
生产服务器 PHP-FPM 响应慢
服务器配置
- 64 G 内存
- 12 CPU
运行环境
使用的 ansible 搭建的 docker swarm 集群,目前是单服务器,因为出了问题。一直找不到原因。所以其他节点没有搭建。
出现的问题
php-fpm 响应很慢。发几个图就能很明显的看到。
prometheus 监控的服务器信息
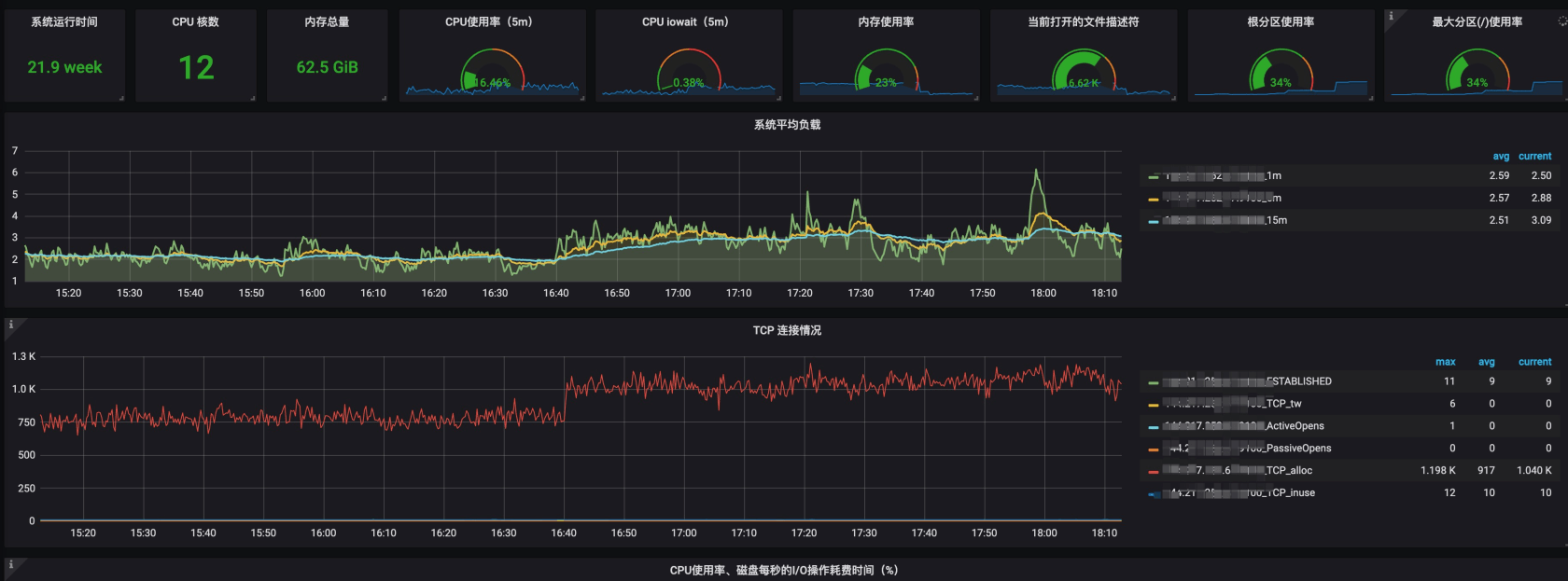
可以看到,负载不是很高。
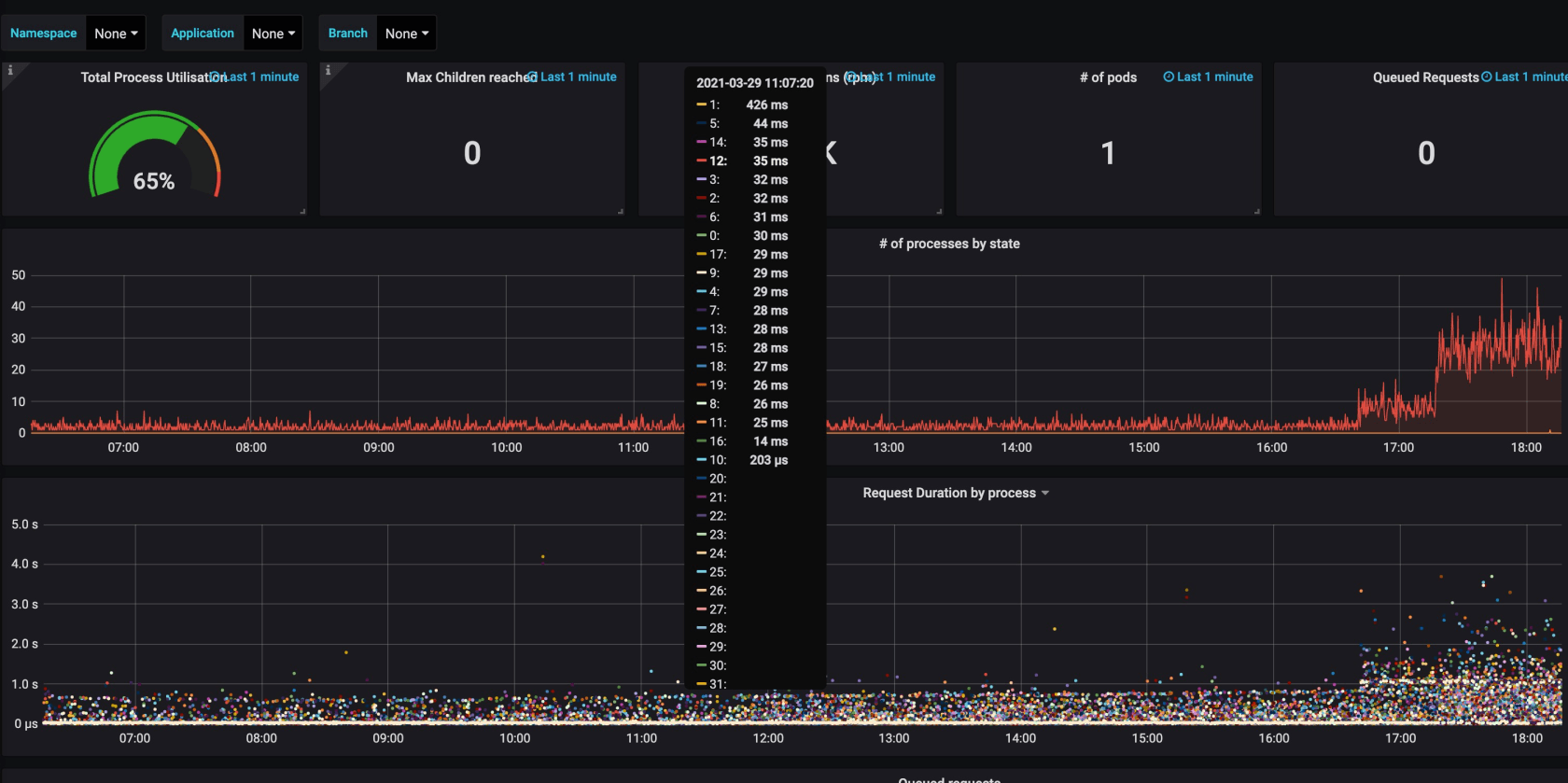
prometheus 监控的 php-fpm 信息

可以看到,有大量的响应是几百毫秒和超过 1 秒的。
低流量的时候,响应是很快的。基本在 30 ms 左右。如下图:
kibana 查看的 nginx 日志信息

在这里可以看到,upstream_connect_time 居然花费了 1s 多,找不到原因。
php-fpm 配置:
user = www-data
group = www-data
listen = 0.0.0.0:9000
pm = static
pm.max_children = 50
pm.start_servers = 15
pm.min_spare_servers = 10
pm.max_spare_servers = 20
pm.max_requests = 1000
request_slowlog_timeout = 0
pm.status_path = /status
ping.path = /ping原来使用的是 dynamic 模式,响应慢,所以我换成了 static ,还是很慢。
sql 语句记录了慢日志,没有慢的 sql 语句。
我应该如何排查这个问题呢?主要是没有思路。请大牛们给一个思路啊?

































 关于 LearnKu
关于 LearnKu




推荐文章: