
[转载] 我是如何通过阿里云开放搜索一步步改造 Elasticsearch 搜索引擎的
写这篇文章之前,我先提出一些在实际生产应用中,使用 elasticsearch 搜索引擎遇到的问题,我相信大部分的人也会碰到。
- 如何定制化我们的排序算法,让 TopN 文档的排序更符合实际业务的需要优先展示
- 如何保证前 N 个文档的分页响应时间控制在 200ms 以内
- 如何调优热词搜索缓存策略
这三类问题与大多数实际的搜索场景关系紧密,但却是原生 elasticsearch 版本所缺乏的。
对于初创公司或者开放团队来说,前期使用搜索功能,大部分会选用一些成熟的搜索引擎产品,因为前期的技术成本和时间成本较低。在开放搜索场景下,我们选用的是阿里云的开放搜索服务。以下是引用阿里云开放搜索引擎的官方介绍:
“OpenSearch 基于阿里巴巴自主研发的大规模分布式搜索引擎平台,该平台承载了阿里巴巴全部主要搜索业务,包括淘宝、天猫、一淘、1688、ICBU、神马搜索等业务。OpenSearch 以平台服务化的形式,将专业搜索技术简单化、低门槛化和低成本化,让搜索引擎技术不再成为客户的业务瓶颈,以低成本实现产品搜索功能并快速迭代。”
作为搜索领域的大厂来说,搜索平台化的探索比我们初创公司成熟太多,所以跟着大厂的搜索解决方案来做肯定能让我们少走很多弯路。
刚开始开发业务的时候,我们直接选用了阿里云的开放搜索服务,业务端所做的工作呢,其实大部分都是对接阿里云搜索服务。我们不用在意太多搜索引擎的技术细节就能很快地开发应用了。但随着业务数据量越来越庞大,我们所需要花费的搜索服务成本越来越大,每年花费在阿里云开放搜索服务费用要大好几十万。如果自建搜索服务的话,服务器的租用开销费用才几万块。而且随着数据量的增加,搜索qps 的增多,这个费用会越来越高。
出于成本考虑,我们决定自建 es 服务。那么问题来了:
- 如何平滑切换搜索引擎服务,使得业务端几乎不需要额外的代码改造
- 如何保证搜索引擎性能与开放搜索差异不会差太多
问题一似乎不是太困难,客户端只需要开发一个类似开放搜索的 REST API SDK 即可,请求参数与开放搜索一致,后端开发一个 gateway 转换搜索请求参数,对接搜索引擎就完事了。
问题二呢,想要自建搜索引擎的搜索延迟达到开放搜索的级别是不现实的,毕竟中间有太多的技术沉淀不是我们一下子就能赶上的。这里附上 Opensearch 的架构图

看完图,我们心里清楚就好了,其中每一个组件背后都是人力和时间成本啊。
为了降低搜索服务成本,我们不得已降级到自建es服务,为了不影响现有的业务需求,我们不得已改造 es,使其至少在搜索功能上能与 opensearch 一致。
好了,说了这么多,我们再回到文章开头提出的问题上来。结合问题,我来跟大家说一下,我是如何一步步通过 opensearch 来扩展和改造es搜索引擎的。
问题 1,如何定制化我们的排序算法,让 TopN 文档的排序更符合实际业务的需要优先展示
说这个问题之前我们先来对比一下开放搜索和 es 自带排序功能使用上的对比。
先来看 opensearch 的排序设计,采用的是两轮相关性排序定制。
搜索结果相关性排序是影响用户体验最关键的一环,OpenSearch 支持开发者定制两轮相关性排序规则来准确控制搜索结果的排序。第一轮为粗排,从命中的文档集合里海选出相关文档。第二轮为精排,对粗排的结果做更精细筛选,支持任意复杂的表达式和语法。方便开发者能更准确控制排序效果,优化系统性能,提高搜索响应速度。
原理
Opensearch 相关性算分策略为,取召回的 rank_size(目前是100万)个文档按照粗排表达式的定义进行算分;取粗排分最高的 N 个结果(百级别)按照精排表达式进行算分,并排序;然后根据 start 与 hit 的设置取相应结果返回给用户。如果用户获取的结果超过了精排结果数 N,则后续按照粗排分数排序结果继续展现。
- 粗排表达式:从上面原理介绍中可以看出粗排对性能(latency)的影响非常大,但同时粗排又非常的重要,否则会出现好的文档无法进入精排而导致文档不能被最终展现。所以粗排要尽量的简单有效,目前 opensearch 的粗排只支持几个简单的正排字段、静态 bm25、时效分等因素。
- 精排表达式:通过粗排表达式筛选出较优质的 N 个文档进行详细排序,精排表达式中支持复杂的数学计算、逻辑等,并且 opensearch 提供了丰富的典型场景(如 O2O 类)的 function 和 feature 来满足日常的相关性需求。

简而言之,就是说,第一轮排序是从返回结果集中取出前 100 万个算分高的文档,第二轮排序是取这 100 万个文档中前 N(经测试 N 值设为 1000,系统超时少)个文档来算分并排序,使得前 N 个文档的展现更符合用户的搜索意愿。
明白了以上的排序规则后,我们怎么通过es来达到这项功能要求呢?先来看看es官方文档找线索,rescore
POST /_search
{
"query" : {
"match" : {
"message" : {
"operator" : "or",
"query" : "the quick brown"
}
}
},
"rescore" : [ {
"window_size" : 100,
"query" : {
"rescore_query" : {
"match_phrase" : {
"message" : {
"query" : "the quick brown",
"slop" : 2
}
}
},
"query_weight" : 0.7,
"rescore_query_weight" : 1.2
}
}, {
"window_size" : 10,
"query" : {
"score_mode": "multiply",
"rescore_query" : {
"function_score" : {
"script_score": {
"script": {
"source": "Math.log10(doc.likes.value + 2)"
}
}
}
}
}
} ]
}官方提供的 rescore 功能似乎可以实现这一功能,但仔细研究发现一个问题,自定义排序函数怎么实现呢,直接写在 script_score 子句中不太现实吧。所以直接用 script_score 不符合实际需求,自定义的排序函数难以扩展和维护。怎么办呢?可能你会想到 es 的 plugin,我们可以自己写一个rescore-plugin的插件来维护。
我们回过头来看看阿里云的实现方案,不难发现,他们自己实现了一套排序语句解析语法,大家可以自行体会一下这种语法与 lucene expression, painless scripting 的区别。
既然我们知道了 opensearch 的解决方案,那么该如何来开发 rescore-plugin 呢?
提到语法解析器,那我们不得不说到 antlr4,我们也可以从 elastic 官网上的招聘信息中看到一些端倪。


可以推测的是,elastic团队也在开始着手es的搜索语法改造工作了。
明白了其中的要领,我们就可以仿照opensearch来设计我们的语法解析器了。附上个人的 antlr4 脚本:
grammar Calculator;
parse
: expression
| EOF
;
expression
: '-' expression # UMINUS
| expression mulop expression # MULOPGRP
| expression addop expression # ADDOPGRP
| expression cmpop expression # CMPOPGRP
| '(' expression ')' # PARENGRP
| NUMBER # DOUBLE
| ID # FIELDNAME
| if_stat # IFSTAT
| in_stat # INSTAT
| text_relevance # TextRelevance
| fieldterm_proximity # FieldtermProximity
;
addop
: '+'
| '-'
;
mulop
: '*'
| '/'
| '%'
;
cmpop
: '=='
| '!='
| '>'
| '<'
| '>='
| '<='
;
in_stat
: ID ('in' '(' NUMBER (',' NUMBER)+ ')')?
;
if_stat
: 'if(' expression ',' NUMBER ',' NUMBER ')'
;
text_relevance
: 'text_relevance(' ID ')'
;
fieldterm_proximity
: 'fieldterm_proximity(' ID ')'
;
NUMBER : ('-')? ( [0-9]* '.' )? [0-9]+;
ID : [a-zA-Z_] [a-zA-Z0-9_]*;
WS : [ \r\n\t] + -> skip ;再结合官方的 rescore-plugin-example 我们就可以开发出属于自己的 rescore 插件了,本人实现的插件目前暂不开源,有兴趣的朋友可以私信哦。
在具体的文本相关度排序函数的实现过程当中,我们肯定会面临的技术细节有:
如何获取每个字段的分词结果
如何计算搜索关键词与文本字段的相关度分值
对于第一个问题,我们其实比较容易实现,只需在建索引的时候,将目标字段的 term_vector 属性设置为 with_positions_offsets, 代码中调用 getTermVectors 函数即可获取,
完成这一步后,我们再结合阿里云官方给出的文本相关度介绍文档,反推其算法实现。

最难实现的为此 text_relavance 函数,由于阿里云官方不开源,我们只能从字面上下手,
经过摸索发现,从其主要衡量角度来分析其内部实现的关键因素,我们再到其官网的搜索测试功能上探索。首先,配置一个精排表达式,精排表达式包含了与计算文本相关度可能有关的算分特征函数,例如:field_match_radio, query_min_slide_window, fieldterm_proximity 等,搜索测试界面可以指定该排序表达式,查看排序分的计算过程,通过 python 将所有的样本数据解析,绘制成曲线图如下:
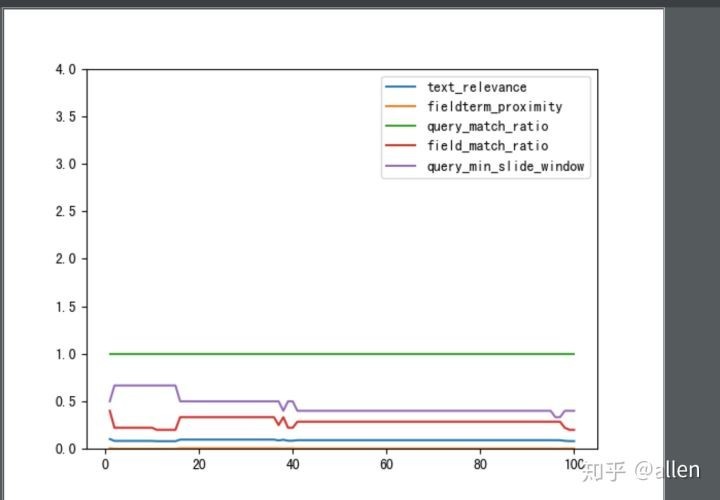
我们可以推测出, text_relevance 近似可以表示成其他函数结果的多元线性回归
text_relevance ~= k*fieldterm_proximity+
x*query_match_radio+
y*query_min_slide_window+z我们按照此思路,搜集多一点的样本数据,再使用 python sklearn 来计算各个系数。
说了这么多,我们到目前为止,已经解决了搜索的重头戏了。后面的两个问题,都是一些 es 源代码细节的摸索了。
下面我们来讲诉一下,关于 es query 的优化。来看一下文章开头提到的两个问题
问题2,如何保证前 N 个文档的分页响应时间控制在 200ms 以内
问题3,如何调优热词搜索缓存策略
我们先来说一下问题3,这其实是 es 的缓存策略的调优。也许大家在网上也看到过很多关于搜索优化的处理,但大部分都是在说一些配置参数的优化,很少有提到 es 的内核代码问题,先附上一段 es 源码:
/**
* Cache something calculated at the shard level.
* @param shard the shard this item is part of
* @param reader a reader for this shard. Used to invalidate the cache when there are changes.
* @param cacheKey key for the thing being cached within this shard
* @param loader loads the data into the cache if needed
* @return the contents of the cache or the result of calling the loader
*/
private BytesReference cacheShardLevelResult(IndexShard shard, DirectoryReader reader, BytesReference cacheKey,
Supplier<String> cacheKeyRenderer, Consumer<StreamOutput> loader) throws Exception {
IndexShardCacheEntity cacheEntity = new IndexShardCacheEntity(shard);
Supplier<BytesReference> supplier = () -> {
/* BytesStreamOutput allows to pass the expected size but by default uses
* BigArrays.PAGE_SIZE_IN_BYTES which is 16k. A common cached result ie.
* a date histogram with 3 buckets is ~100byte so 16k might be very wasteful
* since we don't shrink to the actual size once we are done serializing.
* By passing 512 as the expected size we will resize the byte array in the stream
* slowly until we hit the page size and don't waste too much memory for small query
* results.*/
final int expectedSizeInBytes = 512;
try (BytesStreamOutput out = new BytesStreamOutput(expectedSizeInBytes)) {
loader.accept(out);
// for now, keep the paged data structure, which might have unused bytes to fill a page, but better to keep
// the memory properly paged instead of having varied sized bytes
return out.bytes();
}
};
logger.info("cache key="+cacheKey.utf8ToString());
return indicesRequestCache.getOrCompute(cacheEntity, supplier, reader, cacheKey, cacheKeyRenderer);
}代码的实现细节,大家可以下载源码来看。我在这段代码内加了一行日志,用来打印 es 对于搜索结果的缓存键,分析得出,该缓存键对应的是搜索请求参数组合的一行字符串。我们在实际使用搜索服务的场景中,分页功能其实是我们最最常见并且应用最多的一个功能。分页结果的响应速度直接可以决定用户的搜索体验。所以优化 es 的分页很有必要,一个良好的缓存策略对分页性能有极大的影响。
再次吐槽一下 es 的缓存策略,我模拟一个大家都常见的搜索场景。
我搜索“苹果”关键词,每次翻页取 10 条数据展示。
es的处理过程为:关键词query匹配-->rescore-->得到topN条文档-->fetch highlight-->返回10条结果如果使用 request_cache=true 参数,则处理过程为:
第一次搜索:关键词query匹配-->rescore-->得到topN条文档-->cache topN-->fetch highlight-->返回10条结果
第二次搜索: 关键词query匹配 --> cache topN -->fetch highlight-->返回10条结果问题来了,搜索第二页的时候,es 的缓存键由于关联了offset 所以在翻页场景中变得很鸡肋。在热词缓存下还能有一席之地。每次翻一页都需要重新处理,用户使用翻页功能的体验很差。
那么我们该如何来设计 es 的缓存策略呢?
不用想,我们学着阿里云来就行了,这个问题他们肯定已经解决了。
方法很简单,我们去阿里云搜索测试界面,进行搜索测试,来研究分页缓存策略。
分析发现,同一个搜索关键词,同样的搜索条件,每次 10 条,搜索三次以上,就会发现,响应体中的 searchtime 参数从变小了,再过一段时间去搜又恢复,连续几次又变小。翻页结果到 2000 条左右的时候,searchtime 不再变小,一直都是平滑的。
那我们大致就可以推测出阿里云搜索的缓存策略了:缓存 key 设置为与 offset 无关,固定一个阈值比如说 2000 条 TopN 数据,N 秒内,M 次同样的搜索条件(排除 offset )都一样,则内部触发一个异步请求,异步请求主要用来建立该搜索条件下前 2000 条 TopN 的记录。缓存设置一下生命周期。es有一套内部的缓存过期机制,简单理解为一段预设缓存空间内 LRU 淘汰。
我们得到了大致的缓存策略优化方向,接下来再改造源码就是时间问题了。为此不做过多的赘述,感兴趣的朋友可以持续关注我哦~。如果大家也遇到es相关的问题,请在下方积极留言哦~
作者:allen
来源:知乎
原文链接:zhuanlan.zhihu.com/p/152351263





 关于 LearnKu
关于 LearnKu




推荐文章: