
爬取某小说网站,代码报错,IndexError: list index out of range
import requests
from lxml import etree
# 1、获取要爬的urls
urls = [
'https://www.777zw.net/book/5d/37eefc2f6e/{}.html'.format(i) for i in range(1, 148)]
# print(urls) 正确
# 2、保存小说地址
#
# 3、获取小说内容
def get_text(url):
r = requests.get(url)
r.encoding = 'utf-8'
html = etree.HTML(r.text)
title = html.xpath(
"/html/body/div[4]/div/div/div[1]/a[2]/text()")
text = html.xpath(
"/html/body/div[4]/div/div/div[2]/h1//text()") # 读取第一章内容"
with open(title[0] + ".doc", encoding="utf-8") as f:
for i in text:
f.write(i)
if __name__ == '__main__':
for url in urls:
get_text(url)
运行后,显示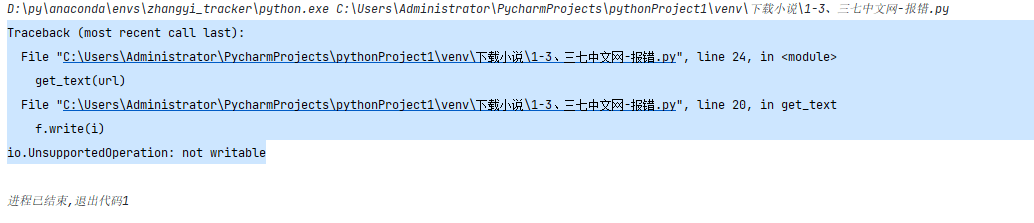





 关于 LearnKu
关于 LearnKu




推荐文章: