
[转载] Elasticsearch 聚合——Bucket Aggregations
Terms Aggregation
先看看官方给出的例子。
GET /_search
{
"aggs" : {
"genres" : {
"terms" : { "field" : "genre" }
}
}
}
响应结果:
{
...
"aggregations" : {
"genres" : {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets" : [
{
"key" : "electronic",
"doc_count" : 6
},
{
"key" : "rock",
"doc_count" : 3
},
{
"key" : "jazz",
"doc_count" : 2
}
]
}
}
}
从例子中可以了解到,Terms Aggregation 以指定域的唯一值(term)构建出多个桶,每个桶包含了 key 为域的值(term),doc_count 为含有这个值(term)的文档数。
默认情况下,响应将返回10个桶。当然也可以指定 size 参数改变返回的桶的数量。
Size 与精度
Terms Aggregation 返回结果中的 doc_count- 是近似的,并不是一个准确数。
根据 Elasticsearch 的机制,每个分片都会根据各自拥有的数据进行计算并且进行排序,最后协调节点对各个分片的计算结果进行整理并返回给客户端。而就是因为这样,产生出精度的问题,也就是计算的结果有误差。
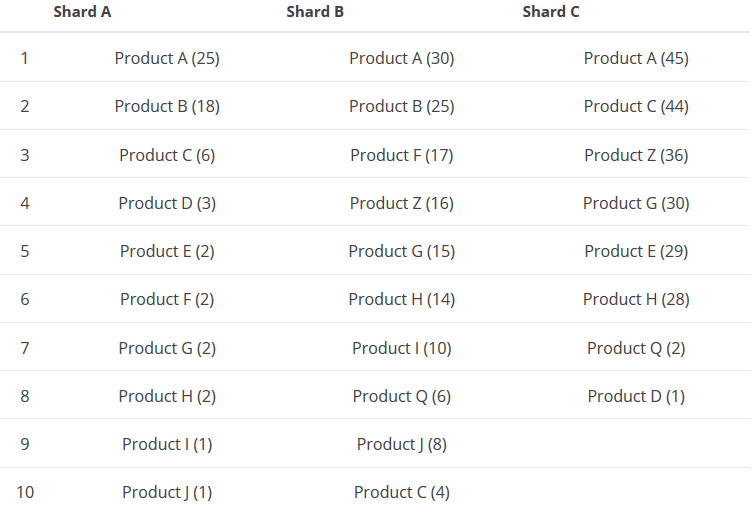
下面为官方给出的例子:有一组数据,数据中包含一个 product 字段,记录了产品的数量。请求获取产品数量 TOP 5 的数据。而数据存在有3个分片的索引中。
当ES收到请求:
GET /_search
{
"aggs" : {
"products" : {
"terms" : {
"field" : "product",
"size" : 5
}
}
}
}
会有如下动作发生:
各个分片计算得出的结果。
然后分片将会把TOP 5的数据返回给协调节点。

最后,协调节点将会根据各个节点给出的数据进行整理得出最后TOP 5的数据并返回给客户端。

可以看出,在第二步中,由于各个分片的数据有所不同,在分片A能排得上TOP 5的 term 在分片B却排不上 ,所以在最后各个分片返回数据给协调节点时,有数据丢失了。如 Product C,在分片A中排第三位,在Product B中却排第10位,所以协调节点将获将不知道在分片B中,有4个文档含有 Product C 。所以关于 Product C 的 doc_count 是有误的。
不过也可以看出,在各个分片中,均排第一的 Product A 的 doc_count 数据是正确的。因为各个分片都返回了含有 Product A 的文档数,没有发生像 Product C 一样丢失数据的情况。那么如果分片返回的数据不是TOP 5,而是TOP 10,Product C 在各个分片中的数据信息就会和 Product A 一样都返回给了协调节点,这样 Product C 的 doc _count 数据便是准确的。所以,只要各个分片都返回足够多的数据给协调节点,客户端得到的结果将是精准的。
而开始提到的参数 size 就会控制分片返回给节点的数据量以及返回给客户端的数据量。可见,参数 size 越大,获取的结果的精度越高。
Shard Size
上面提到,size 的大小会影响到聚合结果的精准度,size 值越大,精度越高。为了更高得精度,请求的时候将 size 值设置得偏大,这时会有一个问题,就是客户端将会得到大量的响应数据,而且这些响应数据对于客户端来说大部分都是没用的,而大量的响应数据还会耗费网络资源。
这时,就要使用到另一个参数 shard_size 。shard_size 只会控制分片返回给协调节点的数据量,而最后协调节点整理并返回的数据量由 size 控制,这样既能提升精度,也避免了上述由于要提升精度而导致协调节点返回大量响应数据给客户端的问题。
上面的内容由提到,size 会控制分片返回给协调节点的数据量,这段描述即正确也不正确。默认情况下,shard_size 的大小为 (size * 1.5 + 10) ,确实由 size 值控制,但是如果在请求时显式提供 shard_size 参数,自然 size 与分片返回给节点的数据量无关。
没显示的文档数
在响应结果中,有一个 sum_other_doc_count 值。假如 size 设定为5,那么响应中只有 doc_count 前5的桶的数据,而 sum_other_doc_count 表示的就是没有返回的其他桶的文档数的总和。
文档数计算错误上限
Terms Aggreagation 的响应结果中,有一个 doc_count_error_upper_bound 值。这个值表示的是在聚合中,没有在最终结果(响应给客户端的结果)中的 term 最大可能有 doc_count_error_upper_bound 个文档含有。这是ES预估可能出现的最坏的结果。
doc_count_error_upper_bound 是这样计算出来的:假如请求像上面 Product 的例子一样,size = 5,协调节点会将各个分片的排第五的 term 的文档数相加起来(根据上面的例子就是2+15+29),得出的结果便是 doc_count_error_upper_bound 。
根据 doc_count_error_upper_bound 的计算是基于这样的猜想(继续以上面的 Product 为例子),可能存在Product Z1,它在分片A中,包含它的文档数是2,在分片B中它的文档数是15,在分片C中它的文档数是29,然后在各个分片的排名均是第六位,这样在协调节点将获取不到有关 Product Z1 的数据,便会将这个 Product Z1 排除在外,然而实际上这个 Product Z1 是足以排进前5的。
当然上述提到的情况并不没有这么容易发生,但是 doc_count_error_upper_bound 越大,错误发生的可能性也越大(这个大是指与响应的结果作比较)。这时候可以适当增大 size 的值,让更多的数据参与到协调节点的整理过程中。
每个桶的错误上限
如上面提到的文档数计算错误上限类似,不过这个是精确到每个桶的。
这个默认是关闭的,要开启就需要传递 show_term_doc_count_error 参数。
GET /_search
{
"aggs" : {
"products" : {
"terms" : {
"field" : "product",
"size" : 5,
"show_term_doc_count_error": true
}
}
}
}
响应结果
{
...
"aggregations" : {
"products" : {
"doc_count_error_upper_bound" : 46,
"sum_other_doc_count" : 79,
"buckets" : [
{
"key" : "Product A",
"doc_count" : 100,
"doc_count_error_upper_bound" : 0
},
{
"key" : "Product Z",
"doc_count" : 52,
"doc_count_error_upper_bound" : 2
}
...
]
}
}
}
每个桶的错误上限是这样计算的:响应结果中的 term 在没有返回相关数据的分片的最后一名的文档数之和。以上述例子中的 Product Z 为例,分片B,分片C响应给协调节点的数据均包含了 Product Z 相关的数据,但是分片A却没有,那么就有可能是 Product Z 在分片A中排不到前5,那么 Product Z 在分片A中最大的可能值就是与 Product E 一样,也就是2。当然像 Product A 一样各个分片都有返回相关的数据的话,这个错误上限就是0。
PS:如果 doc_count 作为排序的域,则不会有上述的错误上限
排序
聚合结果按照指定域排序。默认情况下,是按照 doc_count 排序的。
例如想而 term 的值以字典顺序排序
GET /_search
{
"aggs" : {
"genres" : {
"terms" : {
"field" : "genre",
"order" : { "_key" : "asc" }
}
}
}
}
PS:在ES6.0版本以前是使用 _term 的,6.0之后采用 _key 代替。
还可以以子聚合的结果作为排序依据:
GET /_search
{
"aggs" : {
"genres" : {
"terms" : {
"field" : "genre",
"order" : { "max_play_count" : "desc" }
},
"aggs" : {
"max_play_count" : { "max" : { "field" : "play_count" } }
}
}
}
}
如果子聚合如统计聚合一样有多个值,可以指定结果中特定的值进行排序:
GET /_search
{
"aggs" : {
"genres" : {
"terms" : {
"field" : "genre",
"order" : { "playback_stats.max" : "desc" }
},
"aggs" : {
"playback_stats" : { "stats" : { "field" : "play_count" } }
}
}
}
}
如果子聚合是多层的,还可以这样指定排序的值:
GET /_search
{
"aggs" : {
"countries" : {
"terms" : {
"field" : "artist.country",
"order" : { "rock>playback_stats.avg" : "desc" }
},
"aggs" : {
"rock" : {
"filter" : { "term" : { "genre" : "rock" }},
"aggs" : {
"playback_stats" : { "stats" : { "field" : "play_count" }}
}
}
}
}
}
}
最小文档数
对于聚合结果,可以限制响应结果的最小文档数,如果桶小于指定的文档数将,将不会响应给客户端。
在请求中添加上 min_doc_count 参数。
GET /_search
{
"aggs" : {
"tags" : {
"terms" : {
"field" : "tags",
"min_doc_count": 10
}
}
}
}
min_doc_count 的默认值为1.
除了 min_doc_count 外,还有一个 shard_min_doc_count 参数。这个参数的作用是什么呢?
假如请求设置了 order 参数,那么分片在检索数据时将按照指定的域进行排序,而这样可能会让大量的文档数只有数个甚至是的桶加入到候选队列,返回给协调节点。文档数只有数个的桶,有可能是十分冷门的,用户不感兴趣的数据,又或者是拼写错误的数据,但是由于排序的时候并不基于文档数,那么就可能让真正有效的,用户感兴趣的桶给排除出分片的候选队列。而 min_doc_count 是作用于协调节点整理数据的时候,对于分片的这种情况,min_doc_count 无法起到作用。
而这时就是 shard_min_doc_count 发挥的时候,它的作用与 min_doc_count 类似,不过作用于分片调选候选数据的时候,设置合适的 shard_min_doc_count 参数,就可以避免上述提到的问题。
默认情况下,shard_min_doc_count 的值为0,只有显示设置该参数才会起作用。
过滤
在进行查询时,想要过滤掉某些值是常见的需求。在 Terms Aggregation 时,可以过滤掉一些不感兴趣的桶。
通过正则表达式匹配过滤:
GET /_search
{
"aggs" : {
"tags" : {
"terms" : {
"field" : "tags",
"include" : ".*sport.*",
"exclude" : "water_.*"
}
}
}
}
term 中包含 sport 但是不含有 water 开头才会在响应结果中被返回。
当然也可以直接指定具体的值进行过滤:
GET /_search
{
"aggs" : {
"JapaneseCars" : {
"terms" : {
"field" : "make",
"include" : ["mazda", "honda"]
}
},
"ActiveCarManufacturers" : {
"terms" : {
"field" : "make",
"exclude" : ["rover", "jensen"]
}
}
}
}
结果分组
在聚合计算中,结果可能回是庞大的(有大量的桶),而且业务要求需要尽可能多的去处理各个桶。在这种情况下就需要用到分组功能。
具体的请求例子如下:
GET /_search
{
"size": 0,
"aggs": {
"expired_sessions": {
"terms": {
"field": "account_id",
"include": {
"partition": 0,
"num_partitions": 20
},
"size": 10000,
"order": {
"last_access": "asc"
}
},
"aggs": {
"last_access": {
"max": {
"field": "access_date"
}
}
}
}
}
}
分组请求会将结果分成 num_partitions 组,每一组的大小由参数 size 决定,然后请求会返回指定的组,由参数 partition 决定。分组的序列由参数 order 决定。
结合上面的例子,就是将结果分成20组,每组的大小为10000,然后返回第0组的结果。想要获取后续组的结果,改变参数 partition 的值,例如改为1,就获取第1组的结果,而其他参数不需要改变。这样一直下去,直到取完所有分组的结果。
这里需要注意的是,遍历完所有的分组值,其总的结果数量最大为 (num_partitions * size) 。所以,如果想要尽可能处理所有的桶,就需要以下步骤:
- 利用 Cardinality Aggregation 获取指定域的唯一值数量,换句话说就是桶的数量。
- 根据步骤一获取的桶的数量决定分组的组数。
- 根据桶的数量以及分组的组数计算出 size 的大小。
- 构建请求。
Collect mode
Collect mode 决定当有子聚合时,执行子聚合计算的时机。
有一组电影相关的数据,电影数据中包含电影的出演演员,而出演演员数据含有合演演员数据。现在搜索出前10位最常出演的演员,以及各位演员最常合作的前5位合演者。
有以下请求:
GET /_search
{
"aggs" : {
"actors" : {
"terms" : {
"field" : "actors",
"size" : 10
},
"aggs" : {
"costars" : {
"terms" : {
"field" : "actors",
"size" : 5
}
}
}
}
}
}
上述请求存在以下两种处理的方式。
深度优先
在聚合计算下,多层聚合会让一个文档与其他文档产生关联,也就是说会形成一颗颗聚合树。深度优先就是先计算获得所有的聚合树,然后再进行后续处理。计算的步骤如下:
先计算出一个桶,然后再根据这个桶计算出子聚合的结果,构建出一颗聚合树。然后不断重复上面的过程,直到所有的桶计算完毕。
对步骤一计算出的结果进行排序,也就是对各个聚合树进行排序。
根据过滤条件和 size 等参数修整结果。

广度优先
广度优先将会先计算整理出所有父节点(第一层的桶),然后再进行后续步骤,具体计算步骤如下:
先计算出第一层聚合的结果。

根据步骤一得出的结果进行排序。

根据过滤条件和 size 等参数修整第一层节点。
根据各个节点进行后续的子聚合计算。
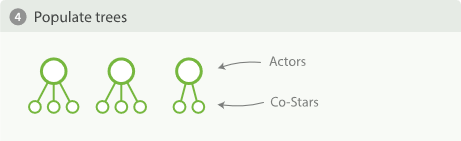
深度优先 VS 广度优先
在进行请求时,可以传递 collect_mode 参数指定聚合计算的方式,也就是上述的两种方式 depth_first 深度优先以及 breadth_first 广度优先。
GET /_search
{
"aggs" : {
"actors" : {
"terms" : {
"field" : "actors",
"size" : 10,
"collect_mode" : "breadth_first"
},
"aggs" : {
"costars" : {
"terms" : {
"field" : "actors",
"size" : 5
}
}
}
}
}
}
上面电影演员搜索的例子,广度优先会比深度优先更为合适。
深度优先在一般情况下是没问题的,但是如果指定的域有大量的基数(唯一值),进行上述的计算方式,可以预计到将会消耗大量的资源,因为每个桶都会计算出完整的聚合树,而且这些消耗毫无意义,因为大部分结果是会被丢弃的。 而广度优先就很合适了,提前筛选出父聚合的结果,将后续子聚合的计算的消耗控制到最小。
但是广度优先会缓存各个桶相关的文档数据,因为后续的子聚合是根据上一层的相关数据进行计算的。如果每个桶相关的文档数据是巨大的,就是说各个桶的 doc_count 非常大,会有很大的资源消耗。
那么在请求时如何决定 collect_mode 呢?答案是尽量不设置,也就是使用默认值。根据官方文档,在默认情况下,如果指定域的基数是很大的或者说无法确定(例如指定的是数值类型的域或者说是用脚本进行聚合),那么采用的是广度优先的方式。反之,采用的可能就是深度优先的方式。当然默认处理不一定每次都能够成功选出最优的方式,这时就需要在请求中明确支持 collect mode 。
Execution hint
Terms Aggregation 的计算方式主要有以下两种:
- map,在内存中构建映射表,利用映射表完成聚合计算,可以看得出,这种方式会比较消耗内存。
- global_ordinals,每个桶都会有一个全局序列号,也就是指定域中的唯一值都会有一个全局序列号,根据这个序列号完成相关的聚合过程。计算过程消耗的内存较小,因为使用全局序列号的话可以将计算中的中间结果存储到硬盘等存储介质中。
一般来说 global_ordinals 将作为默认选项。而 map 只能应用于只有少量文档的情况下,当然,map 能够更快地计算出结果,可以看作是空间换时间的一种方式。
在请求中,可以通过传递 execution_hint 参数指定计算执行的方式。
GET /_search
{
"aggs" : {
"tags" : {
"terms" : {
"field" : "tags",
"execution_hint": "map"
}
}
}
}
要注意的是,如果 execution_hint 参数指定的方式不存在ES将会无视。而且这些都没有保证向后兼容,也就说以后的版本可能会取消 map 或 global_ordinals 采用更加好的计算方式。
Filter Aggregation
过滤器聚合,先看看例子:
POST /sales/_search?size=0
{
"aggs" : {
"t_shirts" : {
"filter" : { "term": { "type": "t-shirt" } },
"aggs" : {
"avg_price" : { "avg" : { "field" : "price" } }
}
}
}
}
响应结果:
{
...
"aggregations" : {
"t_shirts" : {
"doc_count" : 3,
"avg_price" : { "value" : 128.33333333333334 }
}
}
}
Filter Aggregation 指定具体的域和具体的值,可以说是在 Terms Aggregation 的基础上进行了过滤,只对特定的值进行了聚合。
Filters Aggreagation
Filter Aggreagtion 只能指定一个过滤条件,响应也只是单个桶。如果想要只对多个特定值进行聚合,使用 Filter Aggreagtion 只能进行多次请求。
而使用 Filters Aggreagation 就可以解决上述的问题,它可以指定多个过滤条件,也是说可以对多个特定值进行聚合。 例子如下:
PUT /logs/_doc/_bulk?refresh
{ "index" : { "_id" : 1 } }
{ "body" : "warning: page could not be rendered" }
{ "index" : { "_id" : 2 } }
{ "body" : "authentication error" }
{ "index" : { "_id" : 3 } }
{ "body" : "warning: connection timed out" }
GET logs/_search
{
"size": 0,
"aggs" : {
"messages" : {
"filters" : {
"filters" : {
"errors" : { "match" : { "body" : "error" }},
"warnings" : { "match" : { "body" : "warning" }}
}
}
}
}
}
响应结果:
{
"took": 9,
"timed_out": false,
"_shards": ...,
"hits": ...,
"aggregations": {
"messages": {
"buckets": {
"errors": {
"doc_count": 1
},
"warnings": {
"doc_count": 2
}
}
}
}
}
Anonymous filters
匿名过滤器,可以不用指定过滤器的名称,也就是桶名。以数组的方式传递过滤条件。
GET logs/_search
{
"size": 0,
"aggs" : {
"messages" : {
"filters" : {
"filters" : [
{ "match" : { "body" : "error" }},
{ "match" : { "body" : "warning" }}
]
}
}
}
}
响应结果:
{
"took": 4,
"timed_out": false,
"_shards": ...,
"hits": ...,
"aggregations": {
"messages": {
"buckets": [
{
"doc_count": 1
},
{
"doc_count": 2
}
]
}
}
}
Other Bucket
在 Filters Aggreagation 中还有一个可选参数 other_bucket,参数类型为布尔值,默认为 false 。如果将该参数设置为 true ,则会将不满足任一过滤条件的文档进行聚合计算,将结果放到名为 other 的桶中。 在原先的例子的基础上添加以下文档:
PUT logs/_doc/4?refresh
{
"body": "info: user Bob logged out"
}
发起请求:
GET logs/_search
{
"size": 0,
"aggs" : {
"messages" : {
"filters" : {
"other_bucket": true,
"filters" : {
"errors" : { "match" : { "body" : "error" }},
"warnings" : { "match" : { "body" : "warning" }}
}
}
}
}
}
响应结果:
{
"took": 3,
"timed_out": false,
"_shards": ...,
"hits": ...,
"aggregations": {
"messages": {
"buckets": {
"errors": {
"doc_count": 1
},
"warnings": {
"doc_count": 2
},
"_other_": {
"doc_count": 1
}
}
}
}
}
如果想要指定 Other Bucket 的名称,可以使用参数 other_bucket_key 设置。设置了参数 other_bucket_key ,默认就是将参数 other_bucket 设置为true。 例子如下:
GET logs/_search
{
"size": 0,
"aggs" : {
"messages" : {
"filters" : {
"other_bucket_key": "other_messages",
"filters" : {
"errors" : { "match" : { "body" : "error" }},
"warnings" : { "match" : { "body" : "warning" }}
}
}
}
}
}
响应结果:
{
"took": 3,
"timed_out": false,
"_shards": ...,
"hits": ...,
"aggregations": {
"messages": {
"buckets": {
"errors": {
"doc_count": 1
},
"warnings": {
"doc_count": 2
},
"other_messages": {
"doc_count": 1
}
}
}
}
}
Range Aggregation
Range Aggregation 根据用户传递的范围参数作为桶,进行相应的聚合。在同一个请求中,可以传递多组范围,每组范围作为一个桶。
例子如下:
GET /_search
{
"aggs" : {
"price_ranges" : {
"range" : {
"field" : "price",
"ranges" : [
{ "to" : 100.0 },
{ "from" : 100.0, "to" : 200.0 },
{ "from" : 200.0 }
]
}
}
}
}
响应结果如下:
{
...
"aggregations": {
"price_ranges" : {
"buckets": [
{
"key": "*-100.0",
"to": 100.0,
"doc_count": 2
},
{
"key": "100.0-200.0",
"from": 100.0,
"to": 200.0,
"doc_count": 2
},
{
"key": "200.0-*",
"from": 200.0,
"doc_count": 3
}
]
}
}
}
注意每组范围的区间为 [from,to) 。
一般来说,范围聚合响应结果的形式为数组,当然,也可以设置为键值对的形式。在请求中可以设置 keyed 参数,默认为 false ,如果设置成 true 的话就会以键值对的形式响应。
GET /_search
{
"aggs" : {
"price_ranges" : {
"range" : {
"field" : "price",
"keyed" : true,
"ranges" : [
{ "to" : 100 },
{ "from" : 100, "to" : 200 },
{ "from" : 200 }
]
}
}
}
}
响应结果:
{
...
"aggregations": {
"price_ranges" : {
"buckets": {
"*-100.0": {
"to": 100.0,
"doc_count": 2
},
"100.0-200.0": {
"from": 100.0,
"to": 200.0,
"doc_count": 2
},
"200.0-*": {
"from": 200.0,
"doc_count": 3
}
}
}
}
}
再进一步,还可以自定义设置键值:
GET /_search
{
"aggs" : {
"price_ranges" : {
"range" : {
"field" : "price",
"keyed" : true,
"ranges" : [
{ "key" : "cheap", "to" : 100 },
{ "key" : "average", "from" : 100, "to" : 200 },
{ "key" : "expensive", "from" : 200 }
]
}
}
}
}
响应结果:
{
...
"aggregations": {
"price_ranges" : {
"buckets": {
"cheap": {
"to": 100.0,
"doc_count": 2
},
"average": {
"from": 100.0,
"to": 200.0,
"doc_count": 2
},
"expensive": {
"from": 200.0,
"doc_count": 3
}
}
}
}
}
最后,关于范围聚合还有一个常见的用法,就是与统计聚合一起配合,按范围进行数据统计。
GET /_search
{
"aggs" : {
"price_ranges" : {
"range" : {
"field" : "price",
"ranges" : [
{ "to" : 100 },
{ "from" : 100, "to" : 200 },
{ "from" : 200 }
]
},
"aggs" : {
"price_stats" : {
"stats" : { "field" : "price" }
}
}
}
}
}
响应结果:
{
...
"aggregations": {
"price_ranges": {
"buckets": [
{
"key": "*-100.0",
"to": 100.0,
"doc_count": 2,
"price_stats": {
"count": 2,
"min": 10.0,
"max": 50.0,
"avg": 30.0,
"sum": 60.0
}
},
{
"key": "100.0-200.0",
"from": 100.0,
"to": 200.0,
"doc_count": 2,
"price_stats": {
"count": 2,
"min": 150.0,
"max": 175.0,
"avg": 162.5,
"sum": 325.0
}
},
{
"key": "200.0-*",
"from": 200.0,
"doc_count": 3,
"price_stats": {
"count": 3,
"min": 200.0,
"max": 200.0,
"avg": 200.0,
"sum": 600.0
}
}
]
}
}
}
如果请求像上述一样,范围聚合与统计聚合作用的域是一致的,可以省略子聚合指定的域。将会自动根据父聚合指定的域进行聚合计算。
GET /_search
{
"aggs" : {
"price_ranges" : {
"range" : {
"field" : "price",
"ranges" : [
{ "to" : 100 },
{ "from" : 100, "to" : 200 },
{ "from" : 200 }
]
},
"aggs" : {
"price_stats" : {
"stats" : {}
}
}
}
}
}
Histogram Aggregation
直方图聚合。就像名称一样,采用的是直方图的聚合方式,划分多个区间,根据划分的区间对数据进行聚合。理所当然的,直方图聚合指定的域必须是数字类型的。
请求例子如下:
POST /sales/_search?size=0
{
"aggs" : {
"prices" : {
"histogram" : {
"field" : "price",
"interval" : 50
}
}
}
}
参数 interval 表示的是直方图的间隔,也就是各个直方的宽度。
响应结果如下:
{
...
"aggregations": {
"prices" : {
"buckets": [
{
"key": 0.0,
"doc_count": 1
},
{
"key": 50.0,
"doc_count": 1
},
{
"key": 100.0,
"doc_count": 0
},
{
"key": 150.0,
"doc_count": 2
},
{
"key": 200.0,
"doc_count": 3
}
]
}
}
}
对于值的在响应结果中的分布,是根据以下公式:
Math.floor((value - offset) / interval) * interval + offset
offset 在后面会提到,这个变量默认为0。所以在默认情况下,就是值除以间隔的结果向下取整后乘间隔,得到的结果便是值所在的桶。
结合上述例子,简单点来说就是数据在 [0,50) 落在桶0,在 [50,100) 落在桶50,以此类推,所有结果汇聚起来就是直方图的分布。
offset
一般来说直方图都是从0点开始,然后根据间隔进行数据的聚合。而 offset 可以使各个区间发生偏移。为了更直观的了解 offset ,查看以下的例子。
有数据:
...
"hits": [
{
"_index": "maket",
"_type": "prices",
"_id": "87g60GQBQURyl69vW-Z4",
"_score": 1,
"_source": {
"price": 17
}
},
{
"_index": "maket",
"_type": "prices",
"_id": "8Lg50GQBQURyl69vzOaJ",
"_score": 1,
"_source": {
"price": 10
}
},
{
"_index": "maket",
"_type": "prices",
"_id": "8bg60GQBQURyl69vOeZT",
"_score": 1,
"_source": {
"price": 3
}
},
{
"_index": "maket",
"_type": "prices",
"_id": "9Lg60GQBQURyl69vbOYT",
"_score": 1,
"_source": {
"price": 28
}
},
{
"_index": "maket",
"_type": "prices",
"_id": "8rg60GQBQURyl69vReat",
"_score": 1,
"_source": {
"price": 3
}
}
]
先进行简单的直方图聚合:
{
"aggs" : {
"prices" : {
"histogram" : {
"field" : "price",
"interval" : 5
}
}
}
}
响应结果:
...
"aggregations": {
"prices": {
"buckets": [
{
"key": 0,
"doc_count": 2
},
{
"key": 5,
"doc_count": 0
},
{
"key": 10,
"doc_count": 1
},
{
"key": 15,
"doc_count": 1
},
{
"key": 20,
"doc_count": 0
},
{
"key": 25,
"doc_count": 1
}
]
}
接着尝试设置 offset:
{
"aggs" : {
"prices" : {
"histogram" : {
"field" : "price",
"interval" : 5,
"offset": 2
}
}
}
}
响应结果:
...
"aggregations": {
"prices": {
"buckets": [
{
"key": 2,
"doc_count": 2
},
{
"key": 7,
"doc_count": 1
},
{
"key": 12,
"doc_count": 0
},
{
"key": 17,
"doc_count": 1
},
{
"key": 22,
"doc_count": 0
},
{
"key": 27,
"doc_count": 1
}
]
}
可以看到,所有直方图的区间都发生了偏移,变成了[2, 7),[7, 12) … 的分布。
那么如果offset过大,会不会使到一些数值偏小的值没有聚合到桶中。例如 offset 为4,那么第一个桶便是 4,落在该桶的数据区间为[4, 9),数值3将落不到桶中。这里尝试一下:
{
"aggs" : {
"prices" : {
"histogram" : {
"field" : "price",
"interval" : 5,
"offset": 4
}
}
}
}
响应结果:
"aggregations": {
"prices": {
"buckets": [
{
"key": -1,
"doc_count": 2
},
{
"key": 4,
"doc_count": 0
},
{
"key": 9,
"doc_count": 1
},
{
"key": 14,
"doc_count": 1
},
{
"key": 19,
"doc_count": 0
},
{
"key": 24,
"doc_count": 1
}
]
}
原先3的值落到了-1桶中,总的来说还是根据上述的公式进行桶的划分。
最小文档数限制
参数 min_doc_count 可以控制结果中的最小文档数,若将 min_doc_count 设置为1,则如果桶的 doc_count 小于1将不会返回。min_doc_count默认为0
延申范围
参数 extended_bounds 可以将直方图的范围延申。直接看看例子:
{
"aggs" : {
"prices" : {
"histogram" : {
"field" : "price",
"interval" : 5,
"extended_bounds" : {
"min":0,
"max": 30
}
}
}
}
}
响应结果:
...
"aggregations": {
"prices": {
"buckets": [
{
"key": 0,
"doc_count": 2
},
{
"key": 5,
"doc_count": 0
},
{
"key": 10,
"doc_count": 1
},
{
"key": 15,
"doc_count": 1
},
{
"key": 20,
"doc_count": 0
},
{
"key": 25,
"doc_count": 1
},
{
"key": 30,
"doc_count": 0
}
]
}
在原先的聚合结果的基础上,增加了桶30。
不过 extended_bounds 只是一个延申而已,也就说如果结果可以超过这个范围,简单点来说就是 extended_bounds 无法起到过滤的效果。
{
"aggs" : {
"prices" : {
"histogram" : {
"field" : "price",
"interval" : 5,
"extended_bounds" : {
"min":10,
"max": 20
}
}
}
}
}
结果如下:
"aggregations": {
"prices": {
"buckets": [
{
"key": 0,
"doc_count": 2
},
{
"key": 5,
"doc_count": 0
},
{
"key": 10,
"doc_count": 1
},
{
"key": 15,
"doc_count": 1
},
{
"key": 20,
"doc_count": 0
},
{
"key": 25,
"doc_count": 1
}
]
}
如果想要控制范围,只能在查询阶段进行过滤。如下:
{
"query": {
"constant_score": {
"filter": {
"range": {
"price": {
"to": "10"
}
}
}
}
},
"aggs": {
"prices": {
"histogram": {
"field": "price",
"interval": 5
}
}
}
}
结果格式
响应结果默认是以数组的方式返回,也可以将结果设置成键值对的形式。传递参数 keyed 并设置成 true 即可。如下:
{
"aggs" : {
"prices" : {
"histogram" : {
"field" : "price",
"interval" : 5,
"keyed": true
}
}
}
}
响应结果:
...
"aggregations": {
"prices": {
"buckets": {
"0.0": {
"key": 0,
"doc_count": 2
},
"5.0": {
"key": 5,
"doc_count": 0
},
"10.0": {
"key": 10,
"doc_count": 1
},
"15.0": {
"key": 15,
"doc_count": 1
},
"20.0": {
"key": 20,
"doc_count": 0
},
"25.0": {
"key": 25,
"doc_count": 1
}
}
}
IP Range Aggregation
IP Range Aggregation 是针对 IP 地址数据的范围聚合,基本的特性与 Range Aggreagtion 一致。
详情参考:IP Range Aggregation
Date Range Aggreagtion
针对于时间格式数据的范围聚合,基本的特性与 Range Aggreagtion 一致。 详情参考:Date Range Aggregation
Date Histogram Aggregation
针对于时间格式数据的直方图聚合,基本的特性与 Histogram Aggregation 一致。 详情参考:Date Histogram Aggregation
Significant Terms Aggregation
有一组千万级的疾病数据文档,这些疾病数据文档有一个域记载了引发病毒的数据。而其中,病毒数据中有H5N1关键字的文档只有5份,只有 5/10,000,000 的比率,而有100份含有“禽流感”信息的文档,这些文档中有4份病毒数据中含有H5N1关键字,比率为 4/100 。通过对比 5/10,000,000 和 4/100 这两个比率,可以清楚,H5N1与禽流感有高度的相关性,所以在用户检索禽流感信息时,我们应该尽量的返回关于H5N1的数据。这就是一种找出有效数据的检索方式。而 Significant Terms Aggregation 则是能够实现上述这种检索的聚合。
官方给出的例子是关于犯罪的一组数据,并利用 Significant Terms Aggregation 进行了相关的检索:
GET /_search
{
"query" : {
"terms" : {"force" : [ "British Transport Police" ]}
},
"aggregations" : {
"significant_crime_types" : {
"significant_terms" : { "field" : "crime_type" }
}
}
}
响应结果:
{
...
"aggregations" : {
"significant_crime_types" : {
"doc_count": 47347,
"bg_count": 5064554,
"buckets" : [
{
"key": "Bicycle theft",
"doc_count": 3640,
"score": 0.371235374214817,
"bg_count": 66799
}
...
]
}
}
}
结果中, 最外层的 doc_count 指的是 force 域为 “British Transport Police” 的文档数量,而 bg_count 则是有关犯罪数据的总的文档数量。
而在 buckets 中的 doc_count 值的在 force 域为 “British Transport Police” 的文档数据中是 crime_type 域为 “Bicycle theft” 的文档数量,而 bg_count 则是指在所有犯罪数据中 crime_type 域为 “Bicycle theft” 的文档数量。
在5064554的犯罪数据中,有66799是关于 Bicycle theft,Bicycle theft 占数据的1%。而在具体到 British Transport Police 时,Bicycle theft 占7%(3640/47347),根据上述两个数据的对比,可以得知 British Transport Police 与 Bicycle theft的关联。
Significant Terms Aggregation 还可以作为子聚合,分析不同的数据,得到多个结果。
GET /_search
{
"aggregations": {
"forces": {
"terms": {"field": "force"},
"aggregations": {
"significant_crime_types": {
"significant_terms": {"field": "crime_type"}
}
}
}
}
}
响应结果:
{
...
"aggregations": {
"forces": {
"doc_count_error_upper_bound": 1375,
"sum_other_doc_count": 7879845,
"buckets": [
{
"key": "Metropolitan Police Service",
"doc_count": 894038,
"significant_crime_types": {
"doc_count": 894038,
"bg_count": 5064554,
"buckets": [
{
"key": "Robbery",
"doc_count": 27617,
"score": 0.0599,
"bg_count": 53182
}
...
]
}
},
{
"key": "British Transport Police",
"doc_count": 47347,
"significant_crime_types": {
"doc_count": 47347,
"bg_count": 5064554,
"buckets": [
{
"key": "Bicycle theft",
"doc_count": 3640,
"score": 0.371,
"bg_count": 66799
}
...
]
}
}
]
}
}
}
score
在 Significant Terms Aggregation 中的桶是根据 score 进行排序的。score 是通过结合背景数据集(也就是相关的 bg_count 数据)和符合条件的数据(doc_count)进行计算得出的。
score 的计算有多种策略,因为我也没有实际上应用过 Significant Terms Aggregation ,所以对不同的计算策略也不大清楚,详情参考:Significant Terms Aggregation#Parameters
自定义背景数据
Significant Terms Aggregation 中的背景数据不一定是所有的数据集,可以通过参数 background_filter 进行相应设置。
GET /_search
{
"query" : {
"match" : {
"city" : "madrid"
}
},
"aggs" : {
"tags" : {
"significant_terms" : {
"field" : "tag",
"background_filter": {
"term" : { "text" : "spain"}
}
}
}
}
}
其他
Significant Terms Aggregation 与 Terms Aggregation 在部分特性上是相似的,例如 size 与 shard_size 参数,min_doc_count 参数以及 execution_hint 参数。
- +Significant Terms Aggregation 的结果同样是近似的。还有就是 Significant Terms Aggregation 作为父聚合时,如果没有查询条件那得出的结果是没有意义的,因为没有区分出背景数据以及符合数据。
Global Aggregation
Global Aggregation 主要是起到能够脱离查询条件的限制,对所有文档进行相关的聚合。
具体的应用例子如下:
POST /sales/_search?size=0
{
"query" : {
"match" : { "type" : "t-shirt" }
},
"aggs" : {
"all_products" : {
"global" : {},
"aggs" : {
"avg_price" : { "avg" : { "field" : "price" } }
}
},
"t_shirts": { "avg" : { "field" : "price" } }
}
}
响应结果:
{
...
"aggregations" : {
"all_products" : {
"doc_count" : 7,
"avg_price" : {
"value" : 140.71428571428572
}
},
"t_shirts": {
"value" : 128.33333333333334
}
}
}
Global Aggregation 中的 global 参数不需要值,主要是作为一个父聚合,从属于 Global Aggregation 的子聚合的聚合计算范围将是该索引下的所有的文档,也就是说不受 query 的的影响。而响应结果中,Global Aggregation 聚合结果中的 doc_count 表示参与了聚合计算的文档数。
Global Aggregation 是为了在一次查询中,既可以获取到在指定数据集合中的聚合计算结果,也可以获取到整个数据结合的聚合计算结果。像上面的例子,如果不用 Global Aggregation 就需要分开两次请求进行查询。
最后需要注意的是,Global Aggregation 只能作为最顶层的聚合,根据 Global Aggregation 的作用,作为子聚合是毫无意义的。
Nested Aggregation
Nested Aggregation 主要是针对于嵌套的文档数据。
例子如下:
PUT /index
{
"mappings": {
"product" : {
"properties" : {
"resellers" : {
"type" : "nested",
"properties" : {
"name" : { "type" : "text" },
"price" : { "type" : "double" }
}
}
}
}
}
}
发起聚合请求:
GET /_search
{
"query" : {
"match" : { "name" : "led tv" }
},
"aggs" : {
"resellers" : {
"nested" : {
"path" : "resellers"
},
"aggs" : {
"min_price" : { "min" : { "field" : "resellers.price" } }
}
}
}
}
响应结果:
{
...
"aggregations": {
"resellers": {
"doc_count": 0,
"min_price": {
"value": 350
}
}
}
}
参数 path 指定文档的嵌套域,而作为 Nested Aggregation 的子聚合的聚合计算将针对于嵌套的数据。
Reverse nested Aggregation
Reverse nested Aggregation 的作用主要是能够让聚合在作为 Nested Aggregation 子聚合的情况下,跳出嵌套类型,对根文档的数据作聚合计算。
有例子:
PUT /issues
{
"mappings": {
"issue" : {
"properties" : {
"tags" : { "type" : "keyword" },
"comments" : {
"type" : "nested",
"properties" : {
"username" : { "type" : "keyword" },
"comment" : { "type" : "text" }
}
}
}
}
}
}
聚合请求:
GET /issues/_search
{
"query": {
"match_all": {}
},
"aggs": {
"comments": {
"nested": {
"path": "comments"
},
"aggs": {
"top_usernames": {
"terms": {
"field": "comments.username"
},
"aggs": {
"comment_to_issue": {
"reverse_nested": {},
"aggs": {
"top_tags_per_comment": {
"terms": {
"field": "tags"
}
}
}
}
}
}
}
}
}
}
响应结果:
{
"aggregations": {
"comments": {
"doc_count": 1,
"top_usernames": {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets": [
{
"key": "username_1",
"doc_count": 1,
"comment_to_issue": {
"doc_count": 1,
"top_tags_per_comment": {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets": [
{
"key": "tag_1",
"doc_count": 1
}
...
]
}
}
}
...
]
}
}
}
}
在 Nested Aggregation 聚合下,Reverse nested Aggregation 的子聚合计算聚合的数据集是该嵌套文档的根文档。
根据 Reverse nested Aggregation 的作用,可以清楚这是一个专门作为 Nested Aggregation 子聚合的聚合计算,所以作为顶层聚合或者是作为非 Nested Aggregation 的子聚合是没意义的。
在默认情况下, Reverse nested Aggregation 将找到根文档,当然如果有多层嵌套,也可以通过 path 参数指定文档的路径。
Children Aggregation
Children Aggregation 针对的是父子文档关系的聚合。Children Aggregation 指定子文档,然后通过 Children Aggregation 的子聚合实现对子文档的相关聚合计算。
5.x 和 6.x 的父子文档实现有些许区别,但是对于 Children Aggregation 来说没有太大影响。
例子如下:
PUT child_example
{
"mappings": {
"_doc": {
"properties": {
"join": {
"type": "join",
"relations": {
"question": "answer"
}
}
}
}
}
}
发起聚合请求:
POST child_example/_search?size=0
{
"aggs": {
"top-tags": {
"terms": {
"field": "tags.keyword",
"size": 10
},
"aggs": {
"to-answers": {
"children": {
"type" : "answer"
},
"aggs": {
"top-names": {
"terms": {
"field": "owner.display_name.keyword",
"size": 10
}
}
}
}
}
}
}
}
参数 type 指定子文档。
官方示例中的响应结果过于长这里就不展示了。
Missing Aggregation
简单的来说,Missing Aggregation 就是对缺失指定域的文档进行聚合计算。
例子如下:
POST /sales/_search?size=0
{
"aggs" : {
"products_without_a_price" : {
"missing" : { "field" : "price" }
}
}
}
响应结果:
{
...
"aggregations" : {
"products_without_a_price" : {
"doc_count" : 00
}
}
}
Adjacency Matrix Aggregation
邻接矩阵聚合。请求提供一组有命名的过滤表达式,就像 Filters Aggreagation 那样。响应中的每个桶表示由过滤器集合组合成的邻接矩阵中的非空单元格。
假如有过滤器A,B,C,那么在响应中将会有如下桶:
相交的两个过滤器用符号 & 组合,例如 A&B,这个桶组合了过滤器A和过滤器B,对数据进行过滤。邻接矩阵被认为是一个对称矩阵,所以只会返回一半的结果,为了做到这一点,过滤器名称字符串进行排序,并且总是使用最小的一对作为 “&” 分隔符左边的值。具体来说就是只会返回 A&C 而不会返回 C&A 。
当然分隔符是可以通过设置参数 separator 指定的。
例子如下:
PUT /emails/_doc/_bulk?refresh
{ "index" : { "_id" : 1 } }
{ "accounts" : ["hillary", "sidney"]}
{ "index" : { "_id" : 2 } }
{ "accounts" : ["hillary", "donald"]}
{ "index" : { "_id" : 3 } }
{ "accounts" : ["vladimir", "donald"]}
GET emails/_search
{
"size": 0,
"aggs" : {
"interactions" : {
"adjacency_matrix" : {
"filters" : {
"grpA" : { "terms" : { "accounts" : ["hillary", "sidney"] }},
"grpB" : { "terms" : { "accounts" : ["donald", "mitt"] }},
"grpC" : { "terms" : { "accounts" : ["vladimir", "nigel"] }}
}
}
}
}
}
响应结果:
{
"took": 9,
"timed_out": false,
"_shards": ...,
"hits": ...,
"aggregations": {
"interactions": {
"buckets": [
{
"key":"grpA",
"doc_count": 2
},
{
"key":"grpA&grpB",
"doc_count": 1
},
{
"key":"grpB",
"doc_count": 2
},
{
"key":"grpB&grpC",
"doc_count": 1
},
{
"key":"grpC",
"doc_count": 1
}
]
}
}
}
N 个过滤在邻接矩阵聚合中会产生 N²/2 个桶。所以默认限制最大的过滤器数为100,这个设置可以在索引层通过设置参数 index.max_adjacency_matrix_filters 改变。
由于还没在实际场景中使用过该聚合,具体的使用场景,也就是有什么用,我也说不清楚,所以这里参考于官方文档 Usage 一节的内容:
On its own this aggregation can provide all of the data required to create an undirected weighted graph. However, when used with child aggregations such as a date_histogram the results can provide the additional levels of data required to perform dynamic network analysis where examining interactions over time becomes important.
Sampler Aggregation
抽样聚合。在 5.x 版本中还是一个实验性特性,在 6.x 后稳定,不同版本的 Sampler Aggregation 有些许区别,这里主要针对于 6.x 版本。
Sampler Aggregation 从搜索结果中抽取样本(如果没有搜索请求,就是从所有文档中抽样),让这些样本参与接下来的子聚合的计算。样本的抽取是先按照分数排序,然后从上往下抽取指定数量的文档。简单来说 Sampler Aggregation 限制参与聚合的文档的数量。
官方给出的用例是为了避免长尾数据对搜索的影响,长尾数据是指大量但是意义不大的数据。而用例的场景为在 StackOverflow 中检索数据,而 javascript 是一个很热门词,相对应的 kibana 是一个稀罕词,很多 javascript 相关的文档不包含于 kibana。然后进行了如下请求:
POST /stackoverflow/_search?size=0
{
"query": {
"query_string": {
"query": "tags:kibana OR tags:javascript"
}
},
"aggs": {
"sample": {
"sampler": {
"shard_size": 200
},
"aggs": {
"keywords": {
"significant_terms": {
"field": "tags",
"exclude": ["kibana", "javascript"]
}
}
}
}
}
}
响应结果:
{
...
"aggregations": {
"sample": {
"doc_count": 200, ①
"keywords": {
"doc_count": 200,
"bg_count": 650,
"buckets": [
{
"key": "elasticsearch",
"doc_count": 150,
"score": 1.078125,
"bg_count": 200
},
{
"key": "logstash",
"doc_count": 50,
"score": 0.5625,
"bg_count": 50
}
]
}
}
}
}
① 标识的 doc_count 指从总文档中抽取出的样本的数量,之后就像上面所说的,子聚合 significant_terms 对这些抽取出来的样本文档进行聚合计算。
请求中的 shard_size 参数指的是每个分片抽取的样本数量,默认为 100。
接下来看看,如果不采用样本聚合的话会怎么样:
POST /stackoverflow/_search?size=0
{
"query": {
"query_string": {
"query": "tags:kibana OR tags:javascript"
}
},
"aggs": {
"low_quality_keywords": {
"significant_terms": {
"field": "tags",
"size": 3,
"exclude":["kibana", "javascript"]
}
}
}
}
响应结果:
{
...
"aggregations": {
"low_quality_keywords": {
"doc_count": 600,
"bg_count": 650,
"buckets": [
{
"key": "angular",
"doc_count": 200,
"score": 0.02777,
"bg_count": 200
},
{
"key": "jquery",
"doc_count": 200,
"score": 0.02777,
"bg_count": 200
},
{
"key": "logstash",
"doc_count": 50,
"score": 0.0069,
"bg_count": 50
}
]
}
}
}
对于检索条件 tags:kibana OR tags:javascript 来说,同时拥有 kibana 和 javascript 的文档分数会更高,也是用户更感兴趣的文档,但是由于 javascript 相关的拥有大量文档,最终长尾数据影响了聚合结果。就像上面那样,angular 和 jquery 与 kibana 并不相关,但是因为文档数量多而影响了结果。
抽样聚合就是为了避免上述的问题,去除没意义但是会影响计算结果的数据,使响应结果更加高质量。
Diversified Sampler Aggregation
Diversified Sampler Aggregation 和 Sampler Aggreagtion 类似,进行抽样,控制子聚合计算的文档集合。而 Diversified Sampler Aggregation 除了能够抽取出指定数量的文档外,还可以限制一些同一个域具有重复值的文档的数量。
同样是上面 StackOverflow 的例子:
POST /stackoverflow/_search?size=0
{
"query": {
"query_string": {
"query": "tags:elasticsearch"
}
},
"aggs": {
"my_unbiased_sample": {
"diversified_sampler": {
"shard_size": 200,
"field" : "author" ①
},
"aggs": {
"keywords": {
"significant_terms": {
"field": "tags",
"exclude": ["elasticsearch"]
}
}
}
}
}
}
响应结果:
{
...
"aggregations": {
"my_unbiased_sample": {
"doc_count": 151,
"keywords": {
"doc_count": 151,
"bg_count": 650,
"buckets": [
{
"key": "kibana",
"doc_count": 150,
"score": 2.213,
"bg_count": 200
}
]
}
}
}
}
重点在于请求中 diversified_sampler 的参数 field ,该参数将指定需要进行重复值限制的域。
Diversified Sampler Aggregation 请求中有以下几个需要注意的参数选项:
- shard_size 和上述 Sampler Aggregation 的作用一致,决定每个分片抽样的数量。默认为 100 。
- max_docs_per_value 则是控制在抽样中,指定域是重复值的文档的数量。默认为 1 。
- execution_hint 就是前面 Terms Aggreagtions 的 Execution hint 一节中提到的,简单说就是计算重复值的一种方式。不同的 Execution hint 会影响到抽样中的去重,但是因为我还没有实践过,所以对于不同参数有什么不同的影响也是说不清楚清楚,直接参考官方文档:
The optional execution_hint setting can influence the management of the values used for de-duplication. Each option will hold up to shard_size values in memory while performing de-duplication but the type of value held can be controlled as follows:
• hold field values directly (map)
• hold ordinals of the field as determined by the Lucene index (global_ordinals)
• hold hashes of the field values - with potential for hash collisions (bytes_hash)
The default setting is to use global_ordinals if this information is available from the Lucene index and reverting to map if not. The bytes_hash setting may prove faster in some cases but introduces the possibility of false positives in de-duplication logic due to the possibility of hash collisions. Please note that Elasticsearch will ignore the choice of execution hint if it is not applicable and that there is no backward compatibility guarantee on these hints.
最后,需要注意的一点是,抽样去重是分片级的,不会跨分片进行去重。
作者:冰钟
原文链接:my.oschina.net/bingzhong/blog/1917...







 关于 LearnKu
关于 LearnKu




推荐文章: