
用python爬取amazon网站数据中,requests.get返回的网页代码和Google检查里面的网页代码不一致,请问是什么原因导致的?
大家好,我刚学习python,现在练习用python爬取amazon网站数据中,requests.get返回的网页代码和Google检查里面的网页代码不一致。python代码如下:
import requests
headers = {
‘cookie’: ‘session-id=131-5533759-6787907; i18n-prefs=USD; ubid-main=132-6890155-4482501; skin=noskin; session-id-time=2082787201l; lc-main=en_US; session-token=”o+VC7ESYeP6/wHPHHEoUXlDh5wnNK7+lO9lJKfEyCD7pDz3wHkRpKtT723g9tEkYuSx6F9AWvNWtSWpPm+4hOwLplT9IEHPs0aydQHXvDfauqEUp/KxdDJ1CixjbNHCwMRxite2nkFbevPx4PDEpIEvEO3J/UOeNfBioO2pureYEWeF8IF3HrehEhCncZFKBJJu2ZpNI6f4Chfgziqhl7ahrHNN3+cC62+YdZztpTOw=”; csm-hit=tb:86VQEV429W9SSWR4B8H1+s-AWKCE11QBHJ482M6NYM9|1679042233824&t:1679042233824&adb:adblk_no’,
‘referer’: ‘www.amazon.com/Best-Sellers-Handma...,
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36',}
url = ‘www.amazon.com/Best-Sellers-Handma...
#获取数据
response = requests.get(url=url, headers=headers)
html_data = response.text
print(html_data)
print(response.status_code)
运行结果如下:
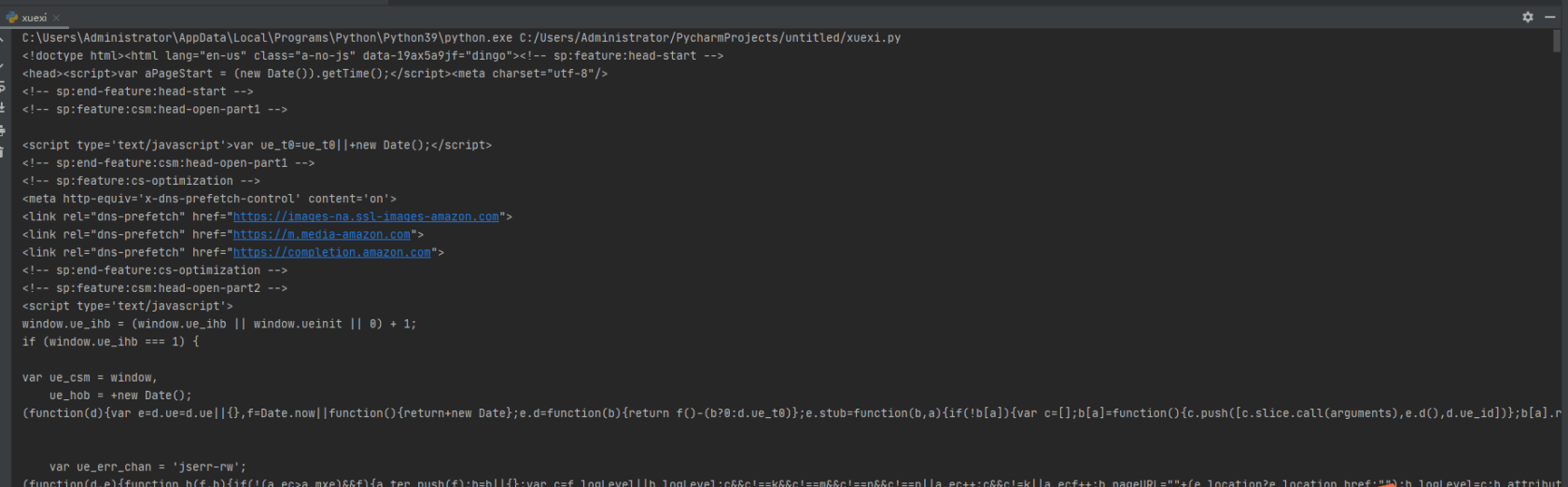
最后返回的代码是200;
下面是网页检查里面的代码: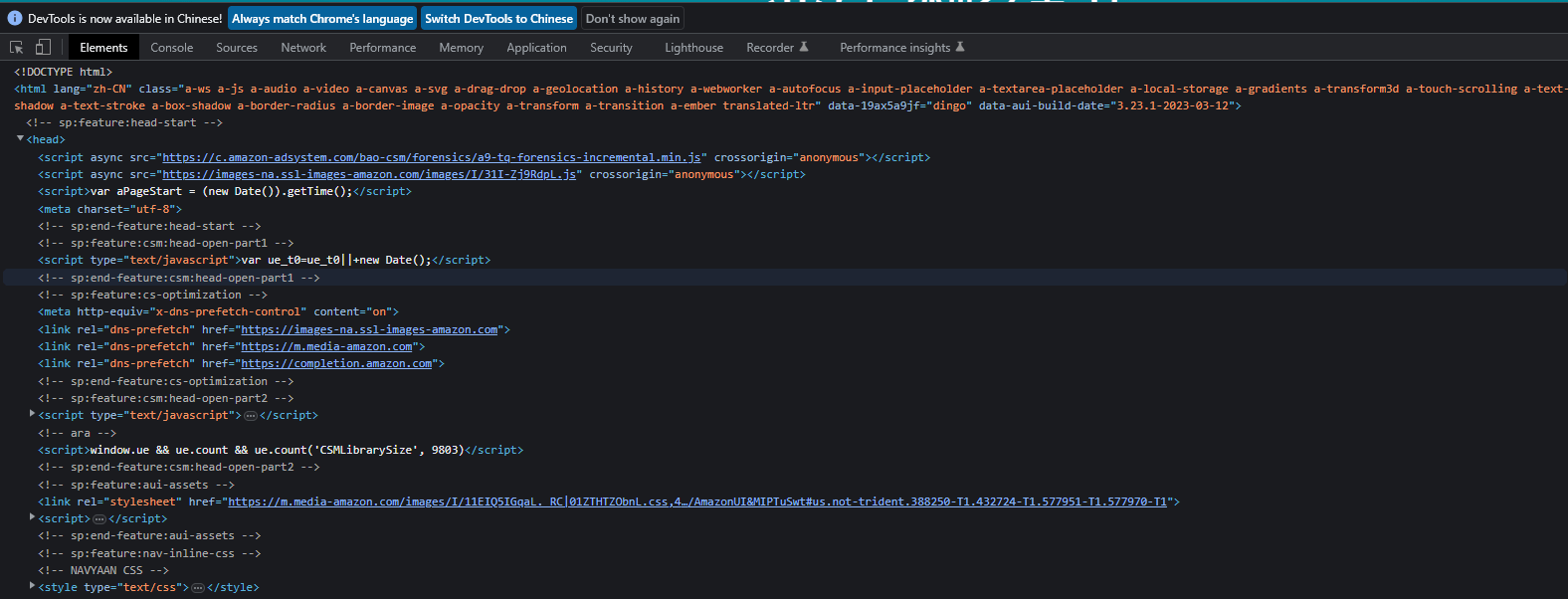
已经尝试的解决方法:
1、把网页里面的headers全部复制进去,运行代码,会报错(报错代码如下)。百度出来说把证书检测关闭,尝试后无效,我也没有其他的解决方法,就没办法继续调试程序了。
C:\Users\Administrator\AppData\Local\Programs\Python\Python39\python.exe C:/Users/Administrator/PycharmProjects/untitled/xuexi.py
Traceback (most recent call last):
File “C:\Users\Administrator\PycharmProjects\untitled\xuexi.py”, line 45, in
response = requests.get(url=url, headers=headers)
File “C:\Users\Administrator\AppData\Local\Programs\Python\Python39\lib\site-packages\requests\api.py”, line 73, in get
return request(“get”, url, params=params, *kwargs)
File “C:\Users\Administrator\AppData\Local\Programs\Python\Python39\lib\site-packages\requests\api.py”, line 59, in request
return session.request(method=method, url=url, *kwargs)
File “C:\Users\Administrator\AppData\Local\Programs\Python\Python39\lib\site-packages\requests\sessions.py”, line 573, in request
prep = self.prepare_request(req)
File “C:\Users\Administrator\AppData\Local\Programs\Python\Python39\lib\site-packages\requests\sessions.py”, line 484, in prepare_request
…………
这个问题一直无法得到解决,希望能有懂的大神帮我找一个问题出在哪里,怎么解决?在此先行感谢。








 关于 LearnKu
关于 LearnKu




推荐文章: