OpenAI Sora
访问源站OpenAI Sora:文本图像视频生成AI模型功能详解
34137187 浏览
收藏
2025-10-21
34137187 浏览
收藏
2025-10-21
作品展示
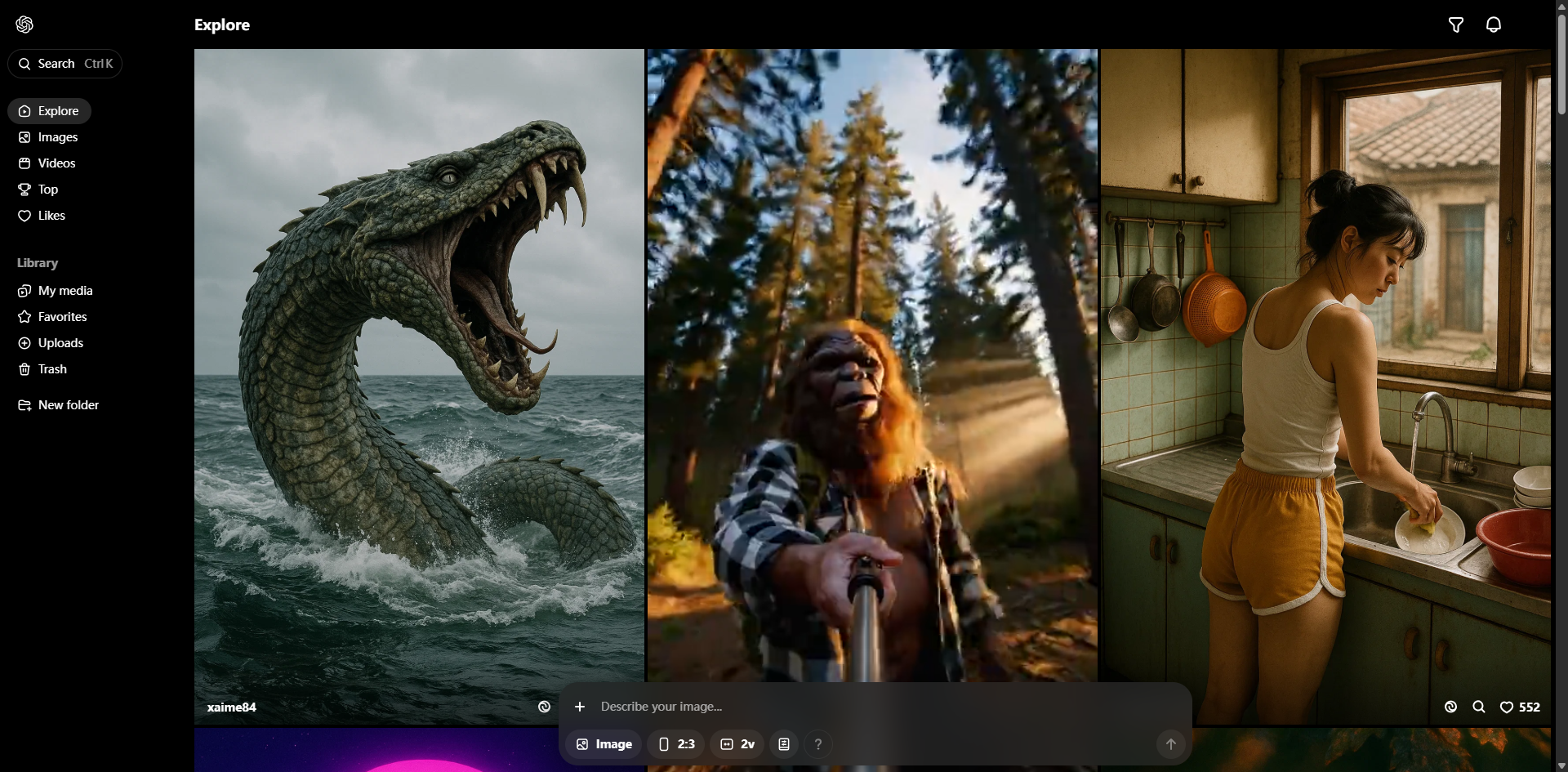
项目介绍
Sora是由OpenAI开发的AI视频生成模型,能够基于文本、图像或现有视频创建逼真且富有想象力的场景。该模型旨在理解和模拟动态物理世界,生成最长一分钟的视频,同时保持视觉质量和用户提示的准确性。
核心功能:
- 文本到视频生成:根据描述性文本指令生成视频内容
- 图像到视频生成:将静态图像动画化处理
- 视频扩展与帧填补:扩展现有视频时长,补充缺失帧
- 复杂场景生成:支持多角色、特定运动类型和精确细节
- 一致性保持:在多个镜头中维持角色和视觉风格统一
技术架构:采用扩散模型与变换器架构,类似于GPT模型,具备深度语言理解能力,能够精准解读用户提示。
主要应用场景:
- 创建电影场景和电影预告片
- 生成奇幻场景和特定艺术风格动画
- 可视化抽象概念
- 静态图像动画化处理
- 视频素材扩展与编辑
使用方式:用户通过提供文本指令(提示)生成视频,或对现有图像/视频进行处理。该模型目前月访问量达3410万,主要服务于视觉艺术家、设计师、电影制作人等创意专业人士。
发展目标:作为实现AGI(通用人工智能)的重要一步,Sora旨在成为理解和模拟真实世界的基础模型。
作品数据统计
深度洞察访问数据,全面分析用户行为
6619.2万
月访问量
27.4%
跳出率
14.6
页面/访问
14.4m
访问时长
N/A
全球排名
N/A
国内排名
访问趋势
(最近三个月)08月
4503.1万
09月
3413.7万
10月
6619.2万
流量来源
社交媒体
1.5%
付费推广
0.3%
邮件
0.2%
外部链接
7.6%
搜索引擎
9.5%
直接访问
81%
广告

热门推荐
TTSMaker
TTSMaker:免费在线文本转语音工具,支持AI语音与多语言
1686580
34
Mathos | AI Math Solver & Calculator
Mathos AI:免费AI数学求解器与学习助手
929342
0
ZeroGPT
ZeroGPT:多功能AI内容检测与写作辅助工具详解
23080328
1
获取最新作品资讯
订阅我们的邮件通知,第一时间了解优秀作品更新、设计趋势和创意灵感
我们承诺不会发送垃圾邮件,您可以随时取消订阅