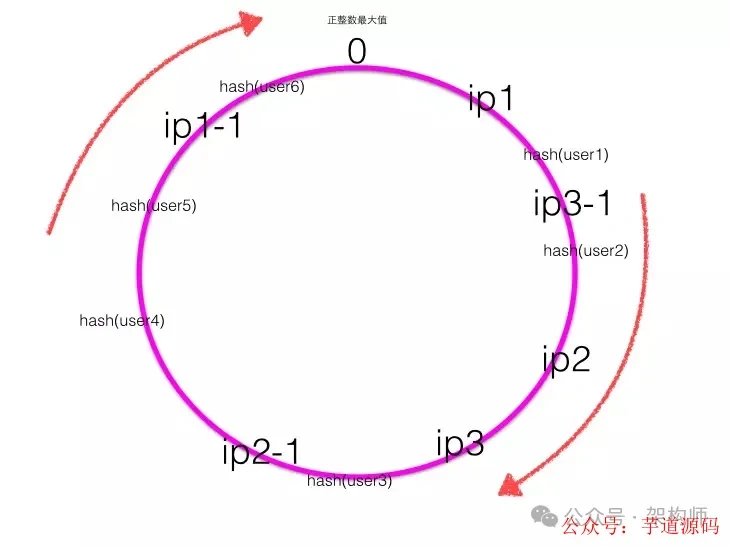
可见 ,一致性Hash算法的关键在于Hash算法 ,保证虚拟节点 及Hash结果 的均匀性,而均匀性可以理解为减少Hash冲突 ,Hash冲突的知识点本文暂不扩展,历史文章中有。或者将来我再抽时间写。
- XXL-JOB中的一致性Hash的Hash函数如下。
`// jobId转换为md5
// 不直接用hashCode() 是因为扩大hash取值范围,减少冲突
byte[] digest = md5.digest();
// 32位hashCode
long hashCode = ((long) (digest[3] & 0xFF) << 24)
| ((long) (digest[2] & 0xFF) << 16)
| ((long) (digest[1] & 0xFF) << 8)
| (digest[0] & 0xFF);
long truncateHashCode = hashCode & 0xffffffffL;
`
- 看到上图的Hash函数,让我想到了
HashMap的Hash函数
f(key) = hash(key) & (table.length - 1)
// 使用>>> 16的原因,hashCode()的高位和低位都对f(key)有了一定影响力,使得分布更加均匀,散列冲突的几率就小了。
hash(key) = (h = key.hashCode()) ^ (h >>> 16)
- 同理,将jobId的md5编码的高低位都对Hash结果有影响,使得Hash冲突的概率减小。
分片任务的实现 - 维护线程上下文
XXL-JOB的分片任务实现了任务的分布式执行,其实是笔者调研的重点,日常开发中很多定时任务都是单机执行,对于后续数据量大的任务最好有一个分布式的解决方案。
分片任务的路由策略,源代码作者提出了分片广播 的概念,刚开始还有点摸不清头脑,看了源码逐渐清晰了起来。
想必看过源码的也遇到过这么一个小插曲,路由策略咋没实现?如下图所示。
public enum ExecutorRouteStrategyEnum {
FIRST(I18nUtil.getString("jobconf_route_first"), new ExecutorRouteFirst()),
LAST(I18nUtil.getString("jobconf_route_last"), new ExecutorRouteLast()),
ROUND(I18nUtil.getString("jobconf_route_round"), new ExecutorRouteRound()),
RANDOM(I18nUtil.getString("jobconf_route_random"), new ExecutorRouteRandom()),
CONSISTENT_HASH(I18nUtil.getString("jobconf_route_consistenthash"), new ExecutorRouteConsistentHash()),
LEAST_FREQUENTLY_USED(I18nUtil.getString("jobconf_route_lfu"), new ExecutorRouteLFU()),
LEAST_RECENTLY_USED(I18nUtil.getString("jobconf_route_lru"), new ExecutorRouteLRU()),
FAILOVER(I18nUtil.getString("jobconf_route_failover"), new ExecutorRouteFailover()),
BUSYOVER(I18nUtil.getString("jobconf_route_busyover"), new ExecutorRouteBusyover()),
// 说好的实现呢???竟然是null
SHARDING_BROADCAST(I18nUtil.getString("jobconf_route_shard"), null);
- 再继续追查得到了结论,待我慢慢道来,首先分片任务执行参数传递的是什么?看
XxlJobTrigger.trigger函数中的一段代码。
...
// 如果是分片路由,走的是这段逻辑
if (ExecutorRouteStrategyEnum.SHARDING_BROADCAST == ExecutorRouteStrategyEnum.match(jobInfo.getExecutorRouteStrategy(), null)
&& group.getRegistryList() != null && !group.getRegistryList().isEmpty()
&& shardingParam == null) {
for (int i = 0; i < group.getRegistryList().size(); i++) {
// 最后两个参数,i是当前机器在执行器集群当中的index,group.getRegistryList().size()为执行器总数
processTrigger(group, jobInfo, finalFailRetryCount, triggerType, i, group.getRegistryList().size());
}
}
...
- 参数经过自研RPC传递到执行器,在执行器中具体负责任务执行的
JobThread.run中,看到了如下代码。
// 分片广播的参数比set进了ShardingUtil
ShardingUtil.setShardingVo(new ShardingUtil.ShardingVO(triggerParam.getBroadcastIndex(), triggerParam.getBroadcastTotal()));
...
// 将执行参数传递给jobHandler执行
handler.execute(triggerParamTmp.getExecutorParams())
- 接着看
ShardingUtil,才发现了其中的奥秘,请看代码。
`public class ShardingUtil {
// 线程上下文
private static InheritableThreadLocal contextHolder = new InheritableThreadLocal();
// 分片参数对象
public static class ShardingVO {
private int index; // sharding index
private int total; // sharding total // 次数省略 get/set
}
// 参数对象注入上下文
public static void setShardingVo(ShardingVO shardingVo){
contextHolder.set(shardingVo);
}
// 从上下文中取出参数对象
public static ShardingVO getShardingVo(){
return contextHolder.get();
}
}
`
- 显而易见,在负责分片任务的
ShardingJobHandler里取出了线程上下文中的分片参数,这里也给个代码把~
`@JobHandler(value=”shardingJobHandler”)
@Service
public class ShardingJobHandler extends IJobHandler {
@Override
public ReturnT execute(String param) throws Exception {
// 分片参数
ShardingUtil.ShardingVO shardingVO = ShardingUtil.getShardingVo();
XxlJobLogger.log(“分片参数:当前分片序号 = {}, 总分片数 = {}”, shardingVO.getIndex(), shardingVO.getTotal());
// 业务逻辑
for (int i = 0; i < shardingVO.getTotal(); i++) {
if (i == shardingVO.getIndex()) {
XxlJobLogger.log(“第 {} 片, 命中分片开始处理”, i);
} else {
XxlJobLogger.log(“第 {} 片, 忽略”, i);
}
}
return SUCCESS;
}
}
`
由此得出,分布式实现是根据分片参数
index及total来做的,简单来讲,就是给出了当前执行器的标识,根据这个标识将任务的数据或者逻辑进行区分,即可实现分布式运行。题外话:至于为什么用外部注入分片参数的方式,不直接
execute传递?
❝
1、可能是因为只有分片任务才用到这两个参数
2、IJobHandler只有String类型参数
看完源码后的思考
1、经过此次看源代码,XXL-JOB的设计目标确实符合开发迅速、学习简单、轻量级、易扩展 。
2、至于自研RPC还没有具体考量,具体接入应该会考虑公司的RPC框架。
3、作者给出的
Quartz调度的不足,笔者得继续深入了解。4、框架中很多对宕机、故障、超时等异常状况的兼容值得学习。
5、Rolling日志以及日志系统实现需要继续了解。
欢迎加入我的知识星球,全面提升技术能力。
本作品采用《CC 协议》,转载必须注明作者和本文链接





 关于 LearnKu
关于 LearnKu




推荐文章: