
使用 pandas 添加一列数据
import jqdata
import pandas as pd
from pandas import DataFrame
import numpy as np
security = ['000001.XSHE', '000040.XSHE', '000099.XSHE'];
h = get_price(security, start_date='2020-03-26', end_date='2020-03-27', frequency='1m', fields=None, skip_paused=False, fq='pre')
h = h.transpose(2,1,0);
date='2020-03-26';
for code in security:
q = query(valuation).filter(valuation.code == code)
c = get_fundamentals(q, date=None, statDate=None)
capita_field = c['circulating_cap'][0]
print(capita_field)
h[code] = DataFrame(h[code])
h[code]['circulating_cap'] = capita_field
print(h[code].head())
for code in security:
print(code)
print(h[code].head())各种位老师!
我在第一个循环时打印数据,感觉不对,但从遍历的结果看是三组数据中有二组新增一列是成功的。
但是到了第二个循环打印出来的结果却是只有最后一组数据有新增一列数据,结果如下: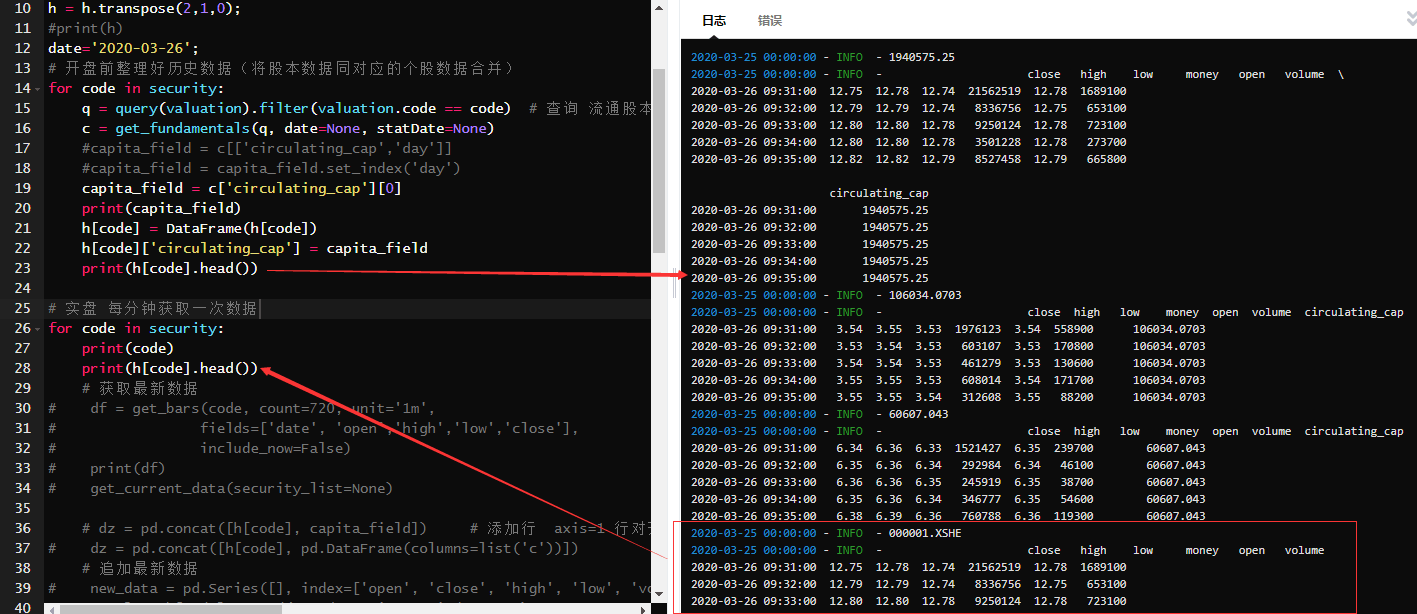
复制内容如下:
2020-03-25 00:00:00 - INFO - 1940575.25
2020-03-25 00:00:00 - INFO - close high low money open volume
2020-03-26 09:31:00 12.75 12.78 12.74 21562519 12.78 1689100
2020-03-26 09:32:00 12.79 12.79 12.74 8336756 12.75 653100
2020-03-26 09:33:00 12.80 12.80 12.78 9250124 12.78 723100
2020-03-26 09:34:00 12.80 12.80 12.78 3501228 12.78 273700
2020-03-26 09:35:00 12.82 12.82 12.79 8527458 12.79 665800
circulating_cap 2020-03-26 09:31:00 1940575.25
2020-03-26 09:32:00 1940575.25
2020-03-26 09:33:00 1940575.25
2020-03-26 09:34:00 1940575.25
2020-03-26 09:35:00 1940575.25
2020-03-25 00:00:00 - INFO - 106034.0703
2020-03-25 00:00:00 - INFO - close high low money open volume circulating_cap
2020-03-26 09:31:00 3.54 3.55 3.53 1976123 3.54 558900 106034.0703
2020-03-26 09:32:00 3.53 3.54 3.53 603107 3.53 170800 106034.0703
2020-03-26 09:33:00 3.54 3.54 3.53 461279 3.53 130600 106034.0703
2020-03-26 09:34:00 3.55 3.55 3.53 608014 3.54 171700 106034.0703
2020-03-26 09:35:00 3.55 3.55 3.54 312608 3.55 88200 106034.0703
2020-03-25 00:00:00 - INFO - 60607.043
2020-03-25 00:00:00 - INFO - close high low money open volume circulating_cap
2020-03-26 09:31:00 6.34 6.36 6.33 1521427 6.35 239700 60607.043
2020-03-26 09:32:00 6.35 6.36 6.34 292984 6.34 46100 60607.043
2020-03-26 09:33:00 6.36 6.36 6.35 245919 6.35 38700 60607.043
2020-03-26 09:34:00 6.35 6.36 6.34 346777 6.35 54600 60607.043
2020-03-26 09:35:00 6.38 6.39 6.36 760788 6.36 119300 60607.043
但是到了第二个循环打印出来的结果却是只有最后一组数据有新增一列数据,结果如下:
2020-03-25 00:00:00 - INFO - 000001.XSHE
2020-03-25 00:00:00 - INFO - close high low money open volume
2020-03-26 09:31:00 12.75 12.78 12.74 21562519 12.78 1689100
2020-03-26 09:32:00 12.79 12.79 12.74 8336756 12.75 653100
2020-03-26 09:33:00 12.80 12.80 12.78 9250124 12.78 723100
2020-03-26 09:34:00 12.80 12.80 12.78 3501228 12.78 273700
2020-03-26 09:35:00 12.82 12.82 12.79 8527458 12.79 665800
2020-03-25 00:00:00 - INFO - 000040.XSHE
2020-03-25 00:00:00 - INFO - close high low money open volume
2020-03-26 09:31:00 3.54 3.55 3.53 1976123 3.54 558900
2020-03-26 09:32:00 3.53 3.54 3.53 603107 3.53 170800
2020-03-26 09:33:00 3.54 3.54 3.53 461279 3.53 130600
2020-03-26 09:34:00 3.55 3.55 3.53 608014 3.54 171700
2020-03-26 09:35:00 3.55 3.55 3.54 312608 3.55 88200
2020-03-25 00:00:00 - INFO - 000099.XSHE
2020-03-25 00:00:00 - INFO - close high low money open volume circulating_cap
2020-03-26 09:31:00 6.34 6.36 6.33 1521427 6.35 239700 60607.043
2020-03-26 09:32:00 6.35 6.36 6.34 292984 6.34 46100 60607.043
2020-03-26 09:33:00 6.36 6.36 6.35 245919 6.35 38700 60607.043
2020-03-26 09:34:00 6.35 6.36 6.34 346777 6.35 54600 60607.043
2020-03-26 09:35:00 6.38 6.39 6.36 760788 6.36 119300 60607.043
想不出错误在哪?请各位老师帮助


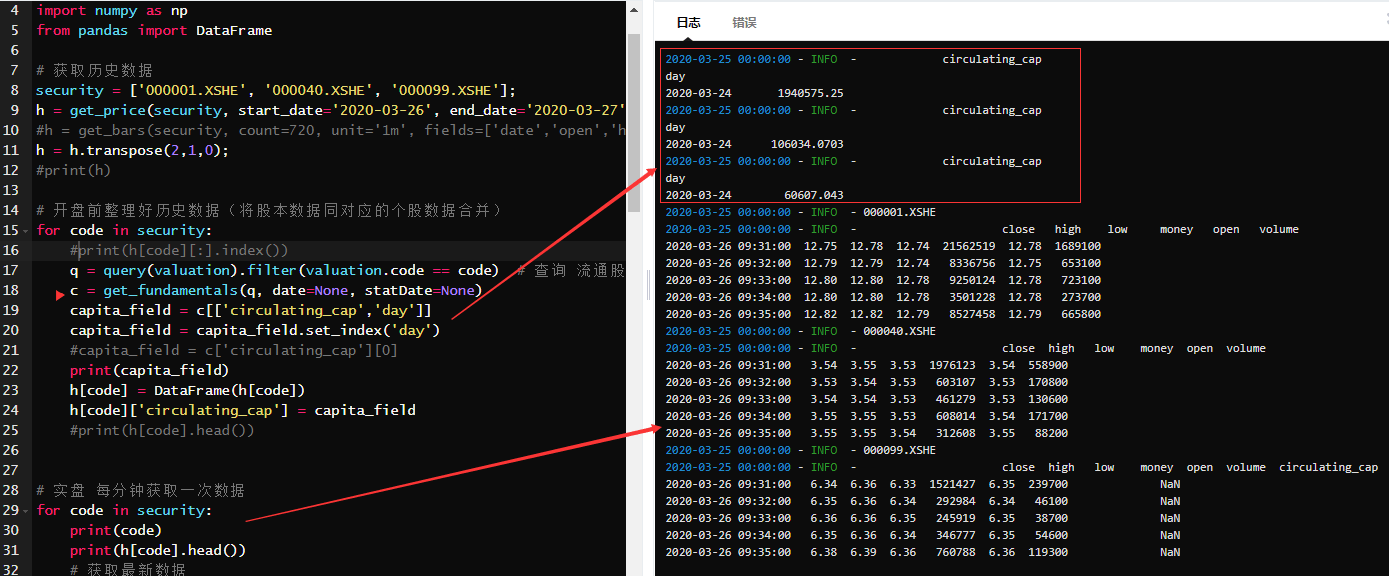 从图中可以看到 新增一列自带的时间格式同原表的时间格式有冲突,运行虽没有报错,但新增一列的结果同之前还是一样,如果要完整的时间索引,应该是要取原表的,可是不知道如何取?百度上都是二维的方式,虽然我通过循环将低到二维,print(h[code][:].index()) 但在取的时候报错。
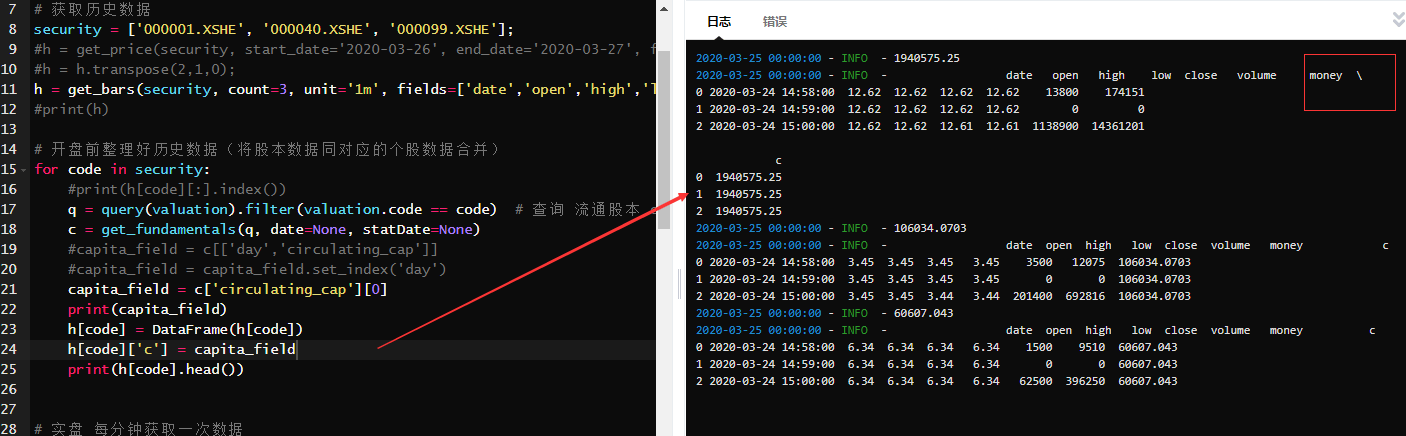
从图中可以看到 新增一列自带的时间格式同原表的时间格式有冲突,运行虽没有报错,但新增一列的结果同之前还是一样,如果要完整的时间索引,应该是要取原表的,可是不知道如何取?百度上都是二维的方式,虽然我通过循环将低到二维,print(h[code][:].index()) 但在取的时候报错。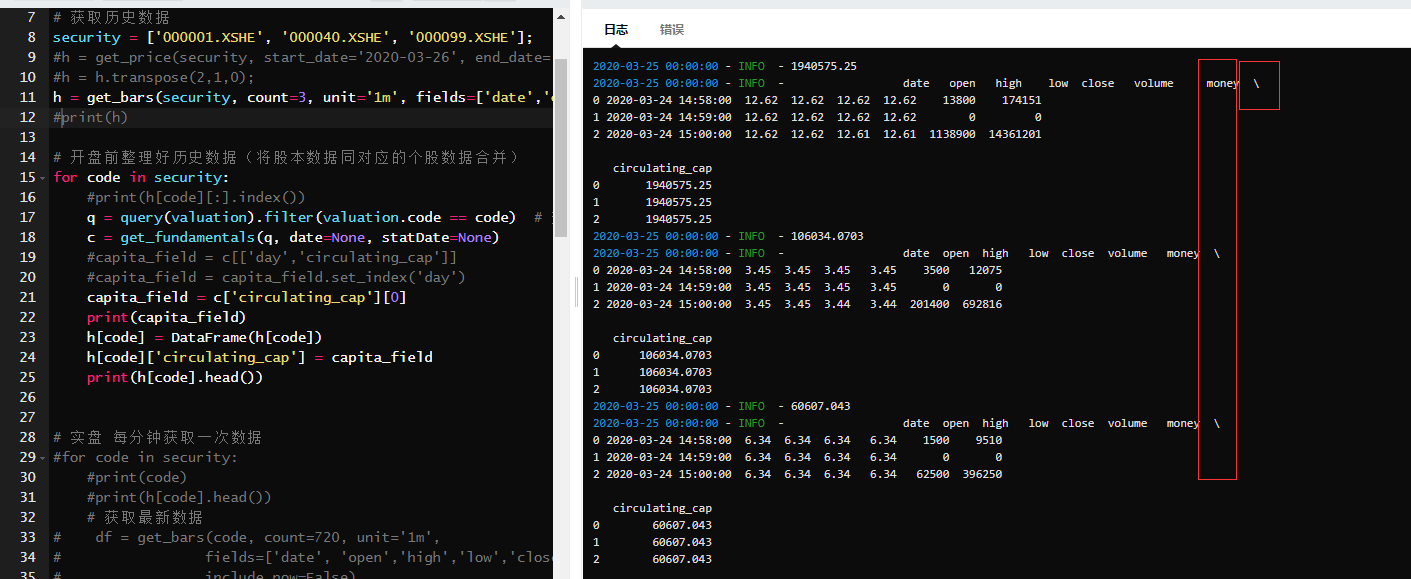 这里我改变原数据格式,虽未报错,但结果不对
这里我改变原数据格式,虽未报错,但结果不对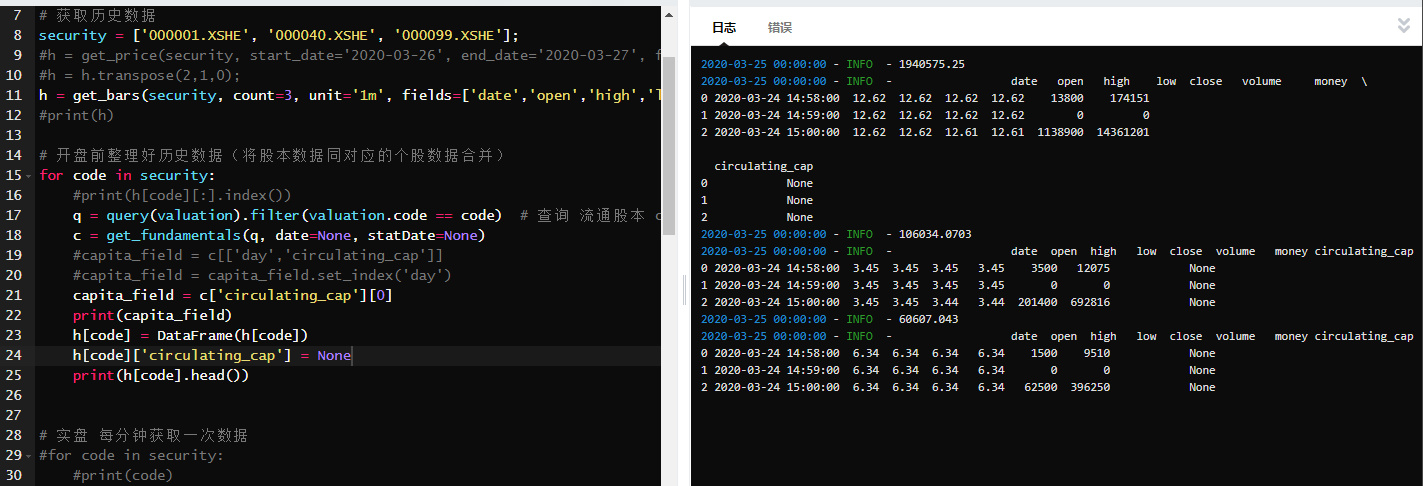 上面我又尝试新一列空值,虽未报错,但结果应该是存在问题,我猜想应该我新增一列的方法存在问题
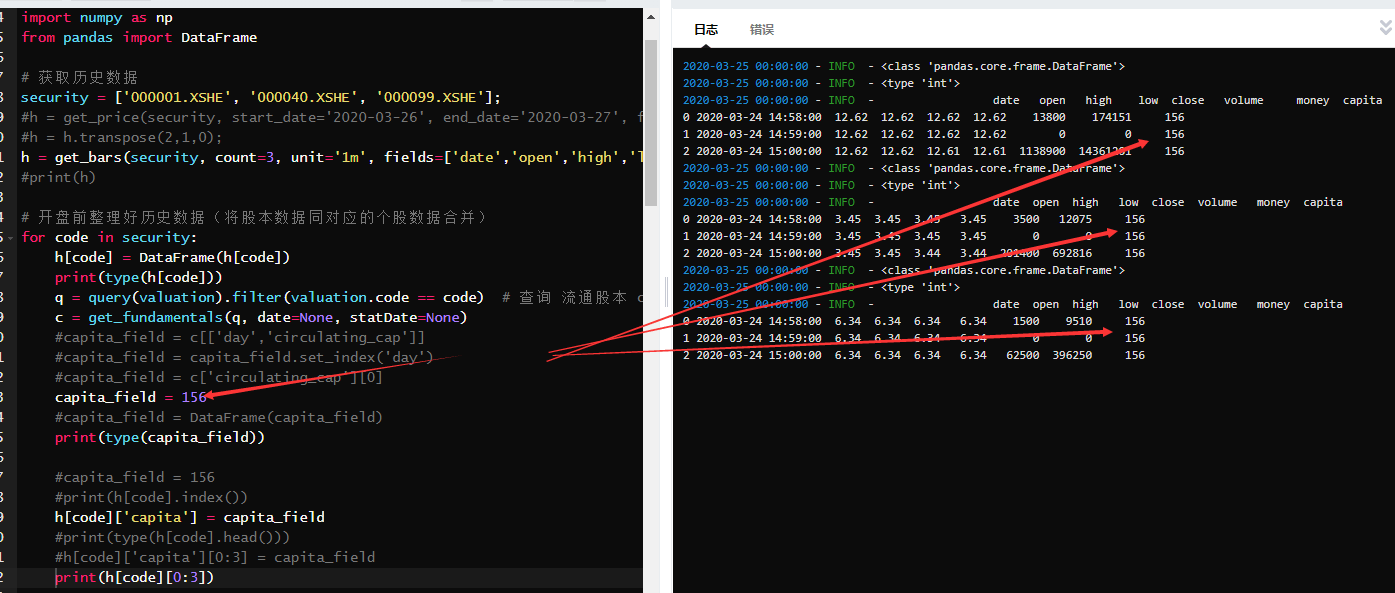
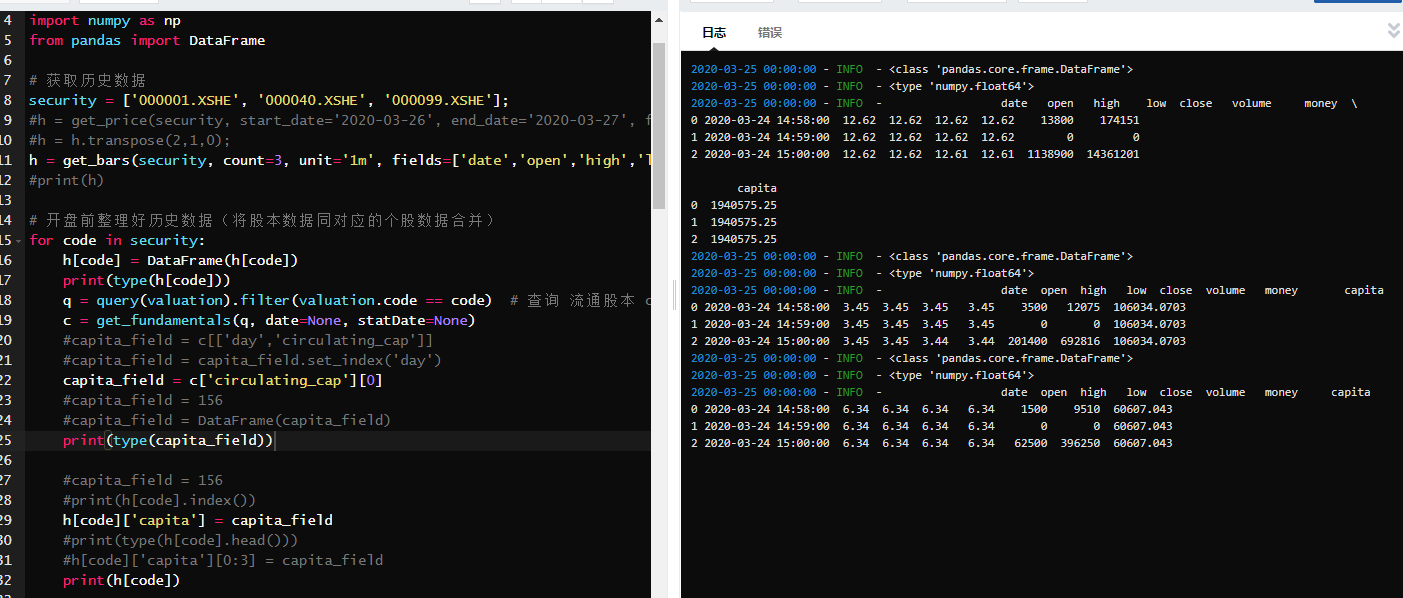
上面我又尝试新一列空值,虽未报错,但结果应该是存在问题,我猜想应该我新增一列的方法存在问题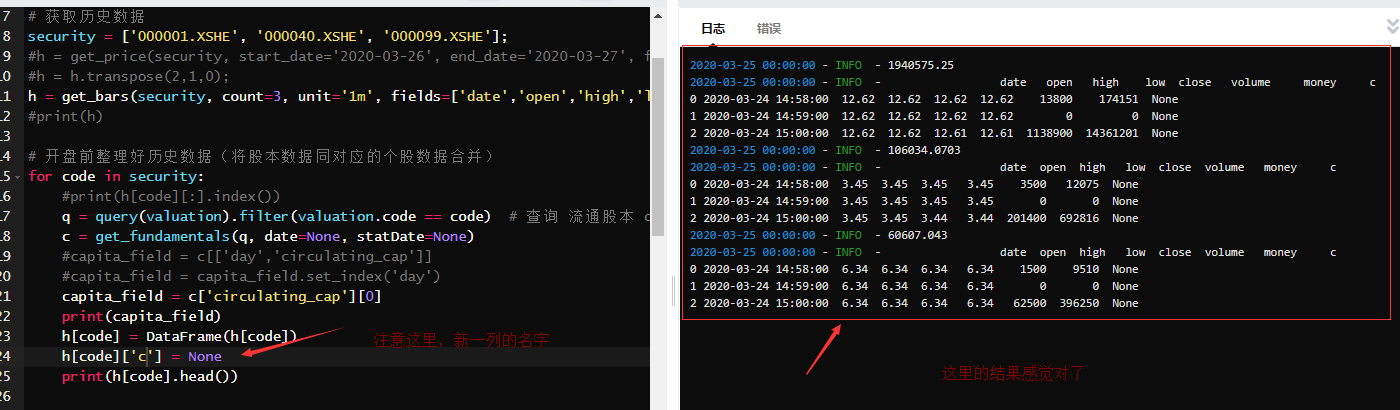


 关于 LearnKu
关于 LearnKu




推荐文章: