
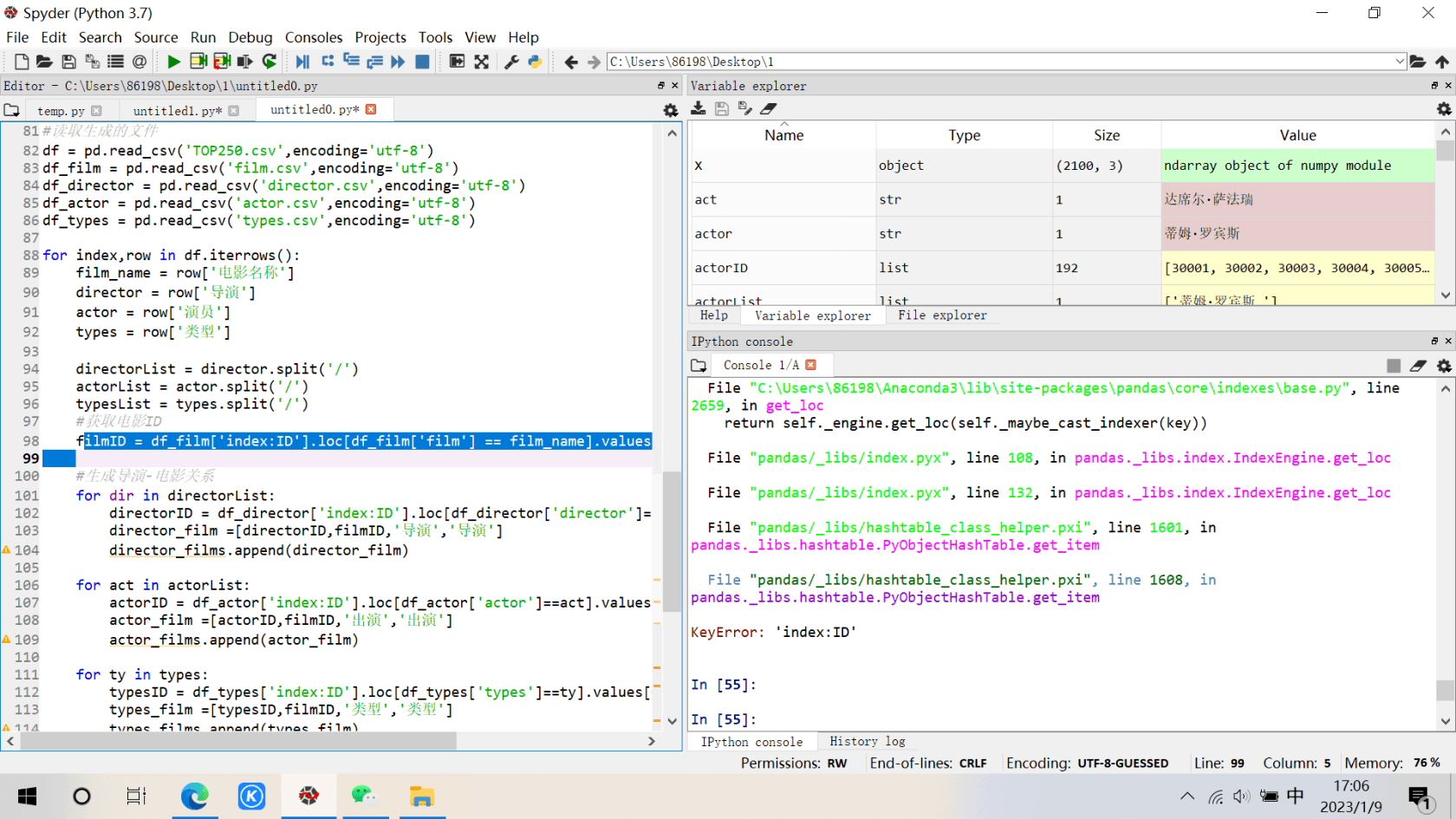
参考博文通过豆瓣电影TOP250csv文件构建知识图谱,在提取节点关系文件时报错:“KeyError:'index:ID'”,有什么解决办法吗?
 ```python
```python
import pandas as pd
df =pd.read_csv(‘TOP250.csv’,encoding=’utf-8’)
df_film = df[‘电影名称’]
df_director = df[‘导演’]
df_actor = df[‘演员’]
df_types = df[‘类型’]
filmID,directorID,actorID,typesID = [],[],[],[]
#获取电影的列表、数量、df表
filmList = list(df_film)
film_cnt = len(filmList)
df_film_name = pd.DataFrame(data=filmList,columns=[‘filmName’])
directorList = []
for dir in df_director:
directorList.extend(dir.split(‘/‘))
directorList = list(set(directorList))
director_cnt = len(directorList)
df_director_name = pd.DataFrame(data=directorList,columns=[‘directorName’])
actorList = []
for act in df_actor:
actorList.extend(act.split(‘/‘))
actorList = list(set(actorList))
actor_cnt = len(actorList)
df_actor_name = pd.DataFrame(data=actorList,columns=[‘actorName’])
typesList = []
for ty in df_types:
typesList.extend(ty.split(‘/‘))
typesList = list(set(typesList ))
types_cnt = len(typesList )
df_types_name = pd.DataFrame(data=typesList,columns=[‘typesList’])
#生成电影的ID
for i in range(10001,10001 + film_cnt):
filmID.append(i)
df_film_ID = pd.DataFrame(data=filmID,columns=[‘filmID’])
for i in range(20001,20001 + director_cnt):
directorID.append(i)
df_director_ID = pd.DataFrame(data=directorID,columns=[‘directorID’])
for i in range(30001,30001 + actor_cnt):
actorID.append(i)
df_actor_ID = pd.DataFrame(data=actorID,columns=[‘actorID’])
for i in range(40001,40001 + types_cnt):
typesID.append(i)
df_types_ID = pd.DataFrame(data=typesID,columns=[‘typesID’])
#拼接电影列表
film = pd.concat([df_film_ID,df_film_name],axis=1)
film[‘label’] =’电影’
director = pd.concat([df_director_ID,df_director_name],axis=1)
director[‘label’] =’导演’
actor = pd.concat([df_actor_ID,df_actor_name],axis=1)
actor[‘label’] =’演员’
types = pd.concat([df_types_ID,df_types_name],axis=1)
types[‘label’] =’类型’
#生成节点文件
film.cloumns = [‘index:ID’,’film’,’:LABEL’]
film.to_csv(‘film.csv’,index=False,encoding=’utf-8_sig’)
director.cloumns = [‘index:ID’,’director’,’:LABEL’]
director.to_csv(‘director.csv’,index=False,encoding=’utf-8_sig’)
actor.cloumns = [‘index:ID’,’actor’,’:LABEL’]
actor.to_csv(‘actor.csv’,index=False,encoding=’utf-8_sig’)
types.cloumns = [‘index:ID’,’types’,’:LABEL’]
types.to_csv(‘types.csv’,index=False,encoding=’utf-8_sig’)
#读取生成的文件
df = pd.read_csv(‘TOP250.csv’,encoding=’utf-8’)
df_film = pd.read_csv(‘film.csv’,encoding=’utf-8’)
df_director = pd.read_csv(‘director.csv’,encoding=’utf-8’)
df_actor = pd.read_csv(‘actor.csv’,encoding=’utf-8’)
df_types = pd.read_csv(‘types.csv’,encoding=’utf-8’)
for index,row in df.iterrows():
film_name = row[‘电影名称’]
director = row[‘导演’]
actor = row[‘演员’]
types = row[‘类型’]
directorList = director.split('/')
actorList = actor.split('/')
typesList = types.split('/')
#获取电影ID
filmID = df_film['index:ID'].loc[df_film['film'] == film_name].values[0]
#生成导演-电影关系
for dir in directorList:
directorID = df_director['index:ID'].loc[df_director['director']==dir].values[0]
director_film =[directorID,filmID,'导演','导演']
director_films.append(director_film)
for act in actorList:
actorID = df_actor['index:ID'].loc[df_actor['actor']==act].values[0]
actor_film =[actorID,filmID,'出演','出演']
actor_films.append(actor_film)
for ty in types:
typesID = df_types['index:ID'].loc[df_types['types']==ty].values[0]
types_film =[typesID,filmID,'类型','类型']
types_films.append(types_film)
for dir in directorList:
directorID = df_director['index:ID'].loc[df_director['director']==dir].values[0]
for act in actorList:
actorID = df_actor['index:ID'].loc[df_actor['actor']==act].values[0]
director_actor = [directorID,actorID,'合作','合作']
director_actor.append(director_actor)df_director_film = pd.DataFrame(data=director_films,columns=[‘:STSRT_ID’,’:END_ID’,’relation’,’:TYPE’])
df_director_film.to_csv(‘relation_director_film.csv’,index=False,encoding=’utf-8_sig’)
df_actor_film = pd.DataFrame(data=actor_films,columns=[‘:STSRT_ID’,’:END_ID’,’relation’,’:TYPE’])
df_actor_film.to_csv(‘relation_ator_film.csv’,index=False,encoding=’utf-8_sig’)
df_director_actor = pd.DataFrame(data=director_actor,columns=[‘:STSRT_ID’,’:END_ID’,’relation’,’:TYPE’])
df_director_actor.to_csv(‘relation_director_actor.csv’,index=False,encoding=’utf-8_sig’)
df_film_type = pd.DataFrame(data=film_types,columns=[‘:STSRT_ID’,’:END_ID’,’relation’,’:TYPE’])
df_film_type.to_csv(‘relation_film_type.csv’,index=False,encoding=’utf-8_sig’)
```




 关于 LearnKu
关于 LearnKu




Check if
'index:ID'in the list.