
[转载] 京东 Elasticsearch 使用 ChubaoFS 实现计算存储分离
Elasticsearch 是一个开源的分布式 RElasticsearchTful 搜索引擎,作为一个分布式、可扩展、实时的搜索与数据分析引擎,它可以快速存储、搜索和分析大量数据。同时,Elasticsearch 也支持具有负责搜索功能和要求的应用程序的基础引擎, 因此可以应用在很多不同的场景中。
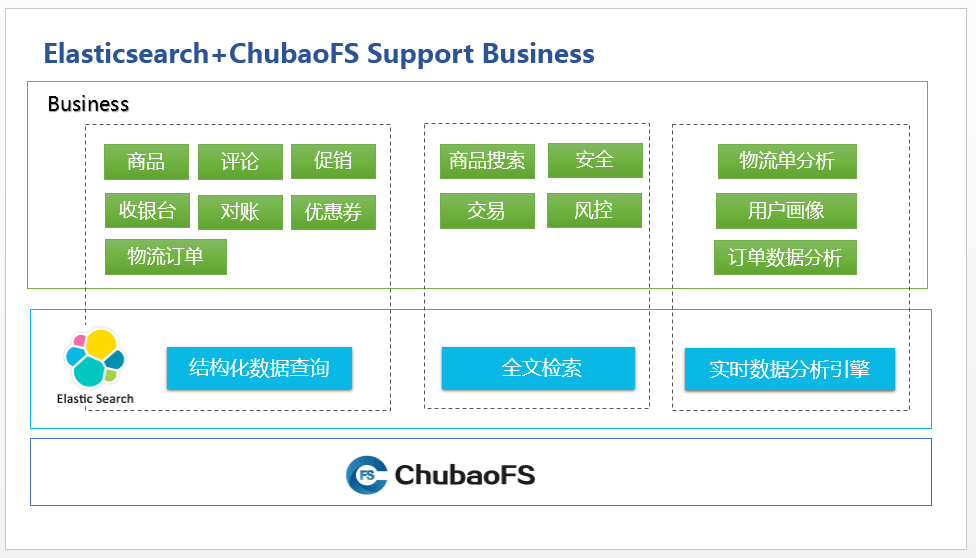
1、Elasticsearch 在京东的使用场景
由于较高的性能和较低的使用门槛,京东内部有很多的场景都在使用 Elasticsearch。
2015 年 6 月,京东着手开发了 Elasticsearch 的托管平台——杰思 (JElasticsearch)。杰思平台主要负责 Elasticsearch 集群的部署、运行监控、数据迁移、权限管理、插件开发、集群升级等日常维护工作。
目前杰思平台管理的集群覆盖了京东多条业务线,同时也覆盖了很多应用场景:
- 补充关系型数据库的结构化数据查询
主要应用的业务是商品、促销、优惠券、订单、收银台、物流、对账、评论等大数据量查询。此场景的核心诉求是高性能、稳定性和高可用性,部分场景会有检索要求,通常用于加速关系型数据库,业务系统通过 binlog 同步或业务双写完成数据同步。
- 全文检索功能
主要的应用场景是应用、安全、风控、交易等操作日志,以及京东部分品类商品搜索。此类日志化场景对写要求很高,查询性能及高可用等要求相对较低,大的业务写会达到数千万 / 秒,存储以 PB 为单位来计算。
这些场景对磁盘、内存有比较高的要求,因此,京东也做了相应优化,用于减少内存消耗,提升磁盘整体使用率,使用更廉价的磁盘来降低成本等等。
- 实时数据分析引擎,形成统计报表
主要应用的业务是物流单的各种分析、订单数据分析、用户画像等。因为业务数据分析纬度较多,flink、storm 等流式分析对于某些报表场景不太适用,批处理实时性又成为问题,所以近实时分析的 Elasticsearch 就成为了这些业务的选择。
在应用 Elasticsearch 的 5 年时间中,京东从最初的几个场景应用变成了覆盖各条业务线,从最初的几台机器变成了现在的上千机器和几千集群的量级,运维压力也随之而来了。目前,京东在日常运维 ELasticsearch 集群时,主要面临以下几个问题:
- IO 读写不均匀,部分节点 IO 压力非常大;
- 冷数据节点存储量受限制于单机的最大存储;
- close 后的索引节点故障无法进行 recovery,导致数据丢失的风险。
为了解决这些问题,京东应用了 ChubaoFS。ChubaoFS 是京东自研的、为云原生应用提供高性能、高可用、可扩展、 稳定性的分布式文件系统,设计初衷是为了京东容器集群提供持久化存储方案,同时也可作为通用云存储供业务方使用,帮助有状态应用实现计算与存储分离。
ChubaoFS 支持多种读写模型,支持多租户,兼容 POSIX 语义和 S3 协议。ChubaoFS 设计的每个 pod 可以共享一个存储卷,或者每个 pod 一个存储卷,当容器所在的物理机宕机后,容器的数据可以随着容器被同时调度到其他宿主机上, 保障数据可靠存储。
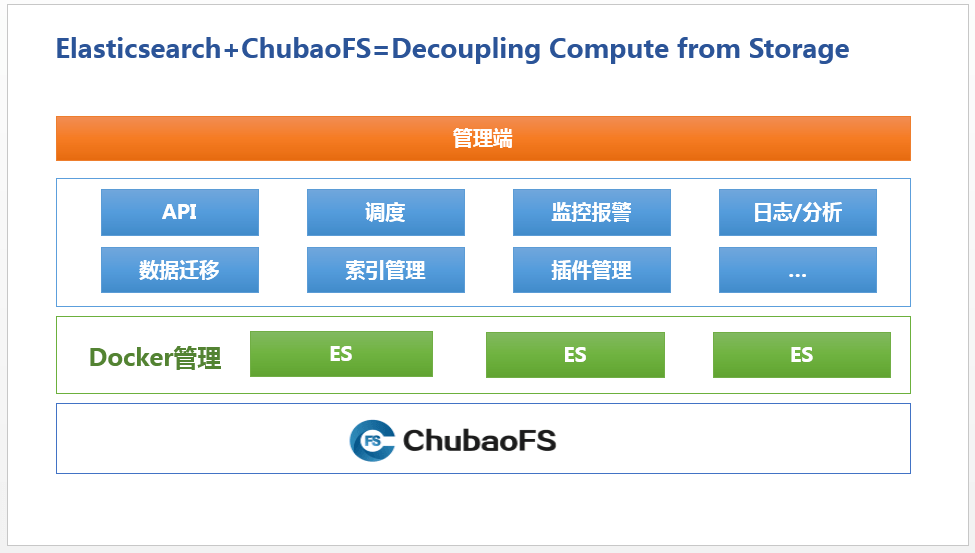
2、Elasticsearch 实例管理演进之路
京东的 Elasticsearch 实例管理也是一个不断摸索、不断爬坑的过程。
初始阶段
最初,京东 Elasticsearch 集群部署是完全没有架构可言的,集群配置也都采用默认配置,一台物理机启动多个 Elasticsearch 进程,进程间完全共享服务器资源,不同业务之间使用集群进行隔离,这种形式使用服务器 CPU 和内存得到了充分利用。
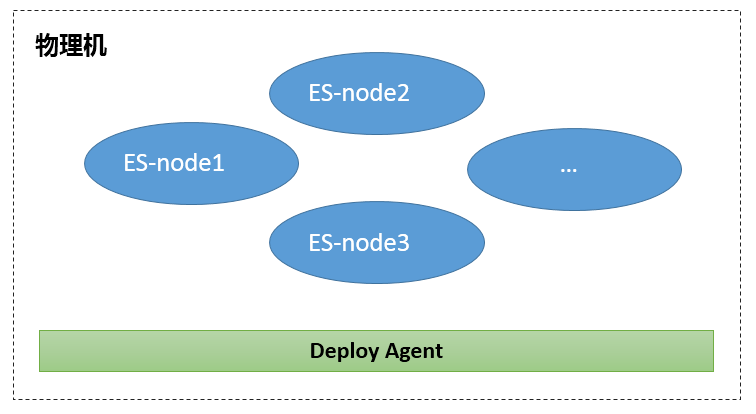
当系统运行了一段时间之后,这种部署方式的弊端开始显现出了。
- 实例容易受到其他节点的影响,重要业务抖动问题没有有效方式避免。
- 物理机内存被 cache 占用,新创建实例启动时耗时特别长。
- 物理机内存被 cache 占用,新创建实例启动时耗时特别长。
容器隔离阶段
由于物理机直接部署 Elasticsearch,无法管理 CPU、内存,各个节点相互影响明显,甚至会影响到稳定性。所以,针对上述情况,京东做出了改善方案——调研资源隔离方式。
当时比较主流的资源隔离方式有两种,Docker 容器化和虚拟机。
2016 年时 Docker 容器化技术已成型,但虚拟技术比较成熟有大量工具、生态系统完善。相对于虚拟机的资源隔离,Docker 不需要实现硬件虚拟化,只是利用 cgroup 对资源进行限制,实际使用的仍然是物理机的资源,所以在资源使用率方面效率更高,我们经过测试使用 Docker 化后性能损失相对较小几乎可以忽略。
2016 年时 Docker 容器化技术已成型,但虚拟技术比较成熟有大量工具、生态系统完善。相对于虚拟机的资源隔离,Docker 不需要实现硬件虚拟化,只是利用 cgroup 对资源进行限制,实际使用的仍然是物理机的资源,所以在资源使用率方面效率更高,我们经过测试使用 Docker 化后性能损失相对较小几乎可以忽略。
而在虚拟机的优势方面,例如安全性,京东采用了内部资源共享平台,通过流程管理或内部其它设施来弥补。这样一来,原本的完全资源隔离优势,反而成为了内部系统资源最大化利用的劣势。
因此,京东选择了当时相对不太成熟的容器化部署方式,并进行了服务器上 Elasticsearcht 资源隔离:
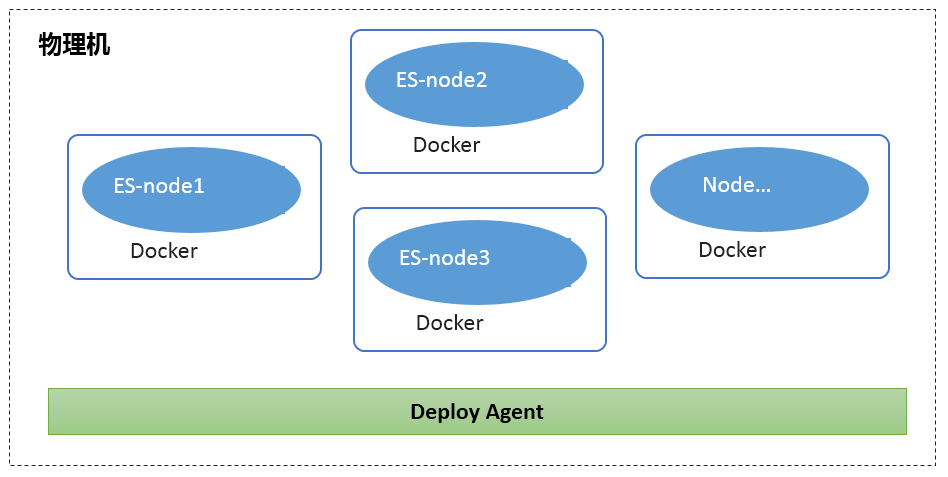
内存完全隔离:
数据 / 主数节点:默认按 jvm50%,预留一半给 Lucene 做 cache 使用。
网关 / 主节点:内存容量 -2 做为 jvm 内存,预留 2G 给监控及其它服务。
CPU 隔离:
重要业务直接绑定 CPU,完全避免资源抢占。
一般业务通过调整 cpu-sharElasticsearch、cpu-period、cpu-quota 进行 CPU 比例分配。
IO 隔离:
由于生产环境机器的多样性,磁盘 IO 本身差别很大,另外对 IO 的限制会造成 Elasticsearch 读写性能严重下降,出于只针对内部业务的考虑,京东并未对 IO 进行隔离。
通过简单的容器隔离,CPU 抢占现象明显改善。内存完全隔离之后,生产环境中节点之间相互影响很少发生 (IO 差的机器会有 IO 争用),部署方式改造产生了应用的收益。
无状态实例阶段
随着业务的不断增长,集群数量及消耗的服务器资源成比例上升,京东 Elasticsearch 实例上升为上万个,维护的集群快速增长为上千个,集群规模从几个到几十个不等。
但是整体资源的利用率却相对较低,磁盘使用率仅为 28% 左右,日常平均读写 IO 在 10~20M/ 秒(日志分区 IO 在 60-100M / 秒)。造成资源浪费的原因是集群规模普遍较小,为保证突发情况下,读写请求对 IO 的要求,我们一般会为集群分配较为富余的资源,物理机分配的容器也会控制在一定量级。
我们做个假设,如果大量的服务器 IO 都可以共享,那么某个集群突发请求对 IO 的影响其实可以忽略的。基于这种假设以及对提高磁盘使用率的迫切需要,我们考虑引入了公司内部部署的 ChubaoFS 作为存储,将 Elasticsearch 作为无状态的实例进行存储计算分离。
得益于 ChubaoFS 是为大规模容器集群挂载而设计的通用文件系统,我们几乎是零成本接入的,只需在物理机上安装相应的客户端,就可以将 ChubaoFS 当成本地文件系统来用。集成之后我们对 ChubaoFS 的性能进行了一系列对比。
我们使用 elasticsearch benchmark 测试工具 Elasticsearchrally 分别对 Elasticsearch 使用本地磁盘和 ChubaoFS 进行 benchmark 测试,测试使用了 7 个 elasticsearch 节点,50 个 shard。
Elasticsearchrally 测试参数如下:
Elasticsearchrally --pipeline=benchmark-only \--track=pmc \
--track-
params="number_of_replicas:${REPLICA_COUNT},number_of_shards:${SHARD_COUNT}" \--target-hosts=${TARGET_HOSTS} \--report-file=${report_file}其中 REPLICA_COUNT 0、1、2 分别 代表不同的副本数;SHARD_COUNT 为 50。
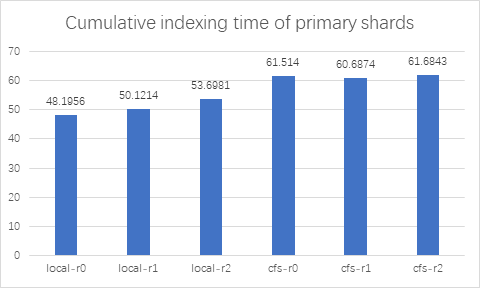
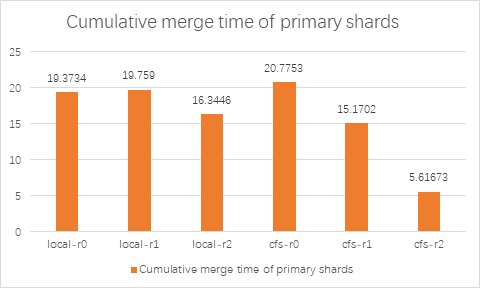
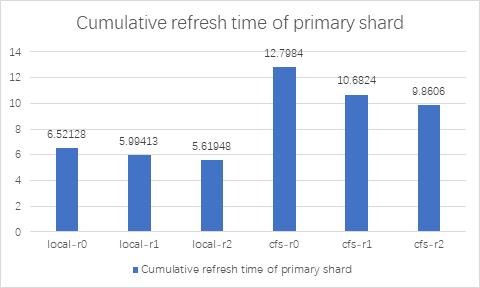
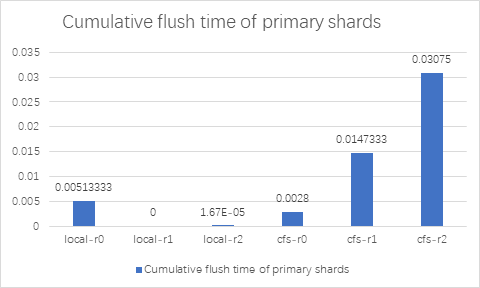
从测试结果可以看出,Elasticsearch 集成 ChubaoFS 之后,在不同副本数情况下, index benchmark 性能和本地磁盘差距在 110%~120% 左右,仅有略微的下降;merge benchmark 性能在 replica > 0 时,Elasticsearch 使用 ChubaoFS 优于本地磁盘。refrElasticsearchh 和 flush benchmark 性能 ChubaoFS 不及本地磁盘。
3、目前使用效果
集成 ChubaoFS 之后,我们先是灰度运行了一段时间,效果表现良好之后,我们将京东日志所有的 Elasticsearch 集群底层全部切换为 ChubaoFS。切换之后,我们在这些方面获得了更好的效果:
节约资源
在采用 ChubaoFS 之前,我们使用了 500 台物理机器,并且每个机器平时大概有 80% 的磁盘 IO 能力处于闲置状态。采用 ChubaoFS 之后,ChubaoFS 的集群规模约为 50 台,Elasticsearch 托管到公司的容器平台,实现弹性可扩展。
管理和运维更加简单便捷
采用 ChubaoFS 之后,我们不用再担心某个机器的硬盘故障,或者某个机器的读写负载不均衡的问题。
GC 频率明显降低
由于 ChubaoFS 底层对文件作了副本支持,业务层 Elasticsearch 将副本置为 0,原先 segment 挤占堆内存导致 FullGC 现象明显,接入 ChubaoFS 后,GC 频率明显降低。
参考资料
ChubaoFS 京东开源云原生应用分布式文件系统
ChubaoFS 网站:
ChubaoFS 设计相关论文,收录在 ACM SIGMOD 2019
CFS: A Distributed File System for Large Scale Container Platforms.
作者:王行行,张丽颖
来源:京东智联云
原文链接:developer.jdcloud.com/article/980








 关于 LearnKu
关于 LearnKu




推荐文章: