
Laravel 队列实战教程:构建一个简单的统计应用

几年来,我一直在使用Laravel任务调度和队列。刚开始使用它们时,我感到很难受,我无法理解这些概念,我们构建高度依赖它们的web应用程序的方式似乎有些奇怪,即使不是太复杂。有天我突然焕然大悟,一切都开始变得清晰。希望同样的事情也会发生在您身上,您会开始想知道这些年来您是如何在不了解其原理的情况下使用它的。
据我所知,学习任务调度和队列(以Laravel为例)不能深入了解其原理的主要原因并不在于其有多复杂或有多新颖,而关键问题在于我们在网上查找的大部分学习资料要么过于理论,要么缺乏我们需要的简单实例。
这本教程是写给过去的我,这是我初学这些概念时希望拥有的教程。我喜欢用例子来解释任何复杂的概念。我们将构建一个简单的分析应用程序,我们会从一个基础的版本开始,如果如果您是该应用程序的唯一用户,则以您构建的应用程序开始,然后我们将发现应用程序所暴露出来的缺点,我们会通过任务调度和队列去改善并解决这些缺点。
应用说明
这是一个基础的应用程序(将其命名为basic-analytics-v01)。这个应用程序将追踪我们网址收到的流量。
我们在构建该应用程序的同时,我们可能希望向其他用户开发该应用程序,因此我们需要将用户数据分离开,并且不需要太多工作就可以将其集成到现有网站中。
简而言之,每当用户访问页面时,网站都会向我们的分析程序发送POST请求,我们通过减去两个连续发送的POST请求时间戳来计算在每个页面上所花费的时间。
basic-analytics-v01
我们将保证这个应用程序足够简单(至少在第一个版本中)。
让我们将这些请求数据存储在数据库中,我们只需要一个方法和一个控制器(是的,我们现在将所以内容都放入一个控制器中)。
首先,让我们创建两个主要的models及各自的迁移文件。
Tracker:每个用户进入网站都会分配一个唯一的tracker,现在,我们只需要确保tracker的ID是唯一且有效的(它存储于数据库中)Hit:每个POST请求都将存储为一个“Hit”
controller代码如下所示:
class TrackingController extends Controller
{
public function track($tracker_public_id, Request $request)
{
$tracker = Tracker::where('public_id', $tracker_public_id)->first();
if ($tracker) {
$url = $request->get('url');
$hit = Hit::create(['tracker_id' => $tracker->id, 'url' => $url]);
$previousHit = Hit::where('tracker_id', $tracker->id)->orderBy('id', 'desc')->skip(1)->first();
if ($previousHit) {
$previousHit->seconds = $hit->created_at->diffInSeconds($previousHit->created_at);
$previousHit->save();
return $previousHit->seconds;
}
return 0;
}
return -1;
}
}
这里要记住,我们简化来很多代码,只留下有助于说明本文的简单用例。
如您所知,此代码没有任何问题,特别是你要将其运用于一个小型的个人网站。
但是,让我们想象可能存在一些特殊情况,这个代码还不够完善,可能会报错甚至使网站无法正常运行。
反应时间
让我们设想一下,由于某种原因,发送这些请求的脚本需要等待并确认请求已收到。
当我通过Postman在本地发送请求来测试这一点时,我得到的结果如下:
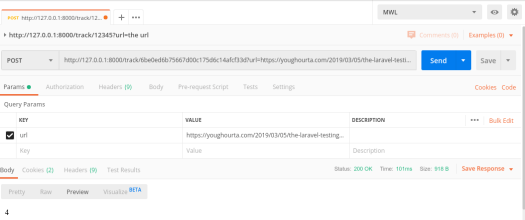
100ms是一段相当长的时间,即使我们在控制器操作中没有做太多处理。假设我们要做的不仅仅是这个简单的处理,并且我们需要执行多个数据库查询,甚至需要与第三方API对话,我们将阻塞发送请求的脚本(因此,我们可能会阻塞正在执行脚本的页面),直到我们完成处理。
并发请求数
无论您是在本地运行Laravel应用程序,还是在生产服务器上运行,您随时可以处理的请求数量总是有限制的。
如果您使用的是本地开发服务器,并使用php artisan serve为您的Laravel应用程序提供服务,您会注意到该服务器一次只能处理一个请求。
如果我们像在代码中所做的那样同步执行代码,这意味着我们将更频繁地达到此限制,因为我们使Web服务器保持繁忙,并且我们会注意到太多的请求只是超时。这个问题的一个解决方案是尽快释放连接。
数据丢失
在读取当前代码时不容易想到的一个问题是,如果失败(例如,当我们尝试执行代码时无法访问数据库,或者如果我们有引发异常的错误),我们就无法存储请求并重试。
现在让我们看看作业和队列的使用将如何帮助我们解决所有这些问题:
将作业推送到队列
首先,让我们来谈谈什么是队列和作业。
简而言之,作业就是我们想要执行的一段代码(例如一个方法)。我们把它放在一个队列中,以推迟它的执行,并将它委托给“其他东西”。
举一个真实世界的例子,当你去快餐连锁店吃饭时,接待员不会为你准备并送到你手中,而是确保你的订单被(正确地)接受,然后将剩余的工作“委托”给其他人。
这背后的原因是,接待员不需要让你排队等待,直到你拿到订单,而是只做最少和必要的工作,然后继续下一个订单(尽可能多地并行服务)。我们希望用我们的代码实现同样的功能。
因此,在我们的代码中,我们只想确保已收到POST请求,然后将其余的工作委托给队列应用程序去完成。
其中一种方法是将需要委托执行的代码放在闭包中,然后将其写在dispatch函数中,代表将其分发给队列:
dispatch(function () use ($parameters) {
// your code here
});
但是我建议您将创建一个专门处理队列的类class,将需要执行的代码写入该类。
首先,我们需要执行以下命令来创建类:
php artisan make:job TrackHitJob
此命令将生成以下类:
App\Jobs\TrackHitJob
现在我们将TrackingController中的track方法移至新创建的TrackHitJob类中的handle方法中。handle方法如下所示:
public function handle()
{
$tracker = Tracker::where('public_id', $tracker_public_id)->first();
if ($tracker) {
$url = $request->get('url');
$hit = Hit::create(['tracker_id' => $tracker->id, 'url' => $url]);
$previousHit = Hit::where('tracker_id', $tracker->id)->orderBy('id', 'desc')->skip(1)->first();
if ($previousHit) {
$previousHit->seconds = $hit->created_at->diffInSeconds($previousHit->created_at);
$previousHit->save();
return $previousHit->seconds;
}
return 0;
}
return -1;
}
PS:别忘了导入Tracker和Hit模型以及Request类
但是我们如何将参数(tracker的ID以及请求本身)传递给队列类代码呢?好吧,我们将它们传递给类的构造函数,然后handle方法可以像这样获取参数:
namespace App\Jobs;
use Illuminate\Bus\Queueable;
use Illuminate\Contracts\Queue\ShouldQueue;
use Illuminate\Foundation\Bus\Dispatchable;
use Illuminate\Queue\InteractsWithQueue;
use Illuminate\Queue\SerializesModels;
use Illuminate\Http\Request;
use App\Tracker;
use App\Hit;
class TrackHitJob implements ShouldQueue
{
use Dispatchable, InteractsWithQueue, Queueable, SerializesModels;
private $trackerPublicID;
private $url;
public function __construct($tracker_public_id, Request $request)
{
$this->trackerPublicID = $tracker_public_id;
$this->url = $request->get('url');
}
public function handle()
{
$tracker = Tracker::where('public_id', $this->trackerPublicID)->first();
if ($tracker) {
$hit = Hit::create(['tracker_id' => $tracker->id, 'url' => $this->url]);
$previousHit = Hit::where('tracker_id', $tracker->id)->orderBy('id', 'desc')->skip(1)->first();
if ($previousHit) {
$previousHit->seconds = $hit->created_at->diffInSeconds($previousHit->created_at);
$previousHit->save();
return $previousHit->seconds;
}
return 0;
}
return -1;
}
}
现在,我们每次接受到新的hit值,我们都需要将其分发到新的队列中
我们可以按照以下代码:
namespace App\Http\Controllers;
use Illuminate\Http\Request;
use App\Jobs\TrackHitJob;
class TrackingController extends Controller
{
public function track($tracker_public_id, Request $request)
{
TrackHitJob::dispatch($tracker_public_id, $request);
}
}
看看我们的控制器变得非常简洁明白。
如果您像刚开始时那样尝试发送POST请求,我们会发现没有任何变化,我们仍然会看到hits表中数据变化,并且请求仍然存在且与上次请求时间基本相同(~100ms)
那么,这是怎么回事?我们真的分发队列了吗?
队列连接
如果你打开.env文件,您会发现我们有一个名为QUEQU_CONNECTION的变量,设置为sync
QUEUE_CONNECTION=sync
这意味着我们在处理所有分发的任务队列时,正在进行同步处理。
因此,如果我们想要更好地使用队列的功能,我们需要将队列连接修改为其他的连接方式。换句话说,我们需要更换一种处理方式,可以使任务队列能够以排队的方式进行。
可以选择多种连接方式。如果您查看config/queue.php文件,您会注意到Laravel支持的多个连接方式(“sync”, “database”, “beanstalkd”, “sqs”, “redis”)。
由于我们只是刚刚开始使用队列和作业,因此我们避免使用任何需要第三方服务(beanstalkd和sqs)或开发计算机中不一定有的应用程序(redis)的队列连接。我们将用database方式进行连接。
因此,每次有新的任务队列需要处理时,它将存储在数据库中(专用表中)。然后再连接获取并执行相关任务队列。
PS:如果您使用的是本地开发服务器,记得要重启它,否则不会重新加载.env文件所做的更改。
QUEUE_CONNECTION=database
在尝试发送POST请求之前,我们需要创建一个表用于存储队列数据。值得庆幸的是,Laravel为我们提供了一个现成的生成该表迁移的命令
php artisan queue:table
执行此命令后(并因此创建迁移)后,我们需要运行执行迁移。
php artisan migrate

现在,如果我们再发送一次POST请求时,我们会注意到以下内容:
- 响应时间变短(因为我们不再同步处理请求)
- 我们可以在
jobs表中查看创建了新的数据
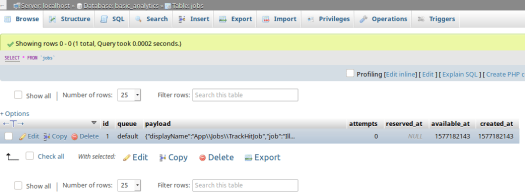
- 但
hits表中没有创建新的数据
我们没有在hits表中看到任何数据更新,因为我们没有执行进程来运行相关的任务队列。为了使用队列,我们需要执行以下命令:
php artisan queue:work

➜ basic-analytics-v01 git:(master) ✗ php artisan queue:work
[2019-12-24 10:25:16][1] Processing: App\Jobs\TrackHitJob
[2019-12-24 10:25:16][1] Processed: App\Jobs\TrackHitJob
[2019-12-24 10:25:16][2] Processing: App\Jobs\TrackHitJob
[2019-12-24 10:25:16][2] Processed: App\Jobs\TrackHitJob
[2019-12-24 10:25:16][3] Processing: App\Jobs\TrackHitJob
[2019-12-24 10:25:16][3] Processed: App\Jobs\TrackHitJob
[2019-12-24 10:25:16][4] Processing: App\Jobs\TrackHitJob
[2019-12-24 10:25:16][4] Processed: App\Jobs\TrackHitJob
[2019-12-24 10:25:16][5] Processing: App\Jobs\TrackHitJob
[2019-12-24 10:25:16][5] Processed: App\Jobs\TrackHitJob
请注意,该命令不会退出,它将继续等待新的任务队列并进行处理。
如果您想知道如何在线上生产服务器执行此命令,以及在注销服务器后保持该命令继续正常运行,请不要担心,我们稍后将详细讨论这一点。
现在,如果您返回数据库查看jobs表,你会发现它是一张空表,因为它已经处理完所有任务队列了。
并行使用多个作业
在了解了如何分发任务队列并异步处理它们之后(即:我们不需要等待任务队列完成),让我们转到使用任务队列的第二个原因:并行性。
如果您到目前为止一直在认真地关注,您会注意到,我们分发的任务队列一次只能处理一个任务队列。
解决方案非常简单,只需打开一个新的终端页面并执行相同的命令php artisan queue:work,下次有多个POST请求发送到您的应用程序(即当您有多个任务队列需要执行),您会注意到两个终端的进程都在执行任务队列,这意味着我们正在并行处理它们,这意味着您拥有的进程越多,清空队列的速度就越快。
同样,如果您想知道如何在线上生产服务器上执行此操作,请放心,我们稍后将进行介绍。
处理执行失败的队列
现在,假设您将一些新代码推送到服务器上,从而引入了一个错误,并且花了一些时间才发现该错误,这意味着此期间您的应用收到的所以请求都将失败,有没有办法处理它们并修复这些执行失败的队列。如您所知,您不能要求您的客户再次向您发送请求(这是不可能的)。幸运的是,数据没有丢失,我们可以重试失败的任务队列,而不会出现任何问题。
但是在我们探索如何做之前,我希望您可以阅读queue:work的帮组命令:
php artisan queue:work --help

请注意,该命令可接受多个参数,其中一个参数tries(这里是我们感兴趣的参数)
--tries[=TRIES] Number of times to attempt a job before logging it failed [default: "1"]
此参数有助于我们确认将任务队列标记为失败之前重试该任务队列的次数。请注意,默认值为1,这意味这一旦任务队列执行失败一次,它将被标记为失败。
当任务队列执行失败时,它将保存在failed_jobs表中,Laravel同样为我们提供了相关的创建迁移文件命令:
php artisan queue:failed-table
换句话说,如果您正在应用程序中运用任务队列,则需要运行此命令来产生迁移文件。
现在让我们停止queue:work进程,并尝试模拟失败的任务队列
让我们在handle()方法的开头添加以下代码:
throw new \Exception("Error Processing the job", 1);
因此,每当我们尝试处理任务队列时,任务队列都会失败,我们看看发生来什么(不要忘记发送一些新的POST请求)

如您所见,任务队列都执行失败了,如果我们访问failed_jobs表,我们可以找到有关它们的更多信息。

在表中的每个数据,我们都可以看到任务队列的有效负载,导致其失败的异常信息,连接方式,连接队列和队列失败的时间。
现在,我们删除引发异常的那一行代码,并尝试重新执行队列。
我们可以重试所以失败的任务队列或仅重试一个特定的任务队列(用任务队列的ID替换all):
php artisan queue:retry all
如果您在重试作业之前没有停止先前的queue:work进程,则会发现重试的任务队列会再次失败,这是怎么回事呢?
根据 Laravel文档:
队列工作进程是一个长期存在的进程,并将已启动的应用程序存储在内存中。启动后,进程将不会注意您的代码库的更改。因此,在部署过程中,请确保重启队列工作进程.
因此,我们需要重新启动该进程。
另外,如果您希望避免每次在本地更改某些内容时都需要重新启动该进程,则可以改用以下内容:
php artisan queue:listen
但是,根据官方文档,此命令的效率不如 queue:work
现在让我们重新启动queue:work进程,然后重试所有失败的任务队列。
任务队列将被重新运行,我们将在hits表中查看到新的数据更新。
下一步是什么
在下一个教程中,我们将看到如何使用其他队列连接(数据库连接除外),我们将探索多个队列的使用以及如何使某些任务/队列比其他队列具有更高的优先级。
接下来,我们将探讨如何部署依赖于任务队列的应用程序,以及需要执行哪些操作来保持进程运行。
本文中的所有译文仅用于学习和交流目的,转载请务必注明文章译者、出处、和本文链接
我们的翻译工作遵照 CC 协议,如果我们的工作有侵犯到您的权益,请及时联系我们。
























 关于 LearnKu
关于 LearnKu




推荐文章: