
[转载] 阿里云 Elasticsearch 实践(最大限度提高写入速度)
ES学习文档
- 最权威的,当然就是官方文档,根据自己所安装的版本进行选择:elasticsearch所有版本参考文档
- 如果英文文档阅读有困难,参考:Elasticsearch: 权威指南,但是中文文档有滞后性,比如目前es已经到6.X版本,而中文文档以2.X版本为基础,因此对于新版本的话会有部分不适用。
- 参考博客:铭毅天下
使用阿里云 elasticsearch
使用阿里云 elasticsearch服务,就可以不用再自己安装elasticsearch,购买后即可立即使用,方便快捷。
如果使用java客户端进行访问会有限制:
Java语言

具体请参考:阿里云elasticsearch介绍
elasticsearch插件
head插件
通过head插件连接es,可以从界面上进行可视化查看集群健康值、索引名称、类型名称,同时可进行基本查询以及es本身的DSL复杂查询
head插件可以直接使用360或者谷歌浏览器插件直接安装即可,不用再另外安装,下载地址:es head插件
X-PACK插件
可以提供身份验证,更好的保证数据安全。阿里云elasticsearch已经集成了X-PACK
IK分词插件
常用中文分词插件,阿里云elasticsearch已经有预置该插件,可以直接进行分词使用
阿里云elasticsearch实践
- 同步数据库数据到es包含两个过程,一个是从数据库中查出指定的数据,一个是将数据库查出来的数据保存到es中
- 阿里云elasticsearch规格选用
cpu:4核
内存:16G
硬盘:256GB SSD(强烈建议使用固态硬盘,固态硬盘对于es的同步、更新效率有巨大的提升空间)
集群节点:3 - 一般我们初始化数据到es的时候,数据量是非常大的,可能有几千万直至上亿,因此对于查询的sql一定要优化到非常快
- 保存数据到es也是优化的重点,以下将列出所有优化步骤:
一定要用bulk批量提交
elasticsearch允许单次提交数据在15M以内,也不能过大,不然有可能会失败,因此我们可以批量查出多条数据(具体要多少数据才进行bulk条要看字段的多少,可以先保存部分数据到es验证下,目前总共占用多少容量,然后推算)。。千万不要用一条条提交,这个对于写入有巨大的提升!
禁用_all字段
_all字段是elasticsearch在保存的时候会自己生成一个字段,相当于将所有需要保存的数据全部冗余在这个字段里面,普通查询一般是用不到这个字段的,直接禁用掉:
http://localhost:9200/test_index/
{
"settings": {
"number_of_shards": 7
},
"mappings": {
"testRequest": {
"_all": {
"enabled": false
}
}
}
}注意:这里的number_of_shards这边设置为7(默认是5),那具体要怎么来确认到底需要创建多少分片数量呢?
请参考:es如何设置分片数量
提高硬盘的写入速率,前提是一定要固态硬盘!机械硬盘不能设置太高
http://localhost:9200/_cluster/settings/
{
"persistent": {
"indices.store.throttle.max_bytes_per_sec": "200mb"
}
}注意:persistent,表示是永久设置,将会写入到elasticsearch配置文件中
关闭段合并merge
http://localhost:9200/_cluster/settings/
{
"transient": {
"indices.store.throttle.type": "none"
}
}注意:transient,表示是临时设置,一旦elasticsearch重启,这个配置会立即失效。
更改副本分片为0(非常重要)
elasticsearch默认主分片数量是5,同时会生成对应的5个副本分片,每次在保存数据的时候会将主分片的数据拷贝到副本分片上,这个过程非常耗费资源,我们可以在初始化同步过程中先将副本分片数量改为0,等同步完成后再将副本分片改回5,这样在我们改回来之后就只会有一次的复制主分片数据到副本分片数据的过程,可极大提升同步效率
http://localhost:9200/test_index/_settings/
{
"index": {
"number_of_replicas": 0
}
}设置refresh刷新间隔为不刷新
http://localhost:9200/test_index/_settings/
{
"index": {
"refresh_interval": "-1"
}
}设置数据flush方式为异步,且加大translog文件大小
http://localhost:9200/test_index/_settings/
{
"index.translog.durability": "async",
"index.translog.flush_threshold_size": "1024mb"
}保存完数据到elasticsearch后
由于在写入时为了最大限度提高写入速度,我们做了一些特殊配置,因此在同步完数据后,需要将对应的配置还原回来
开启段合并merge
http://localhost:9200/_cluster/settings/
{
"transient": {
"indices.store.throttle.type": "merge"
}
}恢复副本分片数量
http://localhost:9200/test_index/_settings/
{
"index": {
"number_of_replicas": 1
}
}设置refresh刷新间隔为1s
http://localhost:9200/test_index/_settings/
{
"index": {
"refresh_interval": "1s"
}
}设置flush同步方式为request,同时修改translog文件大小为512M
http://localhost:9200/test_index/_settings/
{
"index.translog.durability": "request",
"index.translog.flush_threshold_size": "512mb"
}验证结果
导入总条数:44000000条
数据容量大小:40G(加上副本分片共80G)
耗时:耗费2小时40分钟左右
elasticsearch服务器性能监控:
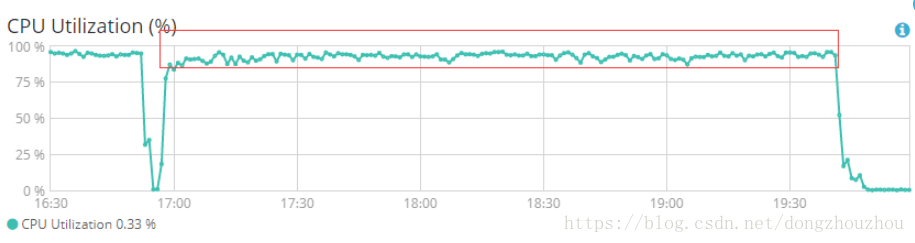
由上图可见:CPU的使用效率已经接近极限,可最大限度利用阿里云elasticsearch服务器性能






 关于 LearnKu
关于 LearnKu



