
[转载] 深入理解 Lucene 的 flush 过程
这里的 flush 是指 Lucene 中对 flush 的定义,即:将内存中的数据刷到磁盘,生成一个新的 segment 的过程,对应 ES 里的操作是 refresh。
最近在对 es 的测试过程中,esrally 批量写入数据后,发现 segment 数量比较预期要多,segment 的生成涉及到 lucene 内部的一些原理。我们都知道,segment 过多有很多缺点,例如:
对搜索速度有负面影响,对分片的搜索需要遍历所有的 segment,再合并搜索结果
open 索引会很慢,open 索引,或者节点重启,在不考虑副分片的情况下,仅仅 open 这些主分片就很慢,因为加载分片的时候,每个 segment 都要被加载,造成大量随机 io,在 open 过程中,查看磁盘的 util 都是100%,将segment force merge后,open 过程比原来快了 N 倍。
会占用更多的内存,曾经测试1TB 索引,8万 segment 的情况,将segment force merge到4000的后,JVM内存占用由原来的11GB 降低到了6GB 左右。
单个分片支持并发写入
要了解这点我们首先需要知道,在 es 中,一个分片是允许多线程并发写入的。这就是说,如果你的集群只有一个分片,当写入并发和 cpu 核数一样时,一样可以把 CPU 跑满。
从源码上来说的话,每个分片有一个 InternalEngine 对象,多线程并发写入时,访问的是同一个 InternalEngine对象。而InternalEngine中封装了 Lucene 的indexWriter。这是 Lucene 对写入过程的封装,典型的写入过程如下:
// initialization
Directory index = new NIOFSDirectory(Paths.get("/index"));
IndexWriterConfig config = new IndexWriterConfig();
IndexWriter writer = new IndexWriter(index, config);
// create a document
Document doc = new Document();
doc.add(new TextField("url", "www.elasticsearchbook.cn", Field.Store.YES));
// index the document
writer.addDocument(doc);
writer.commit();你可能记得,一个分片的写入过程也会加锁,不过,他只是锁了 uid,uid 就是 _id:
try (Releasable ignored = versionMap.acquireLock(index.uid().bytes());也就是说InternalEngine只对更新操作进行了互斥,新增文档直接多线程调用IndexWriter来写。
既然并行写入时,是由同一个 IndexWriter 对象负责写入,现在我们需要知道 IndexWriter 如何支持了并行写入,以及他产生 segment 的时机都有哪些。
Lucene IndexWriter 对并发写入的支持
当多线程调用 IndexWriter执行写入时,IndexWriter会为每个线程分配一个 DocumentsWriterPerThread对象,简称 DWPT,每个 DWPT内部包括一个 buffer,这个 buffer最终会 flush 为单独的 segment 文件。看到这里,你已经能够想到为什么会产生很多小 segment,这与客户在单个分片上执行的写入并发量有关!如果客户端单并发写一个分片,而DWPT总是选择同一个 buffer 来存放 doc 的话,就不会产生那么多 segment,事实正是如此!
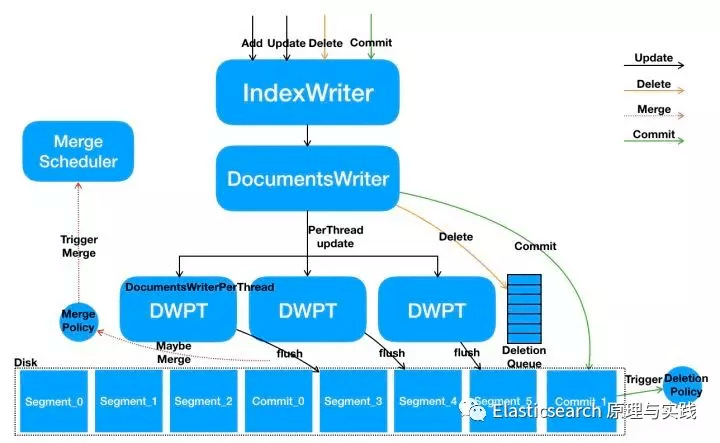
下面我们详细看一下在 Elasticsearch 中,一条 doc 在 lucene 的写入过程
Lucene 从写入到 flush 的过程
当一个 doc 在IndexWriter写入完毕后,其内部会判断是否进行 Flush,在执行 Flush 的过程中,会判断是否执行 Merge。主要过程的代码如下:
//分配 DWPT
final ThreadState perThread = flushControl.obtainAndLock();
将 doc 写入 DWPT 的 buffer
seqNo = dwpt.updateDocument(doc, analyzer, delNode, flushNotifications);
//判断当前 DWPT 是否满足 flush 条件
flushingDWPT = flushControl.doAfterDocument(perThread, isUpdate);
//执行 flush,flush 当前 DWPT,以及队列中等待 flush 的其他 DWPT
postUpdate(flushingDWPT, hasEvents)以新增 doc 为例,一条 doc 的写入过程如下:
分配DWPT
为每个并发分配一个 DWPT,已分配的 DWPT 放入一个LIFO列表中(隶属perThreadPool),先尝试从 LIFO 中分配,没有空闲的就创建新的。由于后进先出的关系,近期使用过的 DWPT 会被优先使用,因此一个分片上有两个写入并发的话,doc 会被写入到两个 DWPT 的 buffer,而不会产生一堆 DWPT。
if (freeList.isEmpty()) {
// ThreadState is already locked before return by this method:
return newThreadState();
} else {
// Important that we are LIFO here! This way if number of concurrent indexing threads was once high, but has now reduced, we only use a
// limited number of thread states:
threadState = freeList.remove(freeList.size()-1);
}将 doc 写入 DWPT 的 buffer
此处过程省略
检查 flush 条件
Lucene 的 flush 条件有以下检查:
doc 数量达到阈值,es 调用 Lucene 的时候没有设置这个阈值,因此为无限
整个IndexWriter所有的DWPT 中 buffer 使用量达到阈值,es 中使用这种方式,阈值根据 indexing buffer 来计算,默认为堆内存的10%,则对IndexWriter中buffer 最大的 DWPT 标记为等待 flush。
当前DWPT 的 buffer 达到 Lucene 内部的 RAMPerThreadHardLimitMB阈值,默认为 1945MB,es 未更改此设置。这个条件一般很难达到
以上是由写入过程自动触发的 flush,其他 flush 时机还包括:
es 的周期性 refresh
es 手工调用 refresh
es 的 flush(6.x 及之前的版本,es 的 flush 会触发 refresh,7.x 及之后不会)
es 的 es syncedFlush
因此,在 es 中,由写入过程触发的 lucene flush只有一种情况,就是判断IndexWriter中DWPT的 buffer 总和是否达到设定值(默认堆内存的10%)。如果达到阈值,则对IndexWriter中buffer 最大的 DWPT 标记为等待 flush。相关代码为:
final long limit = (long) (indexWriterConfig.getRAMBufferSizeMB() * 1024.d * 1024.d);
final long totalRam = control.activeBytes() + control.getDeleteBytesUsed();
if (totalRam >= limit) {
markLargestWriterPending(control, state, totalRam);
}执行 flush
执行 flush 的时候该 DWPT不会加锁,因此不会阻塞正在执行的写入操作。写入操作会使用新的 DWPT。因为在将 DWPT 标记为需要 flush 的时候,已经将该 DWPT 从perThreadPool中 checkout 出来。相关函数为:checkout->tryCheckoutForFlush();当 DWPT 从perThreadPool中 checkout 出来的时候是有锁保护的。
同样,在 es 周期性执行 refresh,或手工触发 refresh 的时候,也不会阻塞bulk写入,es 的refresh最终调用到 lucene 的flushAllThreads()实现,这个 flush 过程会先调用flushControl.markForFullFlush();将所有的 DWPT 标记为flushPending状态(等待 flush),然后将这些 DWPT 添加到fullFlushBuffer和flushQueue两个列表,后面对 DWPT 执行 flush 操作的时候直接从flushQueue列表里取。
回到本文最初的问题,由于写入并发较高,产生较多的 DWPT 对象,es 周期性的 refresh 会将 indexwriter 所有的 DWPT 全部 flush,此时会产生较多的 segment。
总结
本文基于 es7.1版本,对 es 中 lucene 执行 flush 的地方进行了分析,此处的 flush 指 lucene 的 flush,他将内存的数据写入硬盘,但不执行系统的 sync 进行刷盘操作,实际上只是在系统 cache,相当于 es 的 refresh。es 中的 flush概念与 lucene 的并不相同,es 的 flush 对应在 lucene 中的概念为 commit。
单个 es 分片允许并发写入,也可以有比较高的性能,在本例中,由于索引只有2个主分片,而写入过程错误地配置了过多的并发,导致产生了过多的 segment。因此,在 es bulk 写入数据时最好也考虑到总并发量平均到单个分片时有几个并发。
我们也总结了 es 中触发 lucene flush 的时机,并且了解到,lucene flush并不会阻塞写入。原理在各种类似系统都是相同的,在内存 buffer 写入硬盘时,新的bulk 请求写到了新的 buffer,hbase 的 memstore 刷盘时也是同理,对 memstore执行刷盘时,新数据写入新的 memstore。
参考
作者:张超
来源:Elasticsearch 原理与实践
原文链接:mp.weixin.qq.com/s/c4aSwRveyguGqm7...







 关于 LearnKu
关于 LearnKu




推荐文章: