
数据挖掘,分类模型中分类误差集中在某个区域
近期做过两份数据的分类模型:
(1)航班数据,预测是否延误(0代表准时,1代表延误)
(2)图书馆数据,预测客户是否会购买新书(0代表不会买,1代表会买)
这两份数据的结构比较像,结果变量的分布不均匀,即上述0的数据非常多,而1的数据非常少。
其分类结果也非常类似,虽然分类准确率都比较高,但实际情况是分类器把绝大部分的实际上是1的数据预测为0了,分类结果的混淆矩阵如下。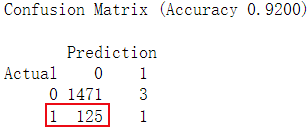
尝试过的办法:
A:使用不同的分类算法(KNN、Logistics回归、决策树等),但无法解决问题。
B:使用不同的预测变量(因变量),但无法解决问题。
C:使用过采样进行数据分区,同样无法解决问题。
部分代码:
from sklearn.linear_model import LogisticRegression
from imblearn.over_sampling import SMOTE
#过采样数据分区
x = data[[‘Gender’, ‘M’, ‘R’, ‘F’, ‘FirstPurch’, ‘ChildBks’,
‘YouthBks’, ‘CookBks’, ‘DoItYBks’, ‘RefBks’, ‘ArtBks’, ‘GeogBks’,
‘ItalCook’, ‘ItalAtlas’, ‘ItalArt’,’Related Purchase’]]
y = data[‘Florence’]
smo = SMOTE(random_state=1)
x_smo, y_smo = smo.fit_resample(x, y)
train_smo_x,valid_smo_x,train_smo_y,valid_smo_y = train_test_split(x,y,test_size=0.4,random_state=1)
train_smo_x1 = train_smo_x
train_smo_x2 = train_smo_x[[‘Gender’, ‘M’, ‘R’, ‘F’, ‘FirstPurch’,’ItalArt’,’Related Purchase’]]
train_smo_x3 = train_smo_x[[ ‘M’, ‘R’, ‘F’]]
valid_smo_x1 = valid_smo_x
valid_smo_x2 = valid_smo_x[[‘Gender’, ‘M’, ‘R’, ‘F’, ‘FirstPurch’,’ItalArt’,’Related Purchase’]]
valid_smo_x3 = valid_smo_x[[ ‘M’, ‘R’, ‘F’]]
#logistic分类模型(使用3组不同的自变量)
logtics1 = LogisticRegression().fit(train_smo_x1,train_smo_y)
logtics2 = LogisticRegression().fit(train_smo_x2,train_smo_y)
logtics3 = LogisticRegression().fit(train_smo_x3,train_smo_y)
#混淆矩阵
classificationSummary(valid_smo_y,logtics1.predict(valid_smo_x1))
classificationSummary(valid_smo_y,logtics2.predict(valid_smo_x2))
classificationSummary(valid_smo_y,logtics3.predict(valid_smo_x3))
结果:





 关于 LearnKu
关于 LearnKu



