
[转载]58同城 Elasticsearch 应用及平台建设实践
导读:Elasticsearch 是一个分布式的搜索和分析引擎,可以用于全文检索、结构化检索和分析,并能将这三者结合起来。Elasticsearch 基于 Lucene 开发,现在是使用最广的开源搜索引擎之一。Elasticsearch 可以应用于在/离线日志流水、用户标签画像、数据库二级缓存、安全风控行为数据、图数据库索引、监控数据、Wiki 文档检索等应用场景。58同城有自己的主搜,而一些内部创新搜索业务和大规模的数据实时 OLAP ( On-Line Analytical Processing,联机分析处理 ) 则是使用 Elasticsearch。
本次分享的主题为58同城 Elasticsearch 应用及平台建设实践。主要内容包括:
- 集群优化治理
- 典型应用实践
- 自动化平台建设
- 后续规划
01 集群优化治理
1. 背景
早期 Elasticsearch 分布在58内的各个业务部门自主维护,但是随着 Elasticsearch 自身的功能加强,各业务团队使用 Elasticsearch 的数量越来越多、使用的业务场景越来越重要,于是由数据库部门对整个公司的 Elasticsearch 使用进行了收敛管理,在这个过程中数据库部门同学遇到了很多问题和挑战,具体如下:业务使用场景复杂多样;Elasticsearch 版本不统一;应用与 Elasticsearch 数据服务混合部署;缺乏有效监控;服务器硬件型号多样;索引接入无管控,找不到负责人;接入规范不统一,接入沟通成本高;无平台管理,手动 excel 维护集群信息。
除了上面这些问题,接管 Elasticsearch 后,还面临着服务性能方面的挑战:索引变红 ( 集群健康状态 )、索引写不进去、查询超时、内存 OOM、Master 不响应等。
在做分享之前,DataFun 的小伙伴给反馈了很多问题,这些问题很大一部分是与 Elasticsearch 集群的规划相关,这有很多和我们之前遇到的问题也是一样的。下面针对两个处理比较多的问题来分享。
2. 典型问题之一:Elasticsearch 集群的磁盘被打爆
造成磁盘被打爆有以下几种原因:
索引泛滥,索引接入无流程管控
索引无生命周期管理
索引分片数量不合理,单分片过大
日志类索引未按天等细粒度划分,单索引过大
多集群复用同一服务器节点
磁盘容量大小不一
这些问题比较基础,其实也反映出早期在使用 Elasticsearch 时没有很好的规划。针对上面的各种问题,总结了如下几点实践经验:
集群管控收敛账号权限,限制每个账号操作索引的范围。避免各个部门或业务随意复用集群,比如不通过系统申请直接将其它各种日志或业务数据直接 Load 进 Elasticsearch,造成索引泛滥无法治理。
索引生命周期管理。不管线上数据还是离线数据,应该有个消亡的过程。比如梳理过程甚至发现3年前的数据还存在,这极大的浪费了磁盘空间。
合理的分片数量规划。分片数量的规划其实和我们的数据量有很密切的关系的。比如节点的个数是多少、磁盘的空间是多少,我们建议尽量控制单个分片数量在 100G 以内,避免单分片过大在均衡时将磁盘打爆。
日志类的索引,避免单个过大,按照天划分是比较好的解决方案。如果按照天划分索引仍然很大,这个时候就需要按小时更小粒度的划分规则。
不同集群复用相同的服务器分区。由于 Elasticsearch 有自己的警戒水位线,之间会互相影响,很容易导致磁盘空间触发达到上限问题。
3. 典型问题之二:Elasticsearch 集群写入变慢
Elasticsearch 集群写入变慢需要考虑以下几个问题:
索引梳理,是否所有信息都要写入?
分片数量是否合理?
业务需求是否需要多副本?
Refresh 时间是否可以更大?
Logstash 处理吞吐是否达到瓶颈?
Translog 刷新策略是否要优化?
磁盘硬件 IO 是否太差?
针对上面这几个问题我们的实践经验是:
减少不必要的写入。例如减少没有必要的大文本类的写入,因为这些大文本会耗更多的 IO。
合理设置分片数量。分片数量不是越多越好,分片越多会导致写入变慢。
多副本会极大的影响写入吞吐。在 Elasticsearch 的写入机制里,Primary 要等待所有 Replica 写完之后才能返回给客户端。
对于日志类的索引没有必要秒级刷新。大家可能都使用了默认配置刷新时间,其实调整为 5 秒、10 秒也是可以接受的。目前很多日志类的我们设置为 60 秒。
Logstash 有吞吐瓶颈。之前测评在某一场景下,它的吞吐量也就 1-2 万左右。业内还有一些开源的工具替代 Logstash,包括一些自研的程序,可以极大的提高写入的吞吐。
明确服务器用的是 SSD 还是普通的 SATA 机械盘。ssd 的读写速度会比普通的 SATA 机械盘快。目前针对一些业务数据我们采用冷热分离策略,新数据库写入 SSD 磁盘,早期的数据会自动均衡到 SATA 机械盘。
4. 开发规范
针对这些影响业务稳定性的问题,我们内部制定了相应的规范约束:
日志类应用:
提供容量与吞吐量预估
注:在新业务接入时,我们要求业务方提供当前业务的容量和吞吐量的预估值 ( 例如:每天的增量数据有多少条、保留的时间是多少 )。
提供静态 mapping 结构
注:包括对日志类的业务,我们也强烈建议使用静态 mapping。
统一接入大数据部门 Kafka 集群,并提供 topic 和 ClientId
提供 Logstash filter 过滤规则配置
索引配置,默认 5 分片 1 副本 ( 可调整 )
数据保留策略,建议不超过 30 天
索引按天划分,命名规则建议为:前缀+日期时间戳,如xxx-2020-02-01
注:这里还是强烈建议日志类索引按照天划分。
禁止私自接入新索引,接入账号权限限制匹配特定索引前缀
非日志类应用:
这类多是数据检索类的服务。
提供容量与吞吐量预估
提供业务类型评估,线上一级核心业务优先接入公司主搜服务
注:因为这会涉及公司的商业搜索策略。
重要业务独享集群,非核心业务复用公共集群
注:重要的业务要保证业务的可靠性、稳定性。
提供静态mapping结构
索引配置,默认5分片2副本
注:根据实际业务进行动态调整。
禁止私自接入新索引,接入账号权限限制匹配特定索引前缀
5. Elasticsearch服务架构
在整合所有Elasticsearch之后,我们统一了Elasticsearch的服务架构:
该架构有以下几个特点:
Elasticsearch的每一个节点角色都是独立的。我们的Master节点和Data节点不会复用,对于大规模集群也会额外增加client节点。
Elasticsearch的版本统一升级到6.8以上。因为Elasticsearch在6.8版本开始提供基于角色的安全认证,这对我们的索引治理和管控来说是非常重要的,而之前我们有不少Elasticsearch是在裸奔,没有任何的安全限制。
公共的IK插件。现在的分词插件目前还是使用的默认的IK插件。
冷热数据分离。我们根据索引的业务场景,配置不同类型的数据节点,配合我们的索引管理策略,在低负载的时候 ( 晚上或某个时间点 ),自动调整索引的配置,让它进行自动迁移。
02 典型应用实践
1. ELKB简介
在介绍我们典型的应用实践之前,我们先再介绍 ELKB。
ELKB 是一套日志管理方案,它是 Elasticsearch、Logstash、Kibana、Beats 服务的简称。Elasticsearch 用于存储数据,并提供搜索和分析;Logstash 用于数据收集及转换管道,可扩展的插件;Kibana 用于对存储在Elasticsearch 中的数据进行可视化展示;Beats 用于多类型数据采集器。
ELKB 的架构分为三层:数据提取层、数据的存储层、数据展示层。ELK B将数据的提取、存储、展示做成套件,这是它比较优势的地方。
2. 应用实践之一:58 实时日志平台
早期阶段:
58 内部有好多套技术方案实践,该架构是5年前系统运维部同学维护的一套日志收集平台,有两条业务线在使用。这个版本当时比较低,它通过Logstash抓取日志,但是Logstash这块非常消耗资源,经常出现一些稳定性的问题。

现在阶段:
目前我们在公司主流的日志平台主要是这种:

工作流程:
收集:日志收集使用大数据部门的Flume进行抓取
存储:数据收集完后会存储到公司统一的Kafka集群;
展示:我们做了日志管理平台-飞流。另外因为Kafka存储的数据时间有限制,我们将Kafka的数据写入到线下的KV存储系统或者一些检索系统中。监控报警系统可以提供一定的监控。
改进阶段:
接着也就演变到了下面这种新的日志平台:
收集:在数据抓取层除了使用Flume之外,我们增加了Filebeat等套件。
缓存:抓取的数据仍通过公司的Kafka集群进行缓存
过滤转换订阅消费:通过Kafka之后的下游消费我们使用Logstash,因为Logstash的单节点的吞吐量有性能瓶颈,我们通过部署多套,并让多个Logstash节点进行消费。另外一种就是hangout。hangout是携程一个开源的类似Logstash的Kafka消费组件,它在部分场景下的吞吐量不错
存储检索:使用Elasticsearch
展示:我们还自研了一些应用程序,通过Kibana直接给数据分析师、用研员提供服务。另外部分业务也依靠Elasticsearch做趋势或者预警方面的功能监控报警平台,以及一些日志管理系统,用于满足自己的业务需求。
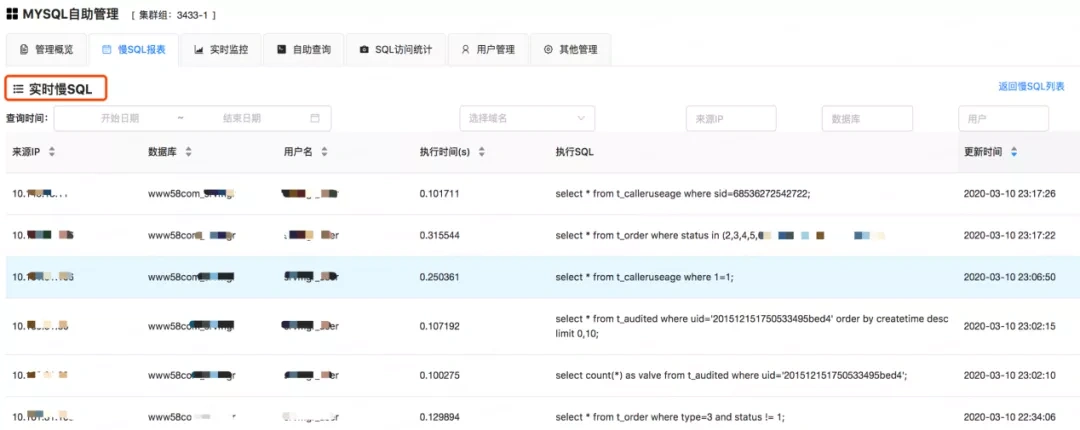
3. 应用实践之二:MySQL实时慢日志
早期业内大家做MySQL的慢日志系统大都是获取上一整天的慢日志,进行统一分析,然后生成上一天的慢日志报表。这种方式有一定的滞后性,如果业务调整SQL或者新发布了一个功能想看实时的性能状况,这种需求是满足不了的。开发人员需要看到数据库实时的慢日志,以方便更快的进行性能诊断。我们使用ELKB技术栈来实现:
收集:采集层使用公司的 agent 来管理每个 MySQL 服务器节点上的Filebeat,比如实现对每个 MySQL 节点配置 Filebeat,并进行初始化、启停等管控。
缓存:数据收集完成后,上报汇总到公司的Kafka集群。
过滤:配置 Logstash 过滤分析节点,因为 MySQL 慢日志格式还是比较复杂,这里面要做一些分析过滤、切割转换等相关操作。
存储:最终统一存入到 Elasticsearch 中
展示:目前我们支持在 58 云 DB 平台【内部的私有云数据库平台】上直接查看。我们也可以通过 Kibana 提供的统计工具进行趋势分析、运维报警等。
目前给开发人员提供的用户端,通过页面可以实时看到自己的 MySQL,从收集到 MySQL 到展示,目前可以做到 5 秒以内展示。
4. 总结
上面介绍的是58同城内部两个主要的应用实践,目前数据库团队已经收敛了整个公司30+套各种业务的Elasticsearch集群、300多个节点,服务器接近200台,我们的管理维护还有不少的工作要做。
03 平台化建设
从去年开始,我们启动了Elasticsearch平台化建设,一是面向用户端提高开发接入Elasticsearch的效率,另外就是面向DBA管理端,可以对Elasticsearch集群进行高效运维及索引治理等。
58云DB平台Elasticsearch功能架构图如下:
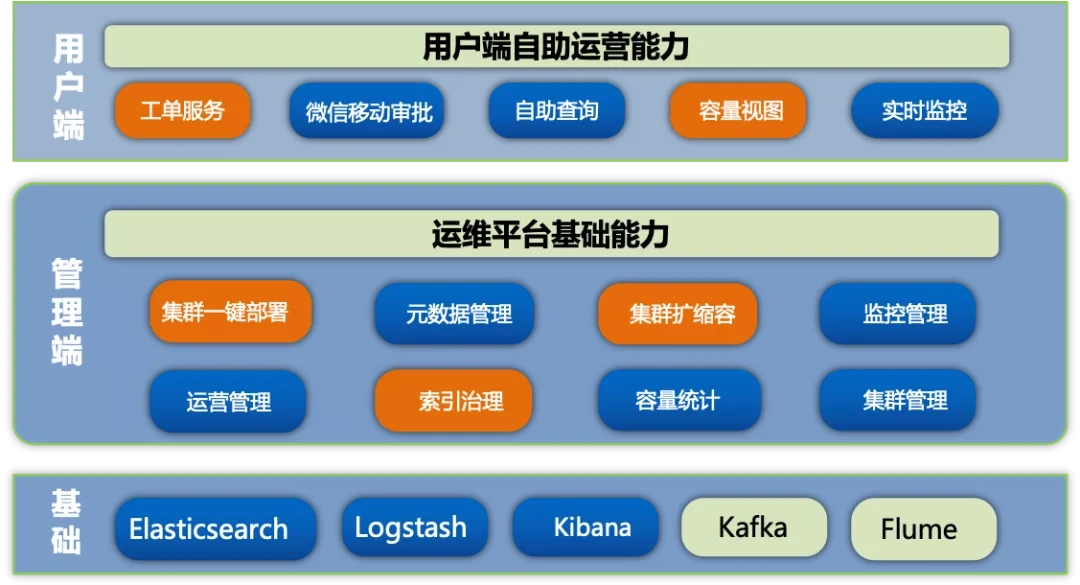
1. 用户端
针对用户端,我们把Elasticsearch开放给开发人员、数据运营、数据分析师等,使他们能够对Elasticsearch的数据进行基本的查询,包括数据统计、分析报表、 查看Elasticsearch的状态等。
- 集群负责人可以从管理界面上看到自己名下的集群列表、Kibana地址、集群容量、操作申请等。
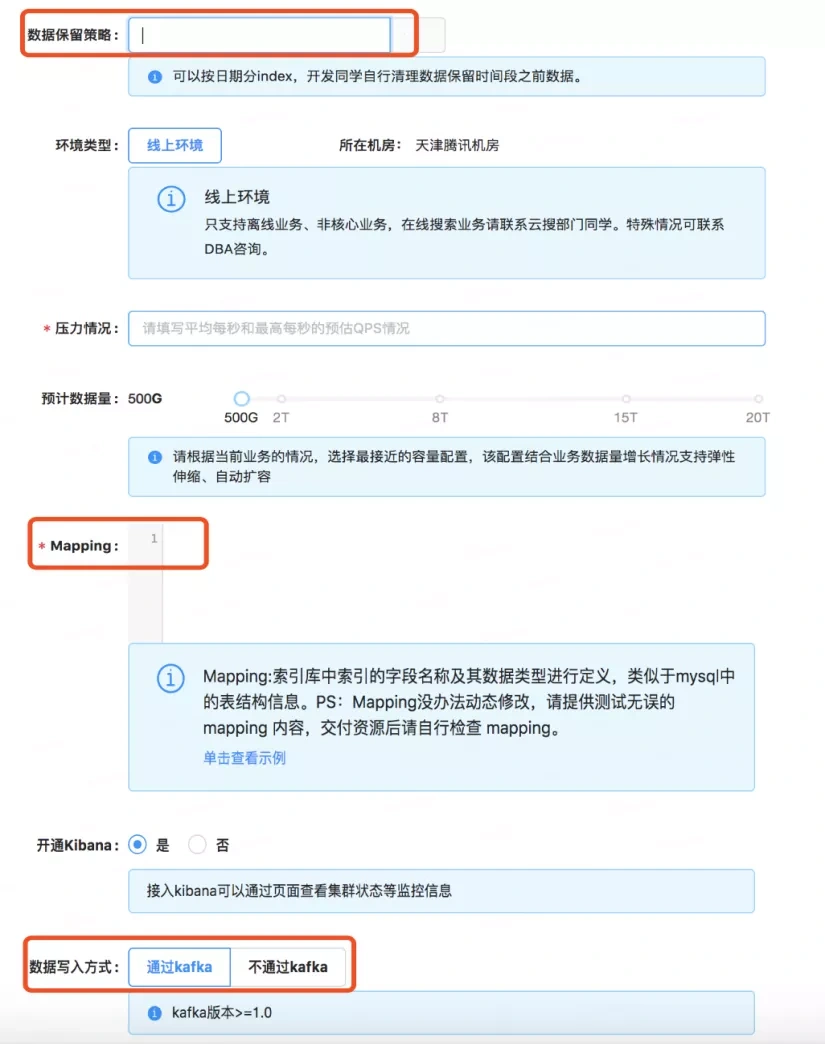
- 这个界面是索引申请界面。所有接入者通过标准化的方式、规范化的流程来完成需求提交。每一个索引的接入必须包括数据的保留策略、mapping、数据写入方式等。
2. 管理端
在管理端,我们实现了一键部署Elasticsearch集群。由于Elasticsearch是分布式的,部署的线路是比较长的,它需要多节点、不同的角色,包括监控、Logstash、Filebeat等相关的管理都是支持的。
- 从管理界面上可以看到哪个ip地址上运行着哪个集群、它的角色是什么。
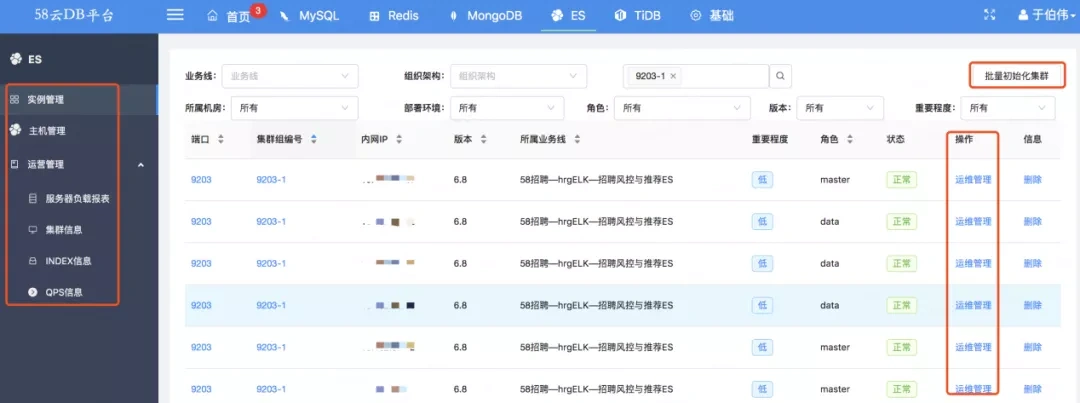
- 一键自动化部署。
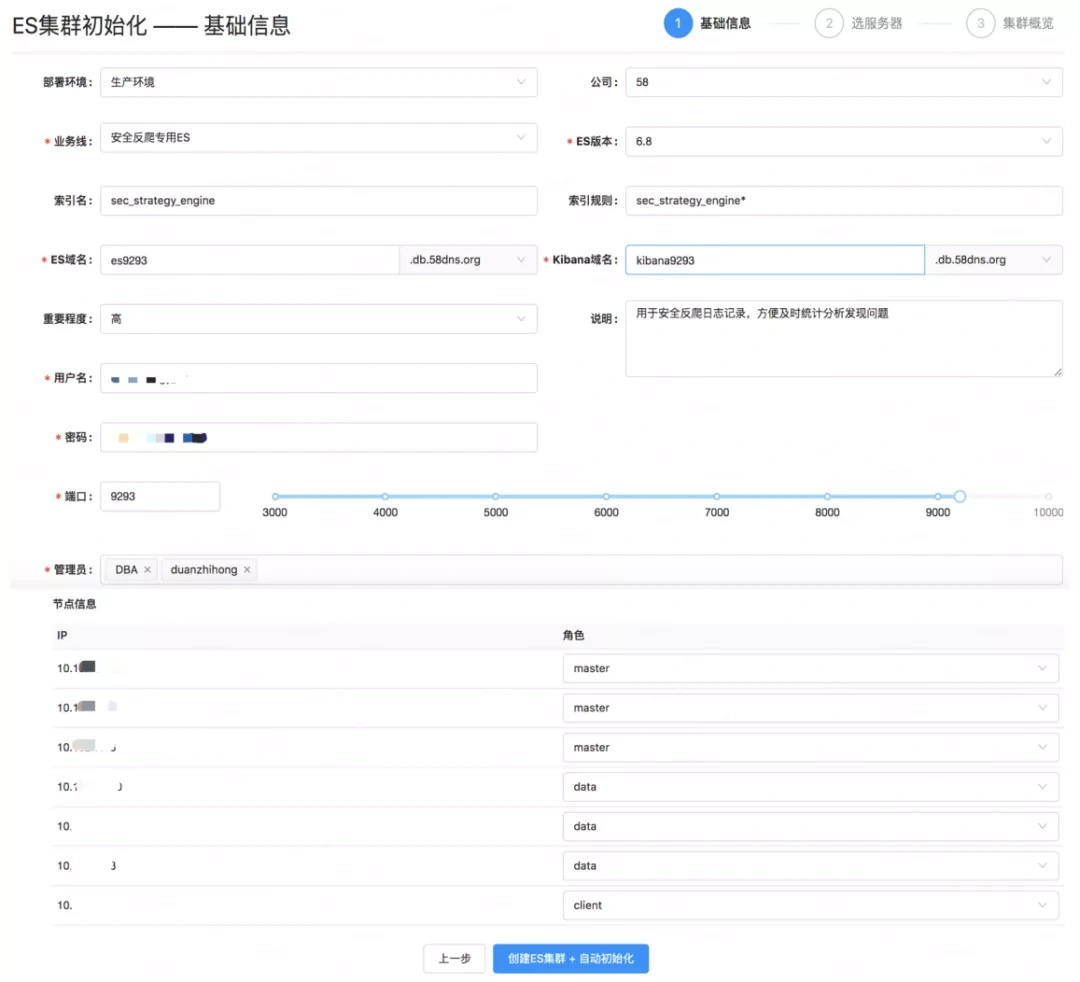
3. 索引治理
索引治理后续会做一些索引的生命周期管理,现在的管理我们最多的还是依赖脚本,后面索引的工作,我们希望都放到平台上来,都要有相关的操作记录。
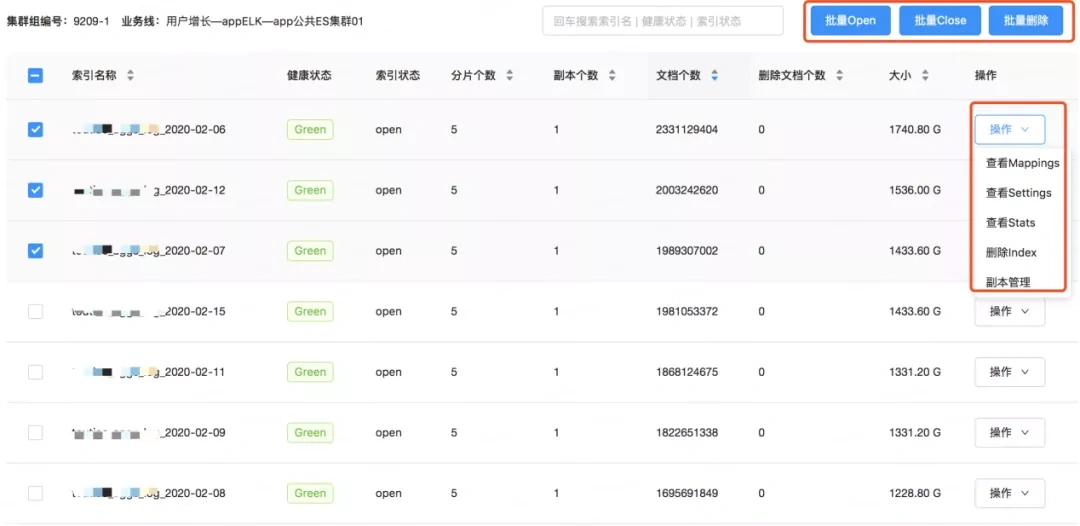
- 索引的监控
对于服务端目前使用的是 Zabbix+ Grafana的方式。我们开发了一套程序。将所有集群的监控指标打入到其中一套Elasticsearch集群中去,然后Grafana基于Elasticsearch做了图表的展示,再通过Zabbix进行一些系统的报警。
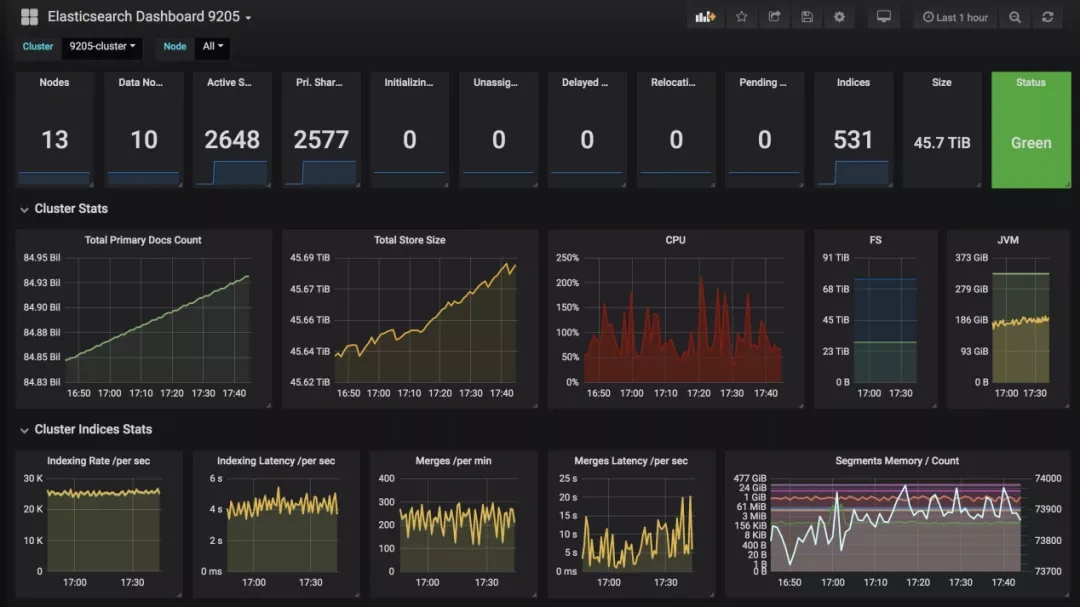
用户端,可以通过Kibana可以看到索引index的速度、延迟等信息。
04 后续规划
1. 版本升级
Elasticsearch 7.X,在Elasticsearch 7.X版本在性能优化上做了很多东西,包括:查询的相关性、对内存的管控方面。但是它同样存在一个问题,Elasticsearch版本不向下兼容,比如6.x版本升级到7.x版本,它的变化会比较大。
2. 集群智能诊断
集群功能越来越多,目前集群出了问题还是依赖运维人员手动发现。我们希望通过规则或者自动分析等手段,实现故障的自动化处理。
3. 私有云探索
接到Elasticsearch业务需求,我们首先要分析它的业务模型:是搜索的还是日志流水的?不同的用途对硬件的消耗差别是很大的,而服务器并不是高度的契合业务配置。在这个方面是有非常多的资源浪费,我们希望通过云模式,能够减少资源浪费,提高资源的利用率。
05 问答环节
1. Elasticsearch数据如何与hadoop大数据平台数据仓库同步?
答:Hadoop或hive数据可以通过官方的相关组件,也可以通过自己写程序进行同步。
2. Elasticsearch日志应用中,怎么定义日志格式,有些后台日志情况复杂,比如except崩溃的,怎么处理这种后台日志问题?
答:关于日志格式可以看下Filebeat,Filebeat在收集日志的时候有多行合并功能,从Kafka到Logstash可以定义自己的过滤规则,这样可以很容易的把问题解决掉。
3. MySQL数据如何导入到Elasticsearch,并保持实时同步?
这是一个比较大的主题,从MySQL到Elasticsearch这里考虑的规则还是比较多的。如:单表导入到单索引、多表导入到一个Elasticsearch索引、单表导入多个索引,这些都是不一样的。业内做MySQL到Elasticsearch的同步的方案比较多,主流的有如下几种:
简单粗暴的由业务层双写,即写完MySQL之后直接写Elasticsearch,当然这样双写可能无法保证数据的一致性,有些公司对异常有补偿机制:如果写入ES失败,先把写失败的数据记录下来,通过独立后端程序进行异常的数据修复。
一些开源的工具。比如阿里开源的多数据源dataX,它的设计原理是直接到MySQL中查询数据,它高度依赖一条记录的过期时间,大于过期时间就将数据取出来写到Elasticsearch中去,这个实时性依赖于程序多久刷新一次,但是如果数据删除了,是无法感知到的。
直接解析MySQL的binlog。阿里也有这样的开源工具canal。它的实现原理就是模拟一个MySQL的从库,它订阅所有主库的变更,当MySQL数据变化时,它将解析的变更可以放到Kafka中去,Kafka下游可以消费后写入Elasticsearch,也可以不经过Kafka直接解析出来写入Elasticsearch。但canal也有个问题。它单节点处理能力受限。当MySQL主库写入稍微多一些的情况下,这时候canal解析速度跟不上,导致大量延迟,如果主库的持续的写入量大,canal会一直延迟,而且延迟越来越大,同时会出现很多问题。
4. Elasticsearch如何实现高效的二级索引?
答:类似于MySQL的回表查询模式,先将所有待查询的数据同步到Elasticsearch中,同步时带上相关的记录id,在Elasticsearch完成查询后,再用这些id去相关的MySQL或HBASE进行查询返回完整数据。
作者:于伯伟
来源:DataFunTalk
原文链接:mp.weixin.qq.com/s/zZziVBwxGBowYgx...





 关于 LearnKu
关于 LearnKu




推荐文章: