
[转载] 记录一次 Flink 作业异常的排查过程
最近2周开始接手apache flink全链路监控数据的作业,包括指标统计,业务规则匹配等逻辑,计算结果实时写入elasticsearch. 昨天遇到生产环境有作业无法正常重启的问题,我负责对这个问题进行排查跟进。
第一步,基础排查
首先拿到 jobmanager 和 taskmanager 的日志,我从 taskmanager 日志中很快发现 2 个基础类型的报错,一个是 npe,一个是索引找不到的异常。
elasticsearch sinker 在执行写入数据的前后提供回调接口让作业开发人员对异常或者成功写入进行处理,如果在处理异常过程中有异常抛出,那么框架会让该 task 失败,导致作业重启。
npe 很容易修复,索引找不到是创建索引的服务中的一个小 bug,这些都是小问题。
重点是在日志中我看到另一个错误:
java.lang.OutOfMemoryError: unable to create new native thread
at java.lang.Thread.start0(Native Method)
at java.lang.Thread.start(Unknown Source)
at org.apache.flink.runtime.io.network.api.writer.RecordWriter.<init>(RecordWriter.java:122)
at org.apache.flink.runtime.io.network.api.writer.RecordWriter.createRecordWriter(RecordWriter.java:321)
at org.apache.flink.streaming.runtime.tasks.StreamTask.createRecordWriter(StreamTask.java:1202)
at org.apache.flink.streaming.runtime.tasks.StreamTask.createRecordWriters(StreamTask.java:1170)
at org.apache.flink.streaming.runtime.tasks.StreamTask.<init>(StreamTask.java:212)
at org.apache.flink.streaming.runtime.tasks.StreamTask.<init>(StreamTask.java:190)
at org.apache.flink.streaming.runtime.tasks.OneInputStreamTask.<init>(OneInputStreamTask.java:52)
at sun.reflect.GeneratedConstructorAccessor4.newInstance(Unknown Source)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(Unknown Source)
at java.lang.reflect.Constructor.newInstance(Unknown Source)
at org.apache.flink.runtime.taskmanager.Task.loadAndInstantiateInvokable(Task.java:1405)
at org.apache.flink.runtime.taskmanager.Task.run(Task.java:689)
at java.lang.Thread.run(Unknown Source)这种异常,一般是 nproc 设置太小导致的,或者物理内存耗尽,检查完ulimit 和内存,发现都很正常,这就比较奇怪了。
第二步、分析 jstack 和 jmap
perfma 有一个产品叫 xland,我也是第一次使用,不得不说,确实牛逼,好用!
首先把出问题的 taskmanager 的线程栈信息和内存 dump 出来,具体命令:
jstatck pid > 生成的文件名
jmap -dump:format=b,file=生成的文件名 进程号接着把这两个文件导入 xland,xland 可以直接看到线程总数,可以方便搜索统计线程数、实例个数等等。
最先发现的问题是这个 taskmanager 线程总数竟然有 17000+,这个数字显然有点大,这个时候我想看一下,哪一种类型的线程比较大,xland 可以很方便的搜索,统计,这时候我注意到有一种类型的线程非常多,总数 15520。
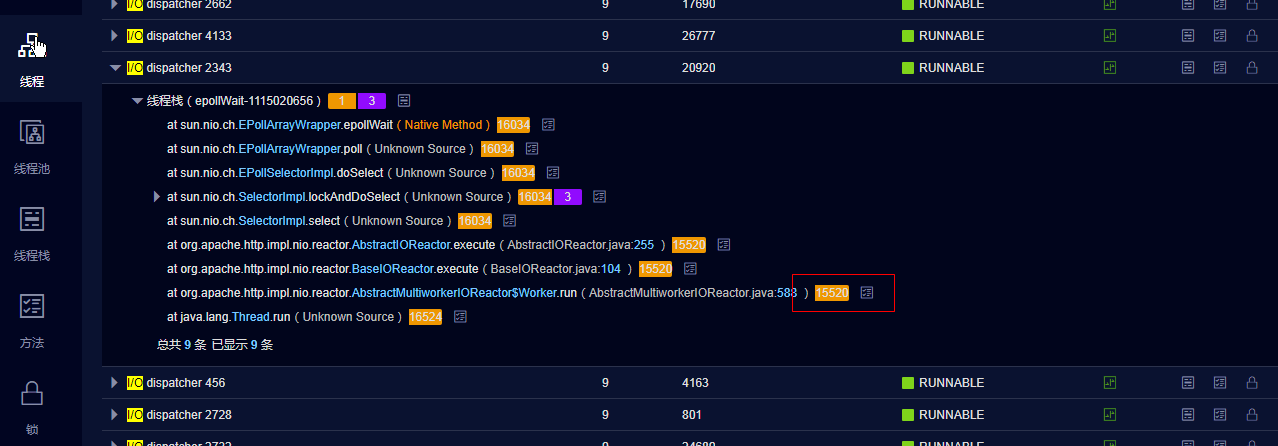
更上层的调用信息看不到了,只看到来自 apache http client,根据作业流程,首先想到的就是 es sinker 的 RestHighLevelClient 用到这个东西。
那么我们在 xland 中统计 RestHighLevelClient 对象个数,发现有几百个,很显然这里有问题。
第三步、定位具体问题
有了前面 xland 的帮助,我们很容易定位到是 esclient 出了问题。
在我们的作业里面有 2 个地方用到了 es client,一个是 es sinker,es sinker 使用的就是 RestHighLevelClient,另一个是我们同学自己写的一个 es client,同样是使用 RestHighLevelClient,在 es sinker 的 ElasticsearchSinkFunction 中单独构造,用于在写入 es 前,先搜索一些东西拿来合并,还做了 cache。
1、怀疑RestHighLevelClient bug
我们通过一个测试,来验证是不是 RestHighLevelClient 的问题
启动一个单纯使用 es sinker 的 job,调整并发度,观察前面出现较多的
I/O dispatcher 线程的个数,最后发现单个 es sinker 也会有 240+ 个
I/O dispatcher 线程,通过调整并发,所有 taskmanager 的
I/O dispatcher 线程总数基本和并发成正向比例。
停掉写 es 作业,此时所有 taskmanager 是不存在 I/O dispatcher 线程的
看起来 I/O dispatcher 那种线程数量大,似乎是“正常的”。
2、杀掉作业,观察线程是否被正常回收
杀掉作业,I/O dispatcher 线程变成 0 了,看起来 es sinker 使用是正常的。
这时候基本上可以判断是我们自己写的 es client 的问题。到底是什么问题呢?
我们再做一个测试进一步确认。
3、启动问题作业,杀死 job 后,观察 I/O dispatcher 线程个数
重启 flink 的所有 taskmanager,给一个“纯净”的环境,发现杀死作业后,还有 I/O dispatcher 线程。
这个测试可以判断是我们的 es client 存在线程泄漏。
四、背后的原理
es sinker 本质上是一个 RichSinkFunction,RichSinkFunction 带了 open 和 close 方法,在 close 方法中,es sinker 正确关闭了 http client。
@Override
public void close() throws Exception {
if (bulkProcessor != null) {
bulkProcessor.close();
bulkProcessor = null;
}
if (client != null) {
client.close();
client = null;
}
callBridge.cleanup();
// make sure any errors from callbacks are rethrown
checkErrorAndRethrow();
}
而我们的 es client 是没有被正确关闭的。
具体原理应该是是这样的,当 es sinker 出现 npe 或者写 es rejected 等异常时,job 会被 flink 重启,es sinker 这种 RichSinkFunction 类型的算子会被 flink 调用 close 关闭释放掉一些资源,而我们写在 ElasticsearchSinkFunction 中 es client,是不会被框架关照到的,而这种写法我们自己也无法预先定义重启后关闭 client 的逻辑。
如果在构造时使用单例,理论上应该是可以避免作业反复重启时 es client不断被构造导致线程泄漏和内存泄漏的,但是编写单例写法有问题,虽然有 double check,但是没加 volatile,同时锁的是 this, 而不是类。
五、小结
1、xland 确实好用,排查问题帮助很大。
2、flink 作业用到的外部客户端不要单独构造,要使用类似 RichFunction这种方式,提供 open ,close 方法,确保让资源能够被 flink 正确释放掉。
3、用到的对象,创建的线程,线程池等等最好都起一个名字,方便使用xland 事后排查问题,如果有经验的话,应该一开始就统计下用于构造es client 的那个包装类对象个数。
作者:a kobe fan
来源:PerfMa 社区
原文链接:club.perfma.com/article/1555905







 关于 LearnKu
关于 LearnKu




推荐文章: