
[转载] Elasticsearch 读写中间件的设计
之前负责搜索系统的时候花了些时间在搜索中间件上,沉淀了一下拿出来跟大家分享。
一、背景
相比之下大家对数据库中间件的项目背景会比较熟悉,其实搜索中间件的项目背景也类似,搜索系统总的来说可以分两种,一种是业务为主的搜索推荐系统,另一种是以提供基础搜索服务能力为主的泛化的数据检索系统。
搜索中间件的服务目标就是这种泛化的平台化数据检索系统。
二、总体目标
根据前期的搜索平台运营经验,中间件的核心目标主要有三个:
引擎虚拟化:业务线不再需要感知具体的引擎地址(如具体的elasticsearch的ip/port),不需要了解集群的版本、配置、部署、高可用等。
支持索引拆分:让索引可以支持类似于db分库分表的操作,且具体的分库逻辑和规则对业务透明。
流量可控:支持限流、熔断。
三、需要实现的功能
制定了大目标之后,剩下就是任务拆解,具体来说,搜索中间件需要实现的功能如下:
1. 统一接入
搜索发展初期存在各种域名,对应不同的集群,也对应不同的业务:
wsc.search.yz.com:9200
wxd.search.yz.com:9200
fans.search.yz.com:9200
msg.search.yz.com:9200
fx.search.yz.com:9200
在统一接入之后,将会只有:
- search.yz.com
所有的业务线,对搜索的访问,只有一个入口,由搜索中间件进行鉴权和路由。
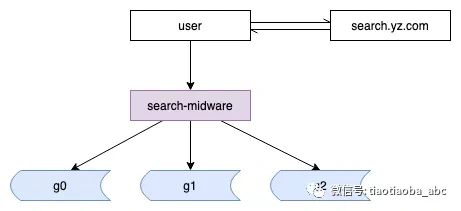
业务到索引的访问,统一到一个入口,通过中间件进行路由控制,这样对后端集群进行扩容、迁移、拆分等操作对业务来说透明,免去了很大的运维成本,也让我们在控制流量上有了更大的空间。
这里也可以根据实际需求分步实现,比如先统一单业务的访问域名,再统一全部业务的访问域名。
2. 保持访问
因为历史原因,访问搜索集群的方式多种多样,有通过原生DSL访问的,也有通过内部封装的业务协议请求的,甚至还有不同版本的协议样式。
保持访问,就是指让上游业务对搜索服务的访问接口尽量不用改变,中间件对上游业务访问的引擎进行无缝替。
3. 屏蔽多索引
根据业务需要或者性能上的考虑,后端集群会将流量导入到多个索引中,比如冷热隔离、或者类目/关键字检索隔离,中间件需要对业务屏蔽此类细节,由自己来对不同请求进行路由。
4. 支持索引拆分
我们支持容量伸缩的方式基本是通过索引拆分实现的(比通过索引内部的 _routing 容易控制,比如重建和迁移),db 的分库方式是在不同的实例中存在同样的表,db => db1.table / db2.table,索引拆分目前是分表的方式 es.index => es.index1 / es.index2。
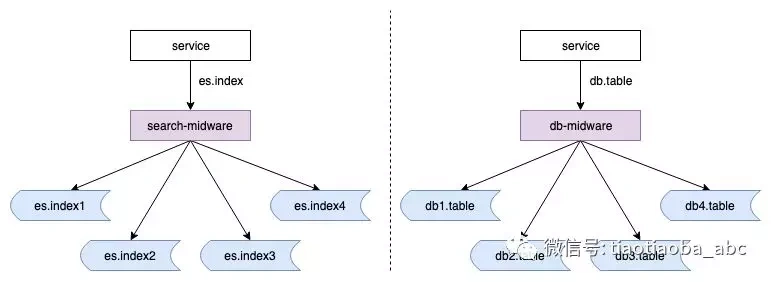
这样对业务层来说访问的始终是同一个索引,而不必感知实际细节,方便许多。
按照现有的业务使用方式,我们需要支持的拆分规则只需要下述四项即可:
按partition key取模拆分(比如 mod 拆分个数 => index${余数})
按partition key划段拆分(比如 0~100 / 100~500 / 500~)
按partition key取白名单拆分(比如 1、3、5 => index1 / 其余 =>index2)
按多个partition key组合拆分(比如白名单+取模,1、2 => index1 / 其余取模)
5. 熔断限流
为了保护搜索集群,在遇到流量抖动或者流量洪峰情况下,中间件需要对其进行必要的熔断或者限流处理,将问题的影响面控制到最低。
熔断和限流是不同的两种保护机制,熔断:保护集群高负载情况下在中间层将流量导流或者拒绝,可行的比如通过监测后端请求失败率,在失败率高时触发熔断。
限流是限制不同请求能使用的资源,避免流量之间的相互影响,具体的又可以分为两个方面:
能够自动限制某索引的某项操作,比如 A 索引的写操作
在资源空闲期自动调度流量分配,提高搜索集群的资源利用率
6. 高可用
高可用需要考虑中间件自身和搜索集群两部分。
中间件部分:
故障时流量自动迁移:可以通过client探测故障,如果非client方式,则通过nginx代理能探测故障并摘除故障节点。
故障处理:探测搜索集群失败率,统计自身的运行异常,并在数据异常时发出告警(也要搭配外部的保活工具)
搜索集群部分:
数据多活:将写入 A 集群的数据同步至 B 集群,补全引擎功能。
故障流量迁移:中间件探测搜索集群失败率,异常时自动切换到从集群(初期可以在失败率异常时发出告警,通过人工干预切换)
7. 可运维
这里目标是能够让开发和运维感知到中间件的运行数据,能够通过管理命令在运行时进行变更,当然能够提供界面化的操作最佳。
四、模块设计
1. 总体架构
为了透明切换业务访问到中间件,必须在中间件支持原生的server协议,并转换query到目标dsl发送到集群,之所以不是透传,主要是考虑到之后引擎升级可能产生与现有query不兼容的语法,总体架构如下:
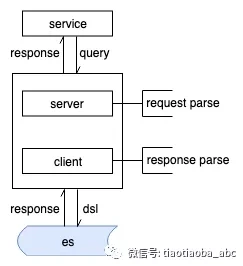
es对外提供transport和rest两种协议的服务接口,transport协议私有,并没有对外公开,如果要兼容这个协议,只能通过查找源代码中的序列化/反序列化模块,考虑到大部分场景下对协议的敏感度并没有我们想象的那么大,这里建议是舍弃transport访问协议,只支持rest部分,在server部分的处理上会简化不少。
2. 架构细节和组件划分
架构细节和内部的组件划分大致如下:
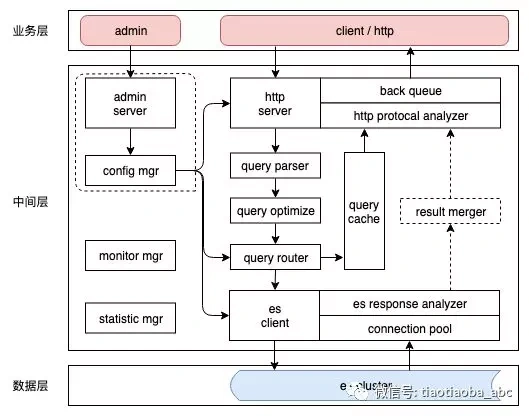
总的分为业务层、中间层、数据层三部分,其中中间层又可以分为管理子系统和业务子系统两部分。
- 业务层
上游业务可以使用rest风格的http协议、原生es http client或者通过我们封装的search-client调用搜索中间件,当然也可以支持监控任务或者开发、运维通过管理接口管理集群配置或者采集统计数据。
- 数据层
Es集群,作为承载数据查询和存储的介质,位于整个系统的最下游。
- 中间层-config mgr
配置管理初期可以通过本地的配置文件,但是当中间件集群扩大时,仍然使用本地文件的方式带来的维护成本太大,通常会考虑通过配置中心的方式,可以自行实现,也可以集成现有的如Apollo等开源配置管理中间件。
配置形式上不再继续展开,可以自行设计合适的组织形式。
- 中间层- httpserver
这部分负责对客户端的交互,back queue 作为请求队列除了扩大系统吞吐量,也是削峰限流的一部分,protocol analyzer用于解析客户端的http request为结构化的查询请求,这里还有几个问题需要处理:
异步io,在高吞吐的中间件支持异步调用是必要的,可以使用netty或者akka等异步通信框架
并发模型,io和业务处理异步化
上下文管理,多线程处理之后需要考虑请求中的特殊标记在线程间传递(可以通过改造线程池实现,参考es的设计)
连接管理,服务端超时、客户端超时
负载均衡,上游业务流量的负载均衡
失败探测,平滑上下线、失败节点探测摘除、自动发现新节点
权限验证,不同业务操作资源隔离
- 中间层- esclient
负责与 es 集群交互的部分,初期可以使用原生的low level http client,如果有多个版本 es 集群存在,可以考虑直接通过http client封装,可以更加方便的控制DSL拼接,也适合对 client 连接池的管理和监控。
- 中间层- query parser
解析查询,分解为原子条件,比如 term / terms / range / match 等,用来进行查询校验,可以分为非拆分索引和拆分索引两种:
非拆分索引:检查查询的window size是否过大,是否包含敏感词等,校验不通过的查询拒绝访问,比如:{‘query’: {‘match_all’:{}}, ‘start’: 100000, ’size’:10000} 属于非法查询,window size过大
拆分索引:除了上述检查项外,还需要检查查询中是否带有partition key,比如:{‘query’: {‘match_all’:{}}} 也属于非法查询,未带有partition key
- 中间层- query optimize
优化查询,是查询过程中比较重要的一环,可以分为两类:
具体的优化类型来源于日常运维过程中的慢查询分析,以一个实际场景来分析:某外部业务通过scroll低频查询es,遍历近5min内的客户数据,{‘query’: {‘bool’:{‘must’:[{’term’:{’shop_id’:1}},{‘range’:{‘follow_time’:{‘gt’:now-5min,’lt’:now}}}]}}, ‘start’: 0, ’size’:10}。此类查询存在大量占用filter cache的风险,这里就可以将其range优化为一个script查询,避免其被cache住(es禁用filter cache只能全局生效,不能单请求设置)。
另一类需要优化的查询是关键字检索相关的,比如将单个 50% match 条件优化为 match_phrase 和 50% match 的组合,用以提高匹配度,并保证召回。
查询优化器最后还需要将条件组合为具体的DSL。
- 中间层- query router
这部分负责路由转发,非拆分索引和只有单路由规则的拆分索引可以根据索引名选择对应的客户端连接发送请求即可。
比较复杂的是组合路由规则的拆分索引,为了尽可能提高查询执行效率,假设查询命中多个子索引,需要考虑将查询并行化,并通过 result merger 模块合并结果返回,这里的处理规则比较复杂,后续单独开文展开讨论。
- 中间层- query cache
为了提高集群性能考虑,这里会加入一个短时间的result cache,用于补齐引擎不提供的功能。
- 中间层其他功能模块
admin server:监听管理端口,接收运维操作指令
config mgr:配置中心,可以独立为一个服务或者集成第三方配置中心
monitor mgr:监控告警
statistic mgr:数据统计,可以通过管理端口对外保护统计数据采集接口
作者:tiaotiaoba
来源:跳跳爸的Abc
原文链接:mp.weixin.qq.com/s/g9_eXCouaaBobU9...






 关于 LearnKu
关于 LearnKu




推荐文章: