
爬取豆瓣电影并分析

今天给大家分享的是用python爬取豆瓣电影top250,并将爬取的数据进行分析后用图标可视化展示。虽说豆瓣电影早就被玩烂了,但个人认为,如果你之前没有接触过爬虫,可以将这本文作为入门篇。
一、爬虫简介
说起网络爬虫,人们常常会用这样一个比喻:如果把互联网比喻成一张网,那么网络爬虫就可以认为是一个在网上爬来爬去的小虫子,它通过网页的链接地址来寻找网页,通过特定的搜索算法来确定路线,通常从网站的某一个页面开始,读取网页的内容,找到在网页中的其它链接地址,然后通过这些链接地址寻找下一个网页,这样一直循环下去,直到把这个网站所有网页都抓取完为止。
通俗点讲就是按照一定的规则请求网站并提取数据的自动化程序。
二、页面分析
本次要爬的网站是豆瓣电影Top250,这是网友评选的250部最佳影片。网址是 https://movie.douban.com/top250。
首先,我们要爬的信息有,电影名,电影别名,导演,影片制作国家,所属类型,评分,评价数量,一句话评价。如下图,我们要的信息在图中都能看到。
然后右键查看页面源代码

可以看到要爬的每个页面信息都在ol属性,而每部电影的基本信息都在class为info的div属性中。这样我们就可以爬取每个页面中所有class为info的div属性,获取文本,然后进行提取信息。之后要爬取其他页面,发现了页面的链接是有规律的
第一个页面链接:https://movie.douban.com/top250?start=0&filter=
第一个页面链接:https://movie.douban.com/top250?start=25&filter=很明显,只是start的值以每次25递增,所以我们只要用for循环进行更改start的值,就能爬取其他页面的信息了。
三、爬取数据
本次用到的模块是 XPath,如需了解,可看这篇博客https://blog.csdn.net/qq_25343557/article/details/81912992
首先先获取页面的所有链接

然后通过链接爬取所需信息

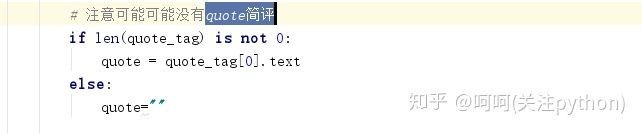
这里因为有些电影没有quote简评,所以需要进行判断,防止出现列表越界异常
最后是将数据写入到csv,这里用到csv模块。

这里的newline参数表示写入csv文件, 以空格作为换行符,如果不加该参数,会多出一行空行,大家自己可以试下。
csv文件的数据如图所示:

四、数据分析
数据分析是用 pandas 模块进行分析。这里主要说下年份和国家的分析。
因为是要对年份进行分组,所以在这里是写个方法对传进来的数据判断并返回所属年份范围。因为数据中有两部电影的年份包含制作国家,所以需要先进行判断。

传入数据用到的是 apply() 方法,该函数传入的是参数是函数,有点类似映射。

从数据可知,有些电影不止一种类型并且以空格分隔,所以需要将多种类型按空格分开然后再统计。

五、数据可视化
本次可视化用到的是 python 的第三方模块 pyecharts根据它的名字很容易联想到这是 python+echarts。在这里说下,echarts是百度开发的一个开源纯 javascript 的图表库,也就是给定数据然后生成柱状图,折线图等图表,以便更直观的理解数据关系。所以 pyecharts 是一个用 python 程序生成 Echarts 图表的类库,实际上就是 echarts 与 Python 的对接。需要了解的前往 pyecharts官网。
注意:pyecharts 在1.0.0版本进行了更改,和之前的版本完全不兼容,本次用到的版本是1.0.0,如果之前安装了1.0.0之前的版本,可以卸载重新安装。
因为使用pyecharts不难,所以这里就不多说了,直接看可视化的结果吧。

从1984年起,电影的数量就不断增加,这也反映了电影行业的蓬勃发展。\
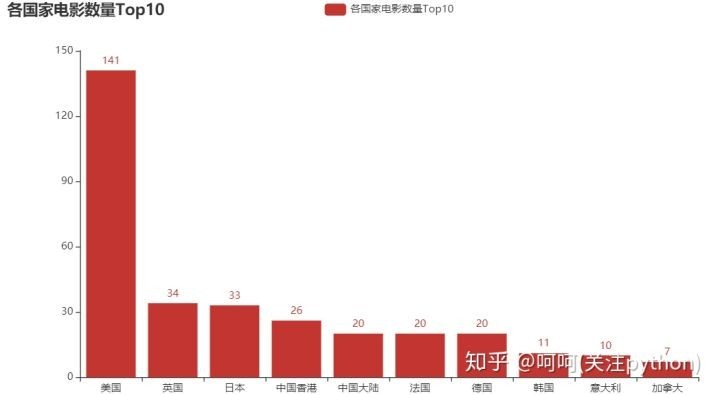
在豆瓣电影Top250,美国发行的电影数量是最高的,这也说明了美国的电影确实是比较高产。
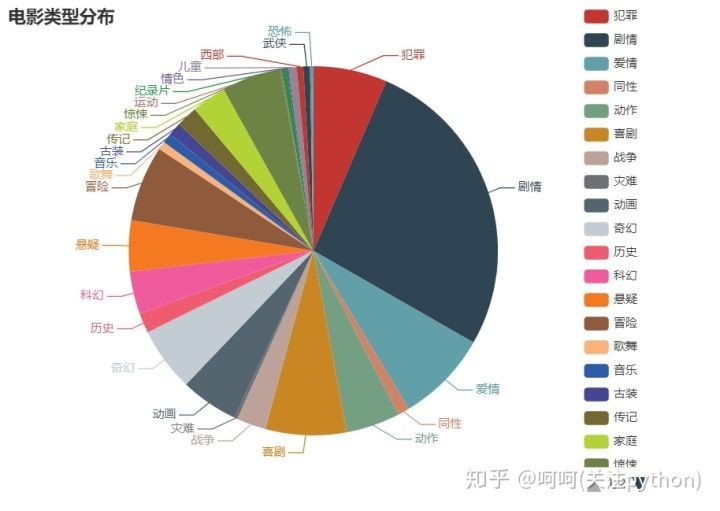
剧情类的电影往往更受观众喜爱。个人觉得剧情类电影很容易就把观众带入所描述的环境氛围中,观众可以用眼睛和大脑切换两个小时的另一种生活,更容易带来刺激感。
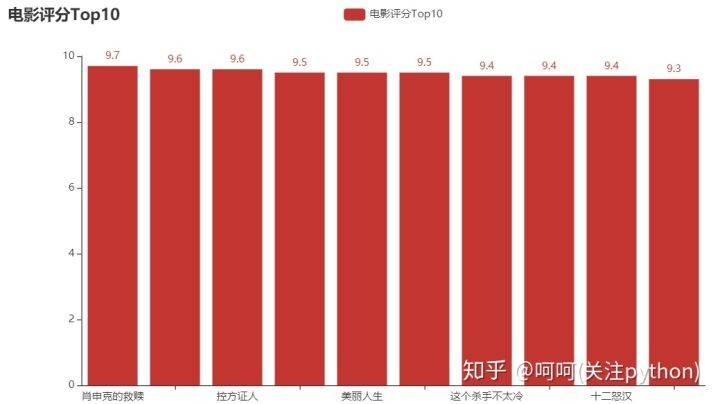
肖申克的救赎评分是最高的,这部电影我看过两次,确实好看。里面有很多经典台词,个人很喜欢这段台词,“这些墙很有趣。刚入狱的时候,你痛恨周围的高墙;慢慢地,你习惯了生活在其中;最终你会发现自己不得不依靠它而生存。这就叫体制化。” 如果没看过的小伙伴,可以去看下,绝对引起深思。
对该案例的实现总结一下
- 对需要爬取的网站进行分析
- 用程序爬页面数据
- 对爬取的数据进行清洗,分析
- 数据可视化
其实要爬其他网站数据,大都都是这几个步骤,就是细节方面要修改,所以,对于初学者,有时间这个案例还是要自己操作一遍。
最后,公众号【python编程之美】后台回复“豆瓣”,获得本文的全部代码。








 关于 LearnKu
关于 LearnKu




推荐文章: