
[转载] Elasticsearch 索引和查询性能调优的 21 条建议 [上]
Elasticsearch是一款流行的分布式开源搜索和数据分析引擎,具备高性能、易扩展、容错性强等特点。它强化了Apache Lucene的搜索能力,把掌控海量数据索引和查询的方式提升到一个新的层次。
本文结合开源社区和阿里云平台的实践经验,探讨如何调优Elasticsearch的性能提高索引和查询吞吐量。
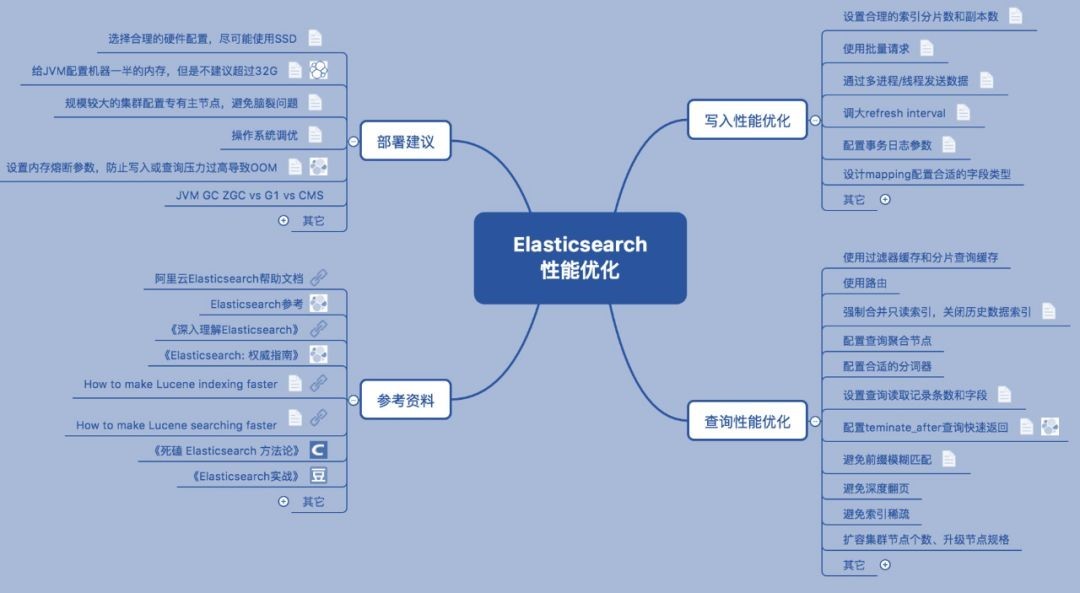
Elasticsearch部署建议
01、选择合理的硬件配置,尽可能使用SSD
Elasticsearch最大的瓶颈往往是磁盘读写性能,尤其是随机读取性能。使用SSD(PCI-E接口SSD卡/SATA接口SSD盘)通常比机械硬盘(SATA盘/SAS盘)查询速度快5~10倍,写入性能提升不明显。
对于文档检索类查询性能要求较高的场景,建议考虑SSD作为存储,同时按照1:10的比例配置内存和硬盘。对于日志分析类查询并发要求较低的场景,可以考虑采用机械硬盘作为存储,同时按照1:50的比例配置内存和硬盘。单节点存储数据建议在2TB以内,不要超过5TB,避免查询速度慢、系统不稳定。
在单机存储1TB数据场景下,SATA盘和SSD盘的全文检索性能对比
(测试环境:Elasticsearch5.5.3,10亿条人口户籍登记信息,单机16核CPU、64GB内存,12块6TB SATA盘,2块1.5 TB SSD盘)
| 磁盘类型 | 并发数 | QPS | 平均检索响应时间 | 50%请求响应时间 | 90%请求响应时间 | IOPS |
|---|---|---|---|---|---|---|
| SATA盘 | 10并发 | 17 | 563ms | 478ms | 994ms | 1200 |
| SATA盘 | 50并发 | 64 | 773ms | 711ms | 1155ms | 1800 |
| SATA盘 | 100并发 | 110 | 902ms | 841ms | 1225ms | 2040 |
| SATA盘 | 200并发 | 84 | 2369ms | 2335ms | 2909ms | 2400 |
| SSD盘 | 10并发 | 94 | 105ms | 90ms | 200ms | 25400 |
| SSD盘 | 50并发 | 144 | 346ms | 341ms | 411ms | 66000 |
| SSD盘 | 100并发 | 152 | 654ms | 689ms | 791ms | 60000 |
| SSD盘 | 200并发 | 210 | 950ms | 1179ms | 1369ms | 60000 |
02、给JVM配置机器一半的内存,但是不建议超过32G
修改conf/jvm.options配置,-Xms和-Xmx设置为相同的值,推荐设置为机器内存的一半左右,剩余一半留给操作系统缓存使用。jvm内存建议不要低于2G,否则有可能因为内存不足导致ES无法正常启动或内存溢出,jvm建议不要超过32G,否则jvm会禁用内存对象指针压缩技术,造成内存浪费。机器内存大于64G内存时,推荐配置-Xms30g -Xmx30g 。JVM堆内存较大时,内存垃圾回收暂停时间比较长,建议配置ZGC或G1垃圾回收算法。
03、规模较大的集群配置专有主节点,避免脑裂问题
Elasticsearch主节点(master节点)负责集群元信息管理、index的增删操作、节点的加入剔除,定期将最新的集群状态广播至各个节点。在集群规模较大时,建议配置专有主节点只负责集群管理,不存储数据,不承担数据读写压力。
专有主节点配置(conf/elasticsearch.yml):
node.master:true
node.data: false
node.ingest:false数据节点配置(conf/elasticsearch.yml):
node.master:false
node.data:true
node.ingest:trueElasticsearch默认每个节点既是候选主节点,又是数据节点。最小主节点数量参数minimum_master_nodes推荐配置为候选主节点数量一半以上,该配置告诉Elasticsearch当没有足够的master候选节点的时候,不进行master节点选举,等master节点足够了才进行选举。
例如对于3节点集群,最小主节点数量从默认值1改为2。
最小主节点数量配置(conf/elasticsearch.yml):
discovery.zen.minimum_master_nodes: 204、Linux操作系统调优
关闭交换分区,防止内存置换降低性能。
将/etc/fstab 文件中包含swap的行注释掉
sed -i '/swap/s/^/#/' /etc/fstab
swapoff -a单用户可以打开的最大文件数量,可以设置为官方推荐的65536或更大些
echo "* - nofile 655360" >> /etc/security/limits.conf单用户线程数调大
echo "* - nproc 131072" >> /etc/security/limits.conf单进程可以使用的最大map内存区域数量
echo "vm.max_map_count = 655360" >> /etc/sysctl.conf参数修改立即生效
sysctl -p索引性能调优建议
01、设置合理的索引分片数和副本数
索引分片数建议设置为集群节点的整数倍,初始数据导入时副本数设置为0,生产环境副本数建议设置为1(设置1个副本,集群任意1个节点宕机数据不会丢失;设置更多副本会占用更多存储空间,操作系统缓存命中率会下降,检索性能不一定提升)。单节点索引分片数建议不要超过3个,每个索引分片推荐10-40GB大小。索引分片数设置后不可以修改,副本数设置后可以修改。
Elasticsearch6.X及之前的版本默认索引分片数为5、副本数为1,从Elasticsearch7.0开始调整为默认索引分片数为1、副本数为1。
不同分片数对写入性能的影响
(测试环境:7节点Elasticsearch6.3集群,写入30G新闻数据,单节点56核CPU、380G内存、3TB SSD卡,0副本,20线程写入,每批次提交10M左右数据。)
| 集群索引分片数 | 单节点索引分片数 | 写入耗时 |
|---|---|---|
| 2 | 0/1 | 600s |
| 7 | 1 | 327s |
| 14 | 2 | 258s |
| 21 | 3 | 211s |
| 28 | 4 | 211s |
| 56 | 8 | 214s |
索引设置
curl -XPUT http://localhost:9200/fulltext001?pretty -H 'Content-Type: application/json' -d '
{
"settings" : {
"refresh_interval": "30s",
"merge.policy.max_merged_segment": "1000mb",
"translog.durability": "async",
"translog.flush_threshold_size": "2gb",
"translog.sync_interval": "100s",
"index" : {
"number_of_shards" : "21",
"number_of_replicas" : "0"
}
}
}
'mapping设置
curl -XPOST http://localhost:9200/fulltext001/doc/_mapping?pretty -H 'Content-Type: application/json' -d '
{
"doc" : {
"_all" : {
"enabled" : false
},
"properties" : {
"content" : {
"type" : "text",
"analyzer":"ik_max_word"
},
"id" : {
"type" : "keyword"
}
}
}
}
'写入数据示例
curl -XPUT 'http://localhost:9200/fulltext001/doc/1?pretty' -H 'Content-Type: application/json' -d '
{
"id": "https://www.huxiu.com/article/215169.html",
"content": "“娃娃机,迷你KTV,VR体验馆,堪称商场三大标配‘神器’。”一家地处商业中心的大型综合体负责人告诉懂懂笔记,在过去的这几个月里,几乎所有的综合体都“标配”了这三种“设备”…"
}'修改副本数示例
curl -XPUT "http://localhost:9200/fulltext001/_settings" -H 'Content-Type: application/json' -d'
{
"number_of_replicas": 1
}'02、使用批量请求
使用批量请求将产生比单文档索引请求好得多的性能。写入数据时调用批量提交接口,推荐每批量提交5~15MB数据。例如单条记录1KB大小,每批次提交10000条左右记录写入性能较优;单条记录5KB大小,每批次提交2000条左右记录写入性能较优。
批量请求接口API
curl -XPOST "http://localhost:9200/_bulk" -H 'Content-Type: application/json' -d'
{ "index" : { "_index" : "test", "_type" : "_doc", "_id" : "1" } }
{ "field1" : "value1" }
{ "delete" : { "_index" : "test", "_type" : "_doc", "_id" : "2" } }
{ "create" : { "_index" : "test", "_type" : "_doc", "_id" : "3" } }
{ "field1" : "value3" }
{ "update" : {"_id" : "1", "_type" : "_doc", "_index" : "test"} }
{ "doc" : {"field2" : "value2"} }
'03、通过多进程/线程发送数据
单线程批量写入数据往往不能充分利用服务器CPU资源,可以尝试调整写入线程数或者在多个客户端上同时向Elasticsearch服务器提交写入请求。与批量调整大小请求类似,只有测试才能确定最佳的worker数量。可以通过逐渐增加工作任务数量来测试,直到集群上的I / O或CPU饱和。
04、调大refresh interval
在 Elasticsearch 中,写入和打开一个新段的轻量的过程叫做 refresh 。 默认情况下每个分片会每秒自动刷新一次。这就是为什么我们说 Elasticsearch 是 近 实时搜索: 文档的变化并不是立即对搜索可见,但会在一秒之内变为可见。
并不是所有的情况都需要每秒刷新。可能你正在使用 Elasticsearch 索引大量的日志文件,你可能想优化索引速度而不是近实时搜索,可以通过设置 refresh_interval,降低每个索引的刷新频率。
设置refresh interval API
curl -XPUT "http://localhost:9200/index" -H 'Content-Type: application/json' -d'
{
"settings" : {
"refresh_interval": "30s"
}
}'refresh_interval 可以在既存索引上进行动态更新。
在生产环境中,当你正在建立一个大的新索引时,可以先关闭自动刷新,待开始使用该索引时,再把它们调回来
curl -XPUT "http://localhost:9200/index/_settings" -H 'Content-Type: application/json' -d'
{ "refresh_interval": -1 }'
curl -XPUT "http://localhost:9200/index/_settings" -H 'Content-Type: application/json' -d'
{ "refresh_interval": "1s" }'05、配置事务日志参数
事务日志translog用于防止节点失败时的数据丢失。它的设计目的是帮助shard恢复操作,否则数据可能会从内存flush到磁盘时发生意外而丢失。事务日志translog的落盘(fsync)是ES在后台自动执行的,默认每5秒钟提交到磁盘上,或者当translog文件大小大于512MB提交,或者在每个成功的索引、删除、更新或批量请求时提交。
索引创建时,可以调整默认日志刷新间隔5秒,例如改为60秒,index.translog.sync_interval: “60s”。创建索引后,可以动态调整translog参数,”index.translog.durability”:”async”相当于关闭了index、bulk等操作的同步flush translog操作,仅使用默认的定时刷新、文件大小阈值刷新的机制。
动态设置translog API
curl -XPUT "http://localhost:9200/index" -H 'Content-Type: application/json' -d'
{
"settings" : {
"index.translog.durability": "async",
"translog.flush_threshold_size": "2gb"
}
}'06、设计mapping配置合适的字段类型
Elasticsearch在写入文档时,如果请求中指定的索引名不存在,会自动创建新索引,并根据文档内容猜测可能的字段类型。但这往往不是最高效的,我们可以根据应用场景来设计合理的字段类型。
例如写入一条记录
curl -XPUT "http://localhost:9200/twitter/doc/1?pretty" -H 'Content-Type: application/json' -d'
{
"user": "kimchy",
"post_date": "2009-11-15T13:12:00",
"message": "Trying out Elasticsearch, so far so good?"
}'查询Elasticsearch自动创建的索引mapping,会发现将post_date字段自动识别为date类型,但是message和user字段被设置为text、keyword冗余字段,造成写入速度降低、占用更多磁盘空间。
{
"twitter": {
"mappings": {
"doc": {
"properties": {
"message": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"post_date": {
"type": "date"
},
"user": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
},
"settings": {
"index": {
"number_of_shards": "5",
"number_of_replicas": "1",
}
}
}
}根据业务场景设计索引配置合理的分片数、副本数,设置字段类型、分词器。如果不需要合并全部字段,禁用_all字段,通过copy_to来合并字段。
curl -XPUT "http://localhost:9200/twitter?pretty" -H 'Content-Type: application/json' -d'
{
"settings" : {
"index" : {
"number_of_shards" : "20",
"number_of_replicas" : "0"
}
}
}'
curl -XPOST "http://localhost:9200/twitter/doc/_mapping?pretty" -H 'Content-Type: application/json' -d'
{
"doc" : {
"_all" : {
"enabled" : false
},
"properties" : {
"user" : {
"type" : "keyword"
},
"post_date" : {
"type" : "date"
},
"message" : {
"type" : "text",
"analyzer" : "cjk"
}
}
}
}'参考文档:
- 阿里云Elasticsearch帮助文档
- Elasticsearch参考
- 《深入理解Elasticsearch》
- 《Elasticsearch: 权威指南》
- How to make Lucene searching faster
- How to make Lucene indexing faster
- 《死磕 Elasticsearch 方法论》
- 《Elasticsearch实战》
作者:欧阳楚才 阿里云 Elasticsearch 团队 技术专家
来源:Elasticsearch 技术
原文链接:mp.weixin.qq.com/s?__biz=MzIxMjY4M...






 关于 LearnKu
关于 LearnKu




推荐文章: