
[转载] DB 与 Elasticsearch 混合之应用系统场景分析探讨
作者介绍
李猛,Elastic Stack深度用户,通过Elastic工程师认证,2012年接触Elasticsearch,对Elastic Stack技术栈开发、架构、运维等方面有深入体验,实践过多种大中型项目;为企业提供Elastic Stack咨询培训以及调优实施;多年实战经验,爱捣腾各种技术产品,擅长大数据,机器学习,系统架构。
名词解释
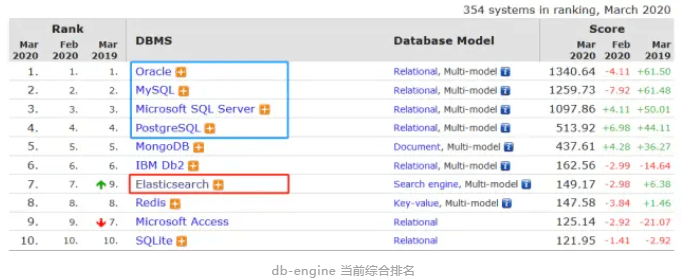
DB:database,泛指关系型数据库,具有严格事务隔离机制的数据类库产品,如 mysql、sqlserver、postgresql、oracle、db2 等,db-engine 综合排名前面的全部是关系型数据库;
ES:Elasticsearch,最好的开源搜索引擎产品,NoSQL 非关系型数据库,不具备严格事务隔离机制,当前 db-engine 综合排名第七;
应用:本文泛指业务应用系统,是 OLTP 场景,非 OLAP 场景,大量运用事务型数据库产品的业务系统;
索引:在关系型数据库中是指数据检索的算法,在 Elasticsearch 是指数据存储的虚拟空间概念,类同数据库中的表。
背景需求
• 为什么单一 DB 不能满足应用系统?
• 为什么单一 ES 不能满足应用系统?
• 为什么要使用 DB 结合 ES 混用的模式?
而不是结合其它 NoSQL?比如 MongoDB?下面从技术层面与业务层面分析探讨。
技术层面

DB 局限性
关系型数据库索引基于最左优先原则,索引要按照查询需求顺序提前创建,不具备任意字段组合索引能力比如 某 xxx 表有 30 个字段,若要求依据任意字段组合条件查询,此时关系型数据库显然无法满足这种灵活需求,包括当下很受欢迎的 NoSQL 明星产品 Mongodb 也不能满足。
关系型数据库支持有限度的关联查询,一般在业务应用系统中,关联表会控制在 2~3 个表(个人观点:有 3 个表关联的业务场景需要由技术架构师评估是否容许,开发工程师只容许 2 个表关联),且单表的数据量是要平衡考虑才可以,跨同构数据库源关联就更加不容许。
那跨异构数据库源呢?不是不容许,实在是有心无力。关系型数据库普遍采用 B+ 树数据结构实现索引查询,面对超大数据量处理有天然的瓶颈,数据量超过百万千万级,复杂点的查询,性能下降很快,甚至无法运行。
关系型数据库虽然也支持主从同步,支持读写分离,但集群是一种松散式的架构,集群节点感知能力脆弱,不成体系,弹性扩展能力不行。
ES 互补性
Elasticsearch 基于 Lucene 核心库构建,以倒排索引算法为基础,集成多种高效算法。Elasticsearch 默认为所有字段创建索引,任索引字段可组合使用,且查询效率相当高,相比关系型数据库索更加高效灵活。在业务系统中,有很多场景都需要这种任意字段组合查询的能力,简称通用搜索。
Elasticsearch 的数据模型采用的是 Free Scheme 模式,以 JSON 主体,数据字段可以灵活添加,字段层级位置也可以灵活设置 ,关系数据库中需要多表关联查询,在 Elasticsearch 中可以通过反范式的关联能力,将多个业务表数据合并到一个索引中,采用对象嵌套的方式。
Elasticsearch 天然分布式设计,副本与分片机制使得集群具备弹性扩展能力,可以应付超大的数据量查询,在单索引数据量十亿级也可以在亚秒内响应查询。
Elasticsearch 的索引支持弹性搜索,可以指定一个索引搜索,也可以指定多个索引搜索,搜索结果由 ES 提供过滤合并,这就为业务系统提供了很灵活的操作空间,特别是在实时数据与历史数据方面,统一查询条件语法皆可执行。
Elasticsearch 支持数据字段与索引字段分离,默认情况下,数据字段与索引字段是同时启用,实际在业务业务场景中,数据表中很多字段无需检索,只是为了存储数据,在查询时方便取回;很多检索字段也无需存储原始数据,只是检索过滤使用。
DB 不等于 ES
关系数据库定位全能型产品,强事务机制,数据写入性能一般,数据查询能力一般。Elasticsearch 定位查询分析型产品,弱事务机制,查询性能非常不错。DB 与 ES 各有优势劣势,不能等同取代。
业务层面

业务领域复杂度
在进入互联网/移动互联网/物联网之后,业务系统数据量的几何倍数增长,传统应当策略当然是采用分库分表机制,包括物理层面分库分表,逻辑层面分区等。非重要数据可以采用非关系型数据库存储,重要的业务数据一定是采用关系数据库存储,比如物流速运行业的客户订单数据,不容许有丢失出错。
面对复杂业务系统需求,当下最流行的解决方式是采用微服务架构模式,微服务不仅仅局限上层应用服务,更深层次的是底层数据服务(微服务不在本次讨论之内),基于领域模型思维拆分分解。应用服务拆分成大大小小数个,可以几十个几百个,也可以更多,数据服务也拆分成大大小小数个。
业务查询复杂度
分库分表解决了数据的存储问题,但需要做合并查询却是个很麻烦的事,业务系统的查询条件一般是动态的,无法固定,更加不可能在分库分表时按照所有动态条件设计,这似乎代价太大。一般会选择更强大的查询数据库,比如 Elasticsearch 就非常合适。
微服务架构模式解决了业务系统的单一耦合问题,但业务系统的查询复杂度确实提高不少,复杂点的应用服务执行一次查询,需要融合多个领域数据服务才能完成,特别是核心领域数据服务,几乎贯穿一个系统所有方面,比如物流速运行业订单领域。
DB 与 ES 结合
业务数据存储由关系型数据库负责,有强事务隔离机制,保障数据不丢失、不串乱、不覆盖,实时可靠。
业务数据查询由 Elasticsearch 负责,分库分表的数据合并同步到 ES 索引;跨领域库表数据合并到同步 ES 索引,这样就可以高效查询。
DB 与 ES 结合问题
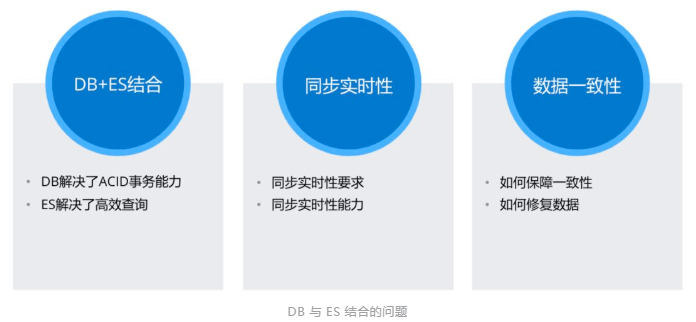
关于DB与Elasticsearch混合主要有以下两个问题:同步实时性、数据一致性,本文不探讨此问题,后续会有专题讲述如何解决。
混合场景
前面已经论证了关系型数据库与 Elasticsearch 混合使用的必要性,接下来是探讨混合场景下的业务场景数据模型映射。
单数据表 ->单索引
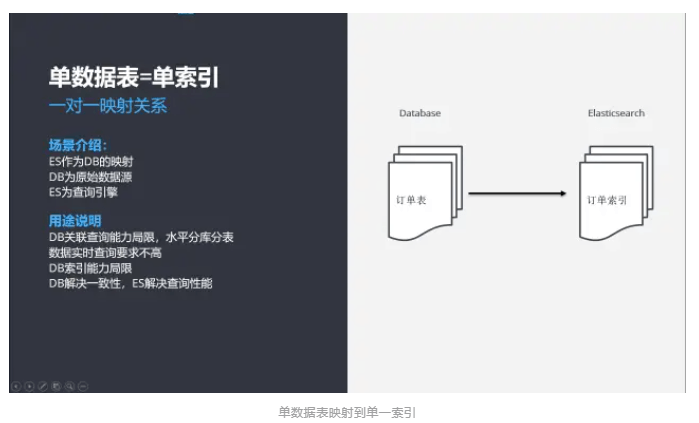
1)一对一映射关系,关系数据库有多少个表,Elasticsearch 就有多少个索引;
2)关系数据库提供原始数据源,Elasticsearch 替代数据库成为查询引擎,替代列表查询场景;
3)单数据表为水平分库分表设计,需要借助Elasticsearch 合并查询,如图:电商行业订单场景,日均订单量超过百万千万级,后端业务系统有需求合并查询;
4)单数据表业务查询组合条件多,数据库索引查询能力局限,需要借助 Elasticsearch 全字段索引查询能力,主要替代列表查询场景。如:电商行业商品搜索场景,商品基础字段超过几十个,几乎全部都可以组合搜索。
单数据表 ->多索引
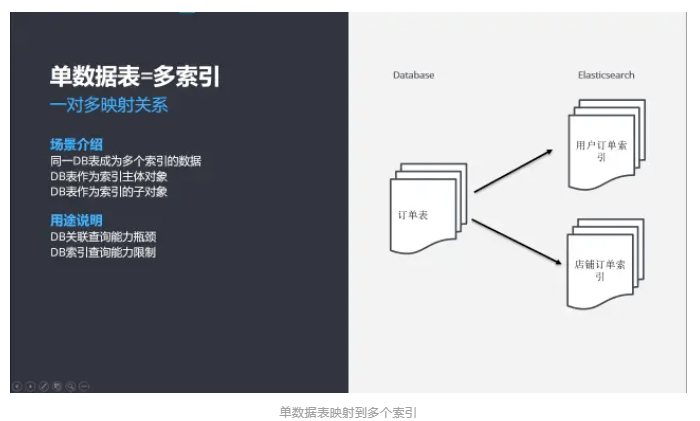
1)一对多映射关系,单数据表映射到多个索引中;
2)单数据表即作为 A索引的主体对象,一对一映射;
3)单数据表也作为 B索引的子对象,嵌入到主体对象下面;
4)基于微服务架构设计,在业务系统中,业务系统划分多个子领域,子领域也可以继续细分,如电商行业,订单领域与商品领域,订单表需要映射到订单索引,也需要与商品索引映射。
多数据表 ->多索引
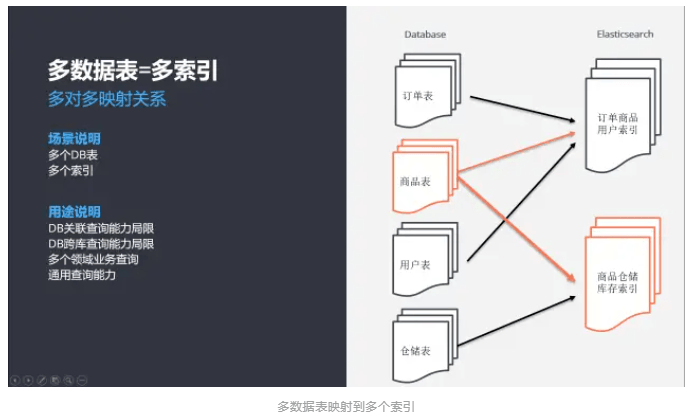
1)多对多映射关系,多个数据表映射到多个索引,复杂度高;
2)一个中型以上的业务系统,会划分成多个领域,单领域会持续细分为多个子领域,领域之间会形成网状关系,业务数据相互关联;
3)数据库表关联查询效率低,跨库查询能力局限,需要借助 Elasticsearch 合并;
4)按照领域需求不同,合并为不同的索引文件,各索引应用会有差异,部分是通用型的,面向多个领域公用;部分是特殊型的,面向单个领域专用。
多源数据表 ->多索引
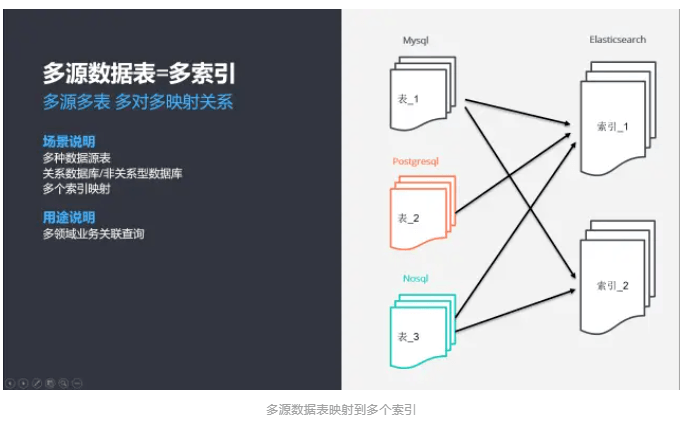
1)多源多表,多对多映射关系,数据表与索引之间的映射关系是交叉型的,复杂度最高;
2)一个大中型业务系统,不同的业务场景会采用不同的数据存储系统;
3)关系型数据库多样化,如 A 项目采用 MySQL,B 项目采用 PostgreSQL,C 项目选用 SQLServer,业务系统通用型的查询几乎不能实现;
4)非关系型数据库多样化,如 A 项目采用键值类型的 Redis,B 项目选用文档型的 MongoDB,业务系统同样也不能实现通用型查询;
5)基于异构数据源通用查询的场景需求,同样需要借助 Elasticsearch 合并数据实现
结语
Elasticsearch 虽然早期定位是搜索引擎类产品,后期定位数据分析类产品,属于 NoSQL 阵营,且不支持严格事务隔离机制,但由于其先进的特性,在应用系统中也是可以大规模使用,能有效弥补了关系型数据库的不足。
本文主旨探讨了 DB 与 ES 混合的需求背景与应用场景,目的不是评选 DB 与 ES 谁更优劣,是要学会掌握 DB 与 ES 平衡,更加灵活的运用到应用系统中去, 满足不同的应用场景需求,解决业务需求问题才是评判的标准。
作者:李猛
来源:云栖社区
原文链接:developer.aliyun.com/article/76276...








 关于 LearnKu
关于 LearnKu




推荐文章: