
[转载]Elasticsearch 7.7 的异步搜索原理解析
Elasticsearch 7.7 版本带来一个新的特性,search 过程允许异步执行,客户端发送完 search 请求后,Elasticsearch 服务端给客户端返回一个 id,以后客户端拿这个 id 来获取 search进度,并且支持返回“部分”结果,这对于 UI 交互相关的查询请求非常友好,例如绘图过程可以逐步的显示出来。
基本用法
异步搜索使用起来非常简单,使用新的 API 即可,其余都和 _search 请求相同:
POST /_async_search返回结果中会有几个新的字段:
id:根据这个 id 获取后续的 query 进度。
is_partial:当 query 运行完毕后,该字段指示 query 在所有分片上全部执行成功,还是有失败的情况。
is_running:表示搜索过程是否还在运行中。
如果搜索很快就运行完,_async_search 的 Response 会包含完整的搜索结果,这里默认会等待1秒钟的时间,由参数 wait_for_completion_timeout 控制,超过这个时间的话,后续根据 id 获取搜索进度(或结果):
GET /_async_search/FmRldE8zREVEUzA2ZVpUeGs2ejJFUFEaMkZ5QTVrSTZSaVN3WlNFVmtlWHJsdzoxMDc=这里考虑的很周到,在开启了用户认证的情况下,每个人只能 GET 到自己提交的异步搜索结果,不会被其他人看到。搜索结果默认保存5天,通过 keep_alive 参数控制.
同样,你也可以手工 DELETE 这个异步搜索请求,如果搜索还在执行过程中,则会被取消。
DELETE /_async_search/FmRldE8zREVEUzA2ZVpUeGs2ejJFUFEaMkZ5QTVrSTZSaVN3WlNFVmtlWHJsdzoxMDc=实现原理
异步搜索的实现原理和同步搜索其实没有太大差别,数据节点执行搜索的过程是相同的,区别只是协调节点原本要等整个过程处理完毕后才返回给客户端,现在只等1秒(由wait_for_completion_timeout参数控制)。如果整个过程在1秒内完成,就给客户端返回最终结果,超过1秒后,就生成一个 id 返回给客户端。
数据节点像往常一样,对于某个分片的查询执行完之后返回一个分片级别完整的 Response,并不会计算一点返回一点,所以 Response 的单位还是分片级别的。不过 batched_reduce_size 默认被设置为 5,这在同步搜索中默认为 512,小一点的值可以给客户端尽早返回部分结果。
为了把查询结果保存5天,es 会建立一个名为 .async-search 的系统索引,将查询结果保存到其中,但是如果搜索过程在 wait_for_completion_timeout 超时时间内结束,所有的结果集会在当前请求中返回,不会保存到 .async-search 索引。
从 A 节点 发起搜索,从 B 节点 GET 怎么办
异步搜索返回一个 id,后续按照这个 id 获取进度,这个任务信息如何获取到?进度和结果集需要保存在哪个地方,是一个需要思考的问题,es 里会把他放到两个地方:
如果搜索过程还没有执行完,进度信息从协调节点的 taskmanager 里获取
如果搜索执行结束了,进度和结果集会保存到名为 .async-search 的索引里。
在第一种情况下,相当于进度信息保存在协调节点的内存里,这个信息只存在于整个集群的单个节点上,因此,当你异步搜索的请求发送到了 node1,而获取进度的请求发送到 node2(例如经过负载均衡器转发或客户端自己轮询),在 node2 如何获取到进度信息?答案是 node2 收到获取进度的 GET 请求后,会将请求 转发到 node1。那么 node2 怎么知道异步搜索请求发送到了 node1?实际上这些信息都保存在异步搜索请求返回的 id中,所以你现在知道了为什么他会这么长:
"id" : "FmRldE8zREVEUzA2ZVpUeGs2ejJFUFEaMkZ5QTVrSTZSaVN3WlNFVmtlWHJsdzoxMDc="这个 id 是一段 base64编码,他包含了以下信息:
docId 当搜索结果保存 .async-search 中时,该异步搜索任务结果在 .async-search 中的 docId
nodeId 接收 asyncsearch 搜索请求的节点的 nodeId
id 在 taskManager 中的任务 id
有了这些信息之后,GET 搜索进度的流程就比较清楚了:
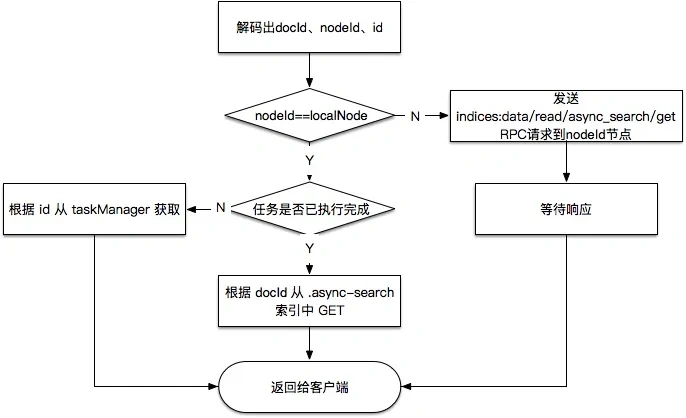
协调节点收到 GET /_async_search/id 请求后,根据 id 解码出上述三个信息,先判断执行_async_search 的节点是否本节点,如果不是本节点就直接根据解码出的 nodeId 给目标节点发送 RPC 请求来获取这个信息;如果是本节点,就根据任务 id 从自己的 taskManager 中获取,或者根据 docId 执行一个普通的 GET doc 请求,从 .async-search 索引中获取。
.async-search 索引的过期删除
索引 .async-search中的数据默认保存5天,不过大家都知道 es 里没有 TTL 的概念,那么数据的过期删除如何实现?实际上 es 内部会定期对该索引执行 DeleteByQuery:
DeleteByQueryRequest toDelete = new DeleteByQueryRequest(INDEX) .setQuery(QueryBuilders.rangeQuery(EXPIRATION_TIME_FIELD).lte(nowInMillis));当节点收到集群状态时,在 clusterChanged 中驱动周期线程执行清理,默认1小时执行一次,由参数 async_search.index_cleanup_interval 控制,该清理操作由 GENERIC 线程池执行,并且只会在 .async-search 索引的0号主分片所在的节点执行,不会在所有节点都执行清理工作。
参考
www.elastic.co/guide/en/elasticsea...
作者:张超
来源: Elasticsearch 原理与实践
原文链接:mp.weixin.qq.com/s/Y54fjpirHD3kpCh...






 关于 LearnKu
关于 LearnKu




推荐文章: