
 从零开始的 TensorFlow
从零开始的 TensorFlow初识 Fashion MNIST
前言
从本章开始,将记录对官方文档中基本分类篇的剖析和理解。
基本分类文档主要对计算机视觉的基础进行演示和简要讲解,其实质就是第一章的新手代码。就是对 70000 张服装图像数据集进行训练和测试的过程
-
官方文档地址
导入库
# 引入未来版本新特性,作用是在使用 Python2 时能够兼容 Python3 的语法
from __future__ import absolute_import, division, print_function, unicode_literals
# 导入 TensorFlow 和 tf.keras
import tensorflow as tf
from tensorflow import keras
# 导入辅助库
import numpy as np
import matplotlib.pyplot as plt
# 输出 TensorFlow 的版本号
print(tf.__version__)注意:刚复制这段代码到 IDE 中时,可能提示 matplotlib 包未安装。所以需要安装一下 matplotlib 包:
pip install matplotlib关于 __future__ 官方地址 --> 传送门
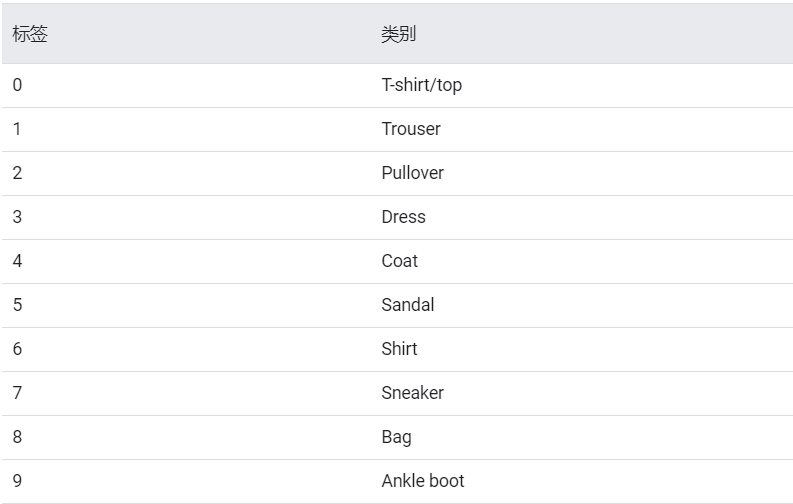
train_images、train_labels、test_images、test_labels 简介
-
train_images:用来训练的 60000 张图片

-
train_labels:用来训练的 60000 个图片分类(0-9),共 10 种
-
test_images:用来测试的 10000 张图片
-
test_labels:用来测试的 10000 个图片分类
训练数据和测试数据的获取
# 从 tf.keras 中获取 fashion_mnist 对象
fashion_mnist = keras.datasets.fashion_mnist
# 调用 fashion_mnist 对象的 load_data() 方法,获取训练数据和测试数据
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()下面我们来详细查看 load_data() 方法的源码
# Python2 兼容 python3 的语法
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
# 导入 gzip 和 os 标准库
import gzip
import os
# 导入 numpy
import numpy as np
# 导入工具类
from tensorflow.python.keras.utils.data_utils import get_file
from tensorflow.python.util.tf_export import keras_export
@keras_export('keras.datasets.fashion_mnist.load_data')
def load_data():
# 根据系统生成合理相对路径 datasets\\fashion-mnist
dirname = os.path.join('datasets', 'fashion-mnist')
# 数据包网络位置
base = 'https://storage.googleapis.com/tensorflow/tf-keras-datasets/'
# 数据包名称
files = [
'train-labels-idx1-ubyte.gz', 'train-images-idx3-ubyte.gz',
't10k-labels-idx1-ubyte.gz', 't10k-images-idx3-ubyte.gz'
]
# 下载网络数据到本地,并记录数据在本地的绝对地址
paths = []
for fname in files:
# 重点就是这个 get_file 方法,实现了网络路径到本地路径的转换(俗称下载)
paths.append(get_file(fname, origin=base + fname, cache_subdir=dirname))
with gzip.open(paths[0], 'rb') as lbpath:
y_train = np.frombuffer(lbpath.read(), np.uint8, offset=8)
with gzip.open(paths[1], 'rb') as imgpath:
x_train = np.frombuffer(
imgpath.read(), np.uint8, offset=16).reshape(len(y_train), 28, 28)
with gzip.open(paths[2], 'rb') as lbpath:
y_test = np.frombuffer(lbpath.read(), np.uint8, offset=8)
with gzip.open(paths[3], 'rb') as imgpath:
x_test = np.frombuffer(
imgpath.read(), np.uint8, offset=16).reshape(len(y_test), 28, 28)
return (x_train, y_train), (x_test, y_test)通过上面,我们知道了从网络数据到本地数据的核心方法:get_file
## 传进来的参数如下:
# fname: 文件名称
# origin: 远程文件地址
# cache_subdir:本地相对地址
@keras_export('keras.utils.get_file')
def get_file(fname,
origin,
untar=False,
md5_hash=None,
file_hash=None,
cache_subdir='datasets',
hash_algorithm='auto',
extract=False,
archive_format='auto',
cache_dir=None):
# cache_dir 如何是 None 则,生成 家目录 + .keras。如 window 就是 C:\Users\Administrator\.keras
if cache_dir is None:
cache_dir = os.path.join(os.path.expanduser('~'), '.keras')
# 如果传入 md5_hash 则优先使用
if md5_hash is not None and file_hash is None:
file_hash = md5_hash
hash_algorithm = 'md5'
datadir_base = os.path.expanduser(cache_dir)
# 如果家目录没有写权限,那就到在根目录下建立 tmp 目录
if not os.access(datadir_base, os.W_OK):
datadir_base = os.path.join('/tmp', '.keras')
# 拼接 datadir_base 和 cache_subdir 生成完整本地绝对路径
datadir = os.path.join(datadir_base, cache_subdir)
# 检测本地绝对路径目录存在吗,不存在就创建
if not os.path.exists(datadir):
os.makedirs(datadir)
# 文件名是否启用扩展优化
if untar:
untar_fpath = os.path.join(datadir, fname)
fpath = untar_fpath + '.tar.gz'
else:
fpath = os.path.join(datadir, fname)
download = False
# 检测本地现存数据的 hash 与远程 hash 是否一致,不一致则重新下载
if os.path.exists(fpath):
# File found; verify integrity if a hash was provided.
if file_hash is not None:
if not validate_file(fpath, file_hash, algorithm=hash_algorithm):
print('A local file was found, but it seems to be '
'incomplete or outdated because the ' + hash_algorithm +
' file hash does not match the original value of ' + file_hash +
' so we will re-download the data.')
download = True
else:
download = True
# 启用下载,并声明进度条
if download:
print('Downloading data from', origin)
class ProgressTracker(object):
# Maintain progbar for the lifetime of download.
# This design was chosen for Python 2.7 compatibility.
progbar = None
def dl_progress(count, block_size, total_size):
if ProgressTracker.progbar is None:
if total_size == -1:
total_size = None
ProgressTracker.progbar = Progbar(total_size)
else:
ProgressTracker.progbar.update(count * block_size)
error_msg = 'URL fetch failure on {}: {} -- {}'
try:
try:
# 进行文件下载,主要运用 Python 的 urllib.request 库,进行下载和本地写入
urlretrieve(origin, fpath, dl_progress)
except HTTPError as e:
raise Exception(error_msg.format(origin, e.code, e.msg))
except URLError as e:
raise Exception(error_msg.format(origin, e.errno, e.reason))
except (Exception, KeyboardInterrupt) as e:
if os.path.exists(fpath):
os.remove(fpath)
raise
ProgressTracker.progbar = None
if untar:
if not os.path.exists(untar_fpath):
_extract_archive(fpath, datadir, archive_format='tar')
return untar_fpath
if extract:
_extract_archive(fpath, datadir, archive_format)
# 最后返回本地数据的绝对路径
return fpath关于 urlretrieve 方法,我们看一下
if sys.version_info[0] == 2:
def urlretrieve(url, filename, reporthook=None, data=None):
def chunk_read(response, chunk_size=8192, reporthook=None):
content_type = response.info().get('Content-Length')
total_size = -1
if content_type is not None:
total_size = int(content_type.strip())
count = 0
while True:
chunk = response.read(chunk_size)
count += 1
if reporthook is not None:
reporthook(count, chunk_size, total_size)
if chunk:
yield chunk
else:
break
response = urlopen(url, data)
with open(filename, 'wb') as fd:
for chunk in chunk_read(response, reporthook=reporthook):
fd.write(chunk)
else:
from six.moves.urllib.request import urlretrieve注意,大家都看到了第一行 if sys.version_info[0] == 2:。这是什么意思呢,简单讲:就是判断 python 版本是不是 2.X ,如果是,直接定义 urlretrieve 函数。否则从 request 库中导入 urlretrieve。
关于 sys.version_info --> 传送门
由于我的 python 是 3.7 ,所以 urlretrieve 方法实际在 request 库中:
def urlretrieve(url, filename=None, reporthook=None, data=None):
# 从 URL 中分离协议和路由:'https://www.test.com/test' --> ('https', '//www.test.com/test')
url_type, path = splittype(url)
# urlopen 从 URL 获取远程资源
with contextlib.closing(urlopen(url, data)) as fp:
headers = fp.info()
if url_type == "file" and not filename:
return os.path.normpath(path), headers
if filename:
tfp = open(filename, 'wb')
else:
tfp = tempfile.NamedTemporaryFile(delete=False)
filename = tfp.name
_url_tempfiles.append(filename)
with tfp:
result = filename, headers
bs = 1024*8
size = -1
read = 0
blocknum = 0
if "content-length" in headers:
size = int(headers["Content-Length"])
if reporthook:
reporthook(blocknum, bs, size)
while True:
block = fp.read(bs)
if not block:
break
read += len(block)
tfp.write(block)
blocknum += 1
if reporthook:
reporthook(blocknum, bs, size)
if size >= 0 and read < size:
raise ContentTooShortError(
"retrieval incomplete: got only %i out of %i bytes"
% (read, size), result)
return result关于 urlopen 方法 --> 传送门
结果
-
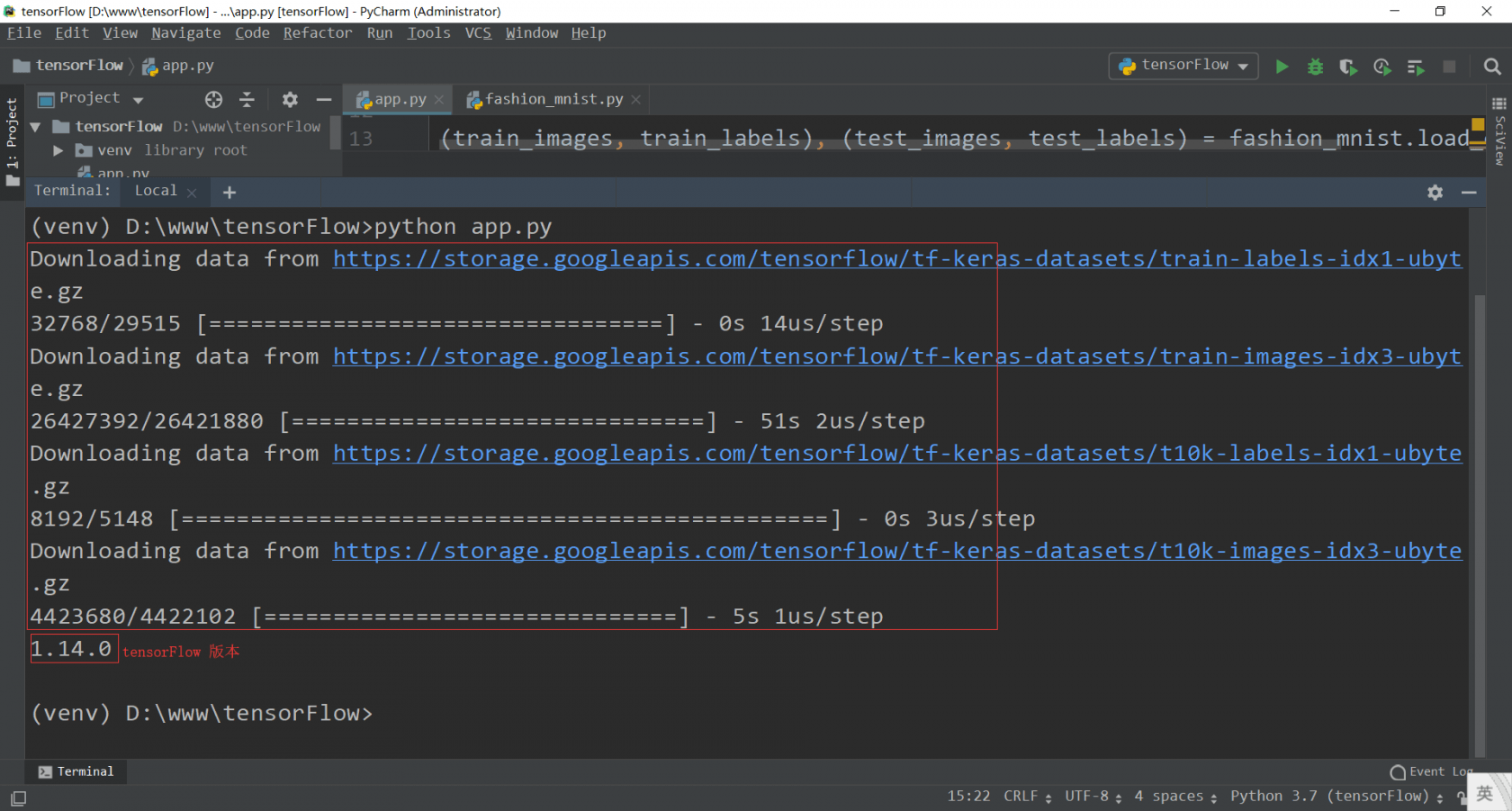
命令行运行
-
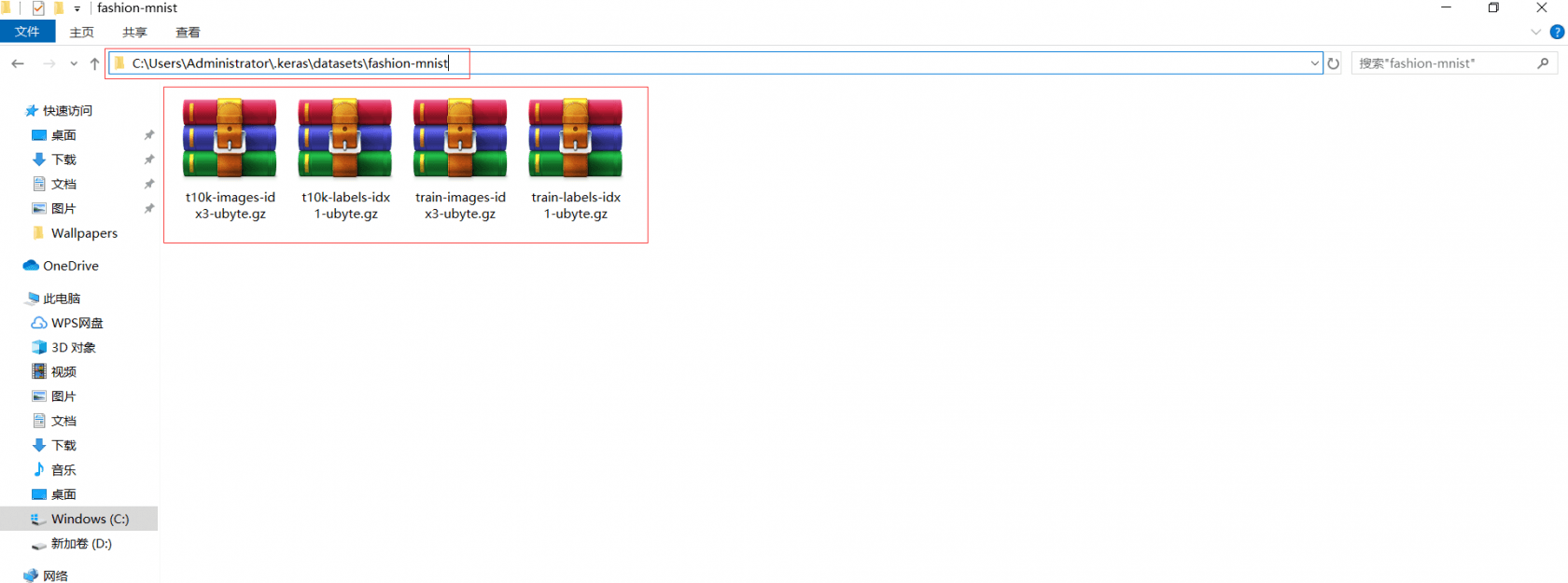
下载到本地文件的位置


 关于 LearnKu
关于 LearnKu




推荐文章: