
MySQL同步到Flink解决数据归档问题(二)终极篇
18 / 0 / 创建于 1年前 /
 MissYou-Coding 的个人博客
MissYou-Coding 的个人博客
MySQL 数据归档操作手册:使用 Flink CDC 技术
上个文章提到MYSQL存储过大需要备份后再删除元数据,但有时候为了保持数据的完整性,该怎样解决呢,为了解决这个问题,可以考虑使用 Flink CDC 技术将历史数据归档,以减轻主数据库的负担并提高性能。以下是详细的实现原理、优缺点分析及操作手册。
插叙:我是实战效果
- 准备一台已经安装了Docker的Linux,实体机环境也可以。
使用下面的内容创建一个docker-compose.yml文件:[root@localhost online-flink]# more docker-compose.yml version: '2.1' services: postgres: image: debezium/example-postgres:1.1 ports: - "5432:5432" environment: - POSTGRES_DB=postgres - POSTGRES_USER=postgres - POSTGRES_PASSWORD=postgres mysql: image: debezium/example-mysql:1.1 ports: - "3306:3306" environment: - MYSQL_ROOT_PASSWORD=123456 - MYSQL_USER=mysqluser - MYSQL_PASSWORD=mysqlpw elasticsearch: image: elastic/elasticsearch:7.6.0 environment: - cluster.name=docker-cluster - bootstrap.memory_lock=true - "ES_JAVA_OPTS=-Xms512m -Xmx512m" - discovery.type=single-node ports: - "9200:9200" - "9300:9300" ulimits: memlock: soft: -1 hard: -1 nofile: soft: 65536 hard: 65536 kibana: image: elastic/kibana:7.6.0 ports: - "5601:5601" [root@localhost online-flink]# - 启动程序: flink-1.13.2

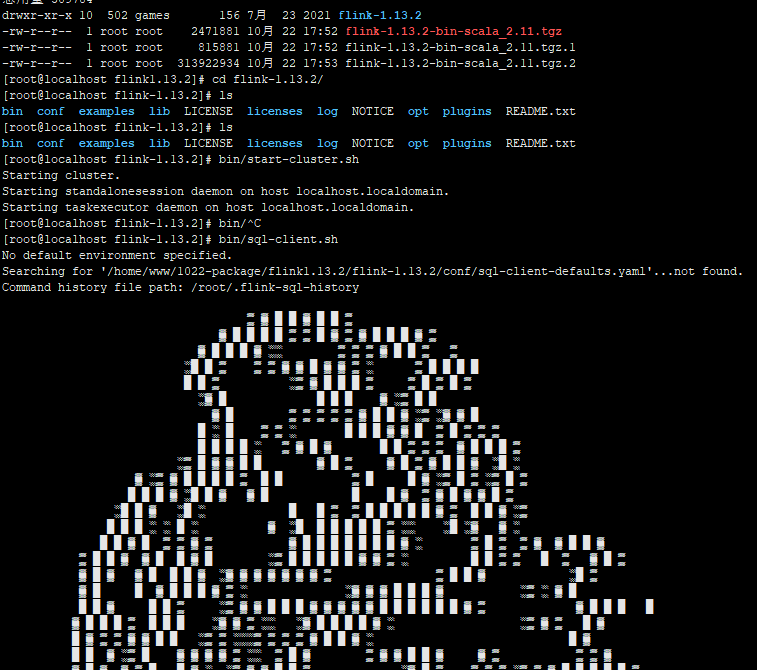
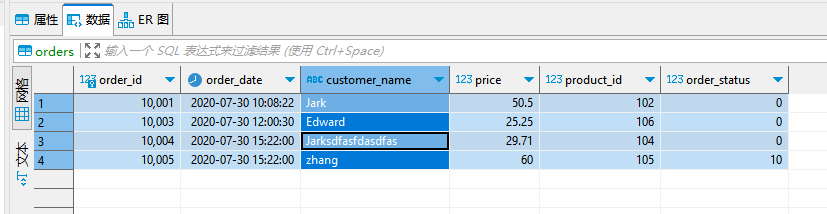
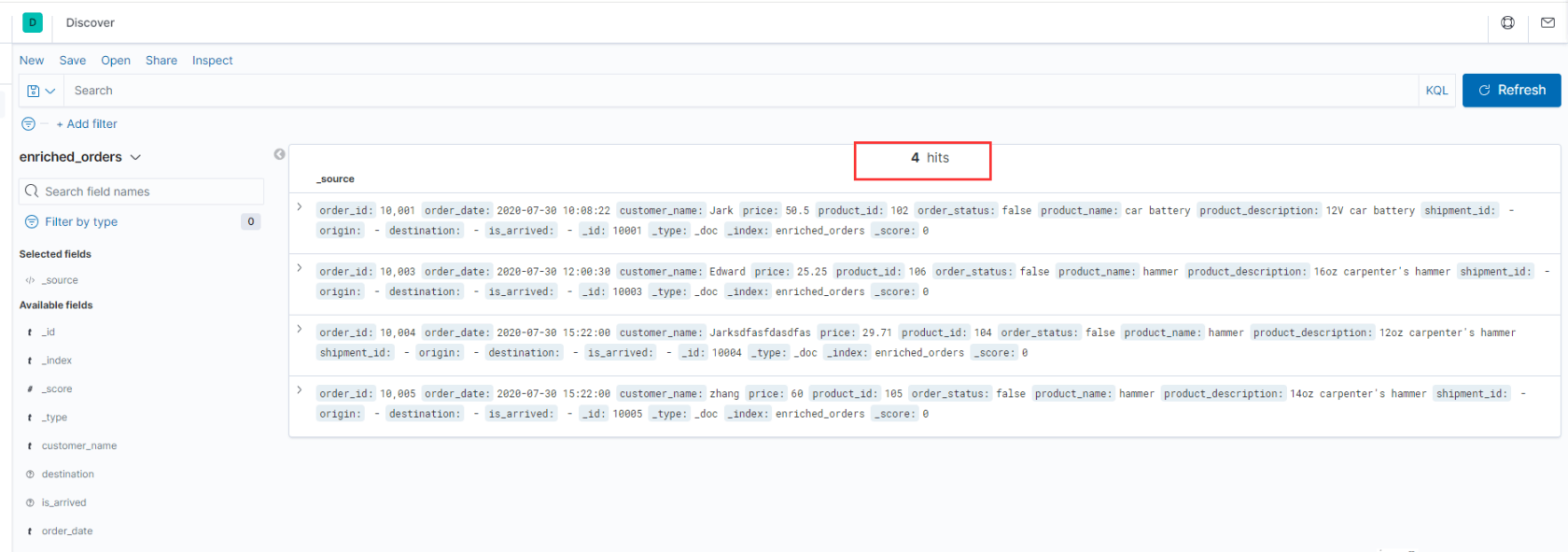
**数据变化时,ES变化效果: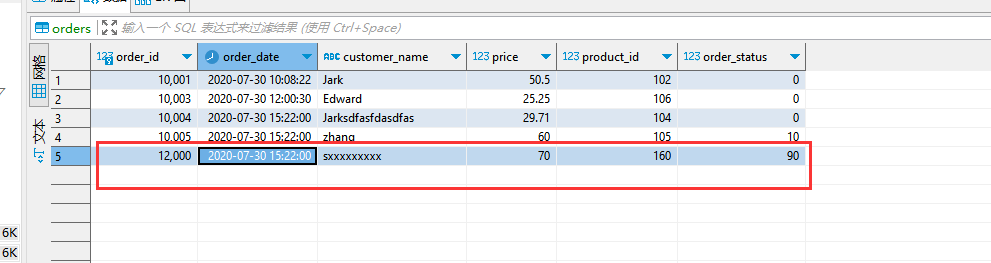
" class="reference-link">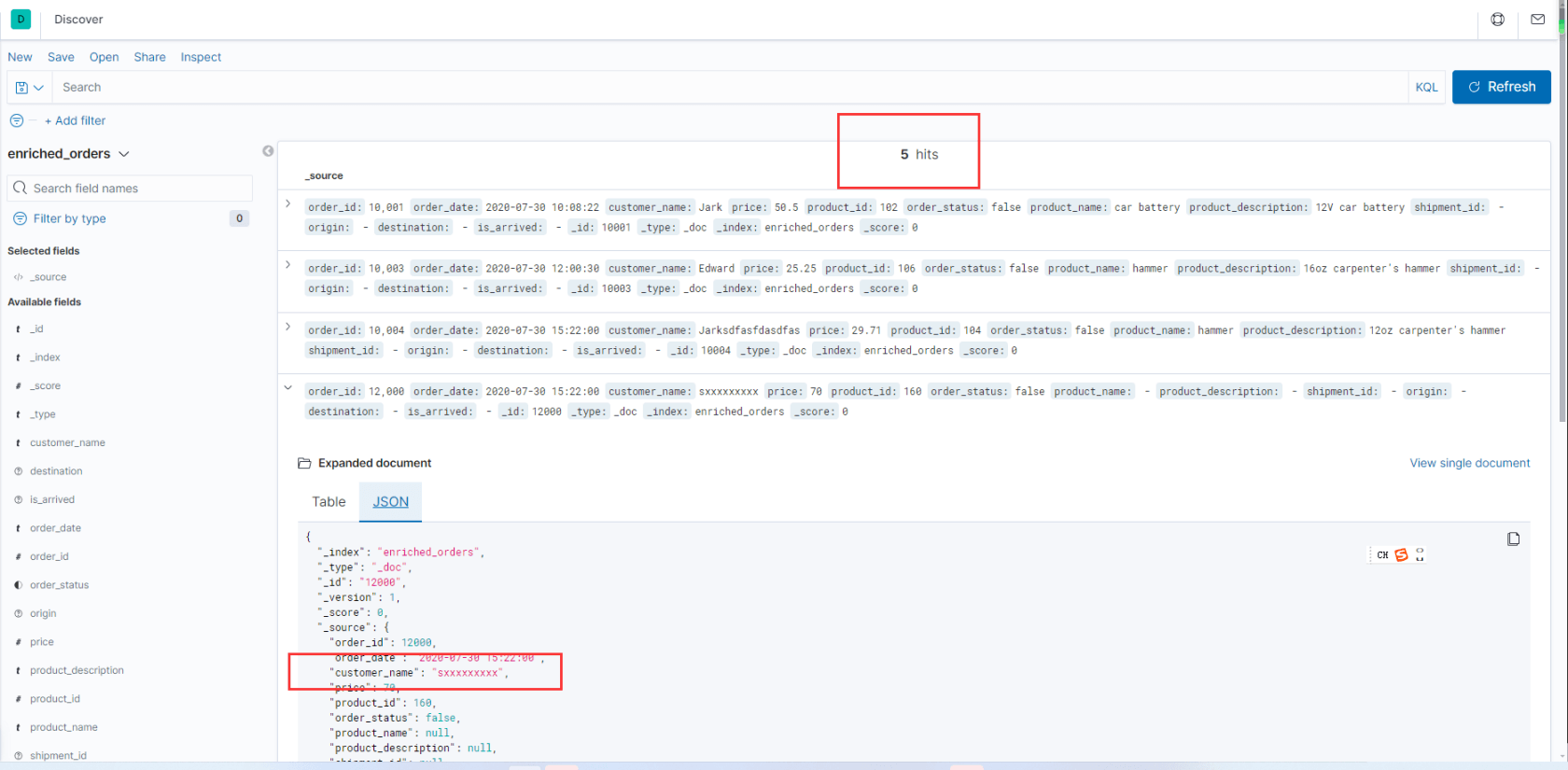
一、实现原理
- 数据提取:
- 使用 Flink CDC(Change Data Capture)技术连接 MySQL 数据库,实时捕获数据变更。Flink CDC 能够监听数据库的变更事件,包括插入、更新和删除操作,具体通过监听 MySQL 的 binlog(binary log)来完成。
- 变更数据捕获(CDC):Flink CDC 通过 binlog 捕获 MySQL 数据库中所有更改的日志。MySQL 的 binlog 记录了插入、更新、删除等所有操作。
- 连接 MySQL:使用 MySQL JDBC 驱动程序建立与 MySQL 的连接,提供必要的数据库信息(如主机、端口、用户名和密码)。
- 配置 CDC 来源:通过 Flink 的 Source API,指定 MySQL 为数据源,并设置监控的数据库和表,以捕获特定的数据。
- 数据类型映射:Flink 根据 MySQL 表的模式自动识别数据类型,进行内部映射,以确保后续处理中的数据类型不出现错误。
- 事件流:一旦配置完毕,Flink 开始监控 binlog 中的数据变更事件,这些事件会以数据流的形式被处理。
- 数据筛选:
- 在提取过程中,可以根据业务需求筛选出需要归档的数据,例如依据时间戳、状态等条件选择历史数据。
- 数据转换:
- 对提取的数据进行适当的转换,以适应 Elasticsearch 或其他存储系统的格式要求,可能包括字段重命名、数据类型转化、格式化等。
- 数据存储:
- 将筛选及转换后的数据存储到低成本的存储系统,如冷存储(HDFS、AWS S3 等)或归档数据库。
- 主数据库清理:
- 在确认数据成功归档后,从 MySQL 中删除已归档的数据,以减少主数据库的负担。
二、优缺点分析
优点:
- 性能提升:
- 通过将历史数据归档,可以显著减轻 MySQL 数据库的压力,优化数据查询性能,改善应用接口的响应时间。
- 实时更新:
- 使用 Flink CDC,能够实现对数据变更的实时响应,确保归档过程中的数据一致性。
- 灵活存储:
- 实现复杂性:
- 引入 Flink 和 CDC 的技术栈增加了系统的复杂度,可能需要更多的开发和维护资源。
- 延迟风险:
- 在归档过程中,数据在 MySQL 与目标存储之间的传输可能会导致延迟,需考虑系统的实时性需求。
- 数据恢复:
- 如果需要从归档数据中恢复信息,可能会涉及更多操作和时间,增加数据管理难度。
三、操作手册
以下是实现数据归档的详细步骤:
1. 环境准备
- 确保 MySQL 数据库和目标存储(如 HDFS 或 S3)已部署并可访问。
- 安装并配置 Apache Flink 和 Flink CDC。
- 配置 Flink 和 Elasticsearch(或其他目标存储)的连接器。
2. 数据提取与处理
- 连接 MySQL:
- 使用 Flink CDC 连接到 MySQL 数据库,以便捕获变更事件。
- 编写 Flink 作业:
- 数据格式转换:
- 写入目标存储:
- 删除已归档数据:
- 监控 Flink 作业:
- 监控 Flink 作业的运行状态,确保数据流动的正常进行。
- 定期评估:
- 定期评估数据归档策略,根据业务需求调整数据归档频率和策略。
结论
通过本操作手册,可以有效地将数据从 MySQL 归档至低成本存储,提高查询性能,确保用户体验。使用 Flink CDC 技术的实时性和灵活性,能够优化系统整体架构。运行过程中,需注意系统复杂性和数据恢复的问题,以便维护数据的完整性和一致性。
参考手册:flink-tpc-ds.github.io/flink-cdc-c...
源代码及插件都包含在内获取:
我用夸克网盘分享了「flink1.13.2.7z」,点击链接即可保存。打开「夸克APP」,无需下载在线播放视频,畅享原画5倍速,支持电视投屏。
链接:pan.quark.cn/s/3a38b4df0347
提取码:HrA5
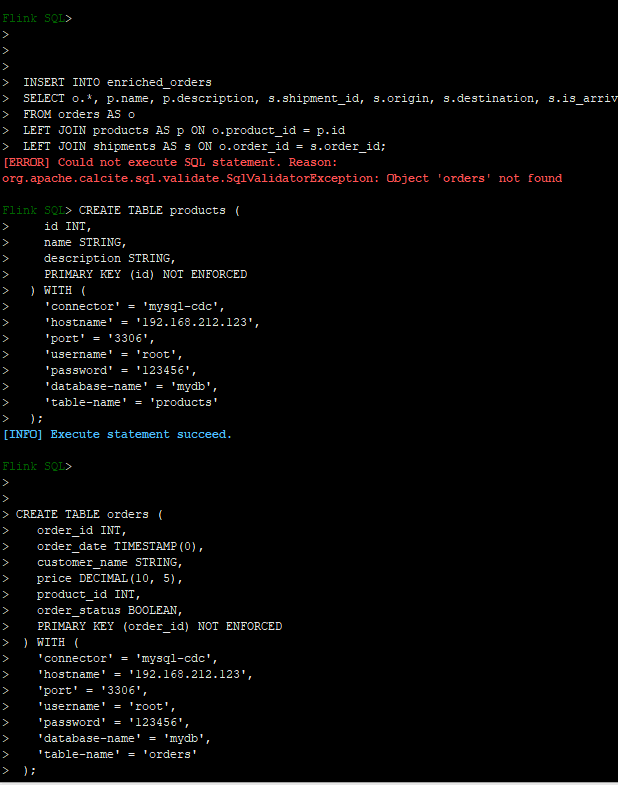
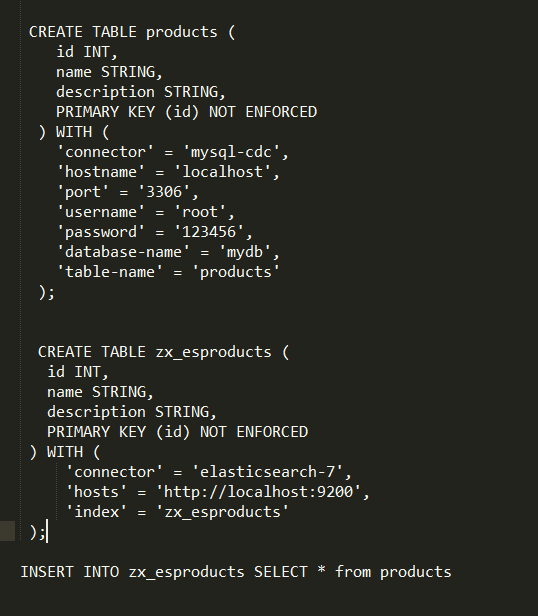
补充一下sql
CREATE TABLE products (
id INT,
name STRING,
description STRING,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = '192.168.212.123',
'port' = '3306',
'username' = 'root',
'password' = '123456',
'database-name' = 'mydb',
'table-name' = 'products'
);
CREATE TABLE orders (
order_id INT,
order_date TIMESTAMP(0),
customer_name STRING,
price DECIMAL(10, 5),
product_id INT,
order_status BOOLEAN,
PRIMARY KEY (order_id) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = '192.168.212.123',
'port' = '3306',
'username' = 'root',
'password' = '123456',
'database-name' = 'mydb',
'table-name' = 'orders'
);
CREATE TABLE shipments (
shipment_id INT,
order_id INT,
origin STRING,
destination STRING,
is_arrived BOOLEAN,
PRIMARY KEY (shipment_id) NOT ENFORCED
) WITH (
'connector' = 'postgres-cdc',
'hostname' = '192.168.212.123',
'port' = '5432',
'username' = 'postgres',
'password' = 'postgres',
'database-name' = 'postgres',
'schema-name' = 'public',
'table-name' = 'shipments'
);
CREATE TABLE enriched_orders (
order_id INT,
order_date TIMESTAMP(0),
customer_name STRING,
price DECIMAL(10, 5),
product_id INT,
order_status BOOLEAN,
product_name STRING,
product_description STRING,
shipment_id INT,
origin STRING,
destination STRING,
is_arrived BOOLEAN,
PRIMARY KEY (order_id) NOT ENFORCED
) WITH (
'connector' = 'elasticsearch-7',
'hosts' = 'http://192.168.212.123:9200',
'index' = 'enriched_orders'
);
本作品采用《CC 协议》,转载必须注明作者和本文链接





 关于 LearnKu
关于 LearnKu



