
分享基于asyncio及aio全家桶, 实现scrapy流程及标准的轻量框架
项目简介(来源于github):
- 该框架基于开源框架scrapy 和scrapy_redis, 标准流程开发通用方案, 比scrapy框架更为轻量使用场景自定义方案更为丰富
- 实现了动态变量注入和异步协程功能, 各个节点之间分离使用, 简化scrapy内置拓展功能, 保留了核心基本用法。
- 内置分布式爬取优先级队列redis, rabbitMq等。
运行截图: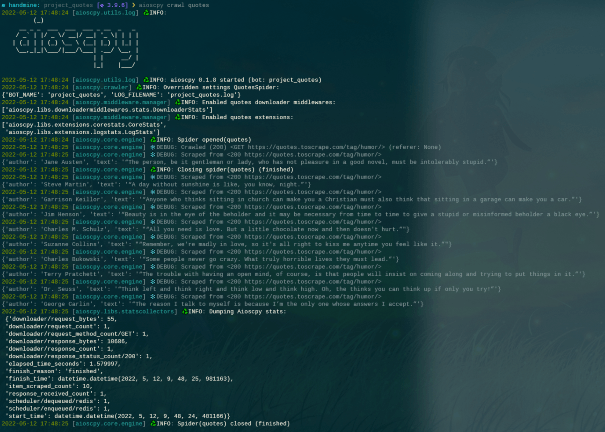
单脚本爬虫:
from aioscpy.spider import Spider
from anti_header import Header
from pprint import pprint, pformat
class SingleQuotesSpider(Spider):
name = 'single_quotes'
custom_settings = {
"SPIDER_IDLE": False
}
start_urls = [
'https://quotes.toscrape.com/',
]
async def process_request(self, request):
request.headers = Header(url=request.url, platform='windows', connection=True).random
return request
async def process_response(self, request, response):
if response.status in [404, 503]:
return request
return response
async def process_exception(self, request, exc):
raise exc
async def parse(self, response):
for quote in response.css('div.quote'):
yield {
'author': quote.xpath('span/small/text()').get(),
'text': quote.css('span.text::text').get(),
}
next_page = response.css('li.next a::attr("href")').get()
if next_page is not None:
yield response.follow(next_page, callback=self.parse)
async def process_item(self, item):
self.logger.info("{item}", **{'item': pformat(item)})
if __name__ == '__main__':
quotes = QuotesSpider()
quotes.start()github地址: 基于asyncio与aio全家桶, scrapy流程轻量框架






 关于 LearnKu
关于 LearnKu




推荐文章: