
理解非一致性哈希算法的原理
0 / 1 / 创建于 8年前 /
 passenger 的个人博客
passenger 的个人博客
在了解一致性Hash算法之前我们先要了解该算法的使用场景
这里就举一个缓存场景的例子:
假设我们有五台服务器用于缓存图片,编号为1-5.现在需要缓存10W张图片,我们希望这些图片都被均匀缓存到这五台服务器上,来减轻每一台服务器的有压力.现在的问题就是如何给这五台服务器分配这些图片.我这里有三种方法,下面就一一对比.
- 没有任何规律的将图片平均缓存到五台服务器
如果我们这么做了,当我们需要访问某个缓存项时,就要遍历这五台服务器,从10W个缓存项中去找我们需要的缓存项,这样遍历过程效率低,时间也长,如果这样就是失去了做这件事情的意义.缓存本来的目的就是提高速度,改善用户体验,减轻服务器压力. - 使用Hash算法
这时候我们想到了Hash算法来对缓存项的键进行Hash,将hash后的值对服务器数量进行取模,根据取模的结果来决定存到哪一台服务器上.hash(picture_name) % N
比如结果是3,那么这张图片就被缓存到了编号为3的服务器上.
我们要取这张图片的时候直接计算hash值,比如得到的结果是3,就直接去3号服务器上找这这张图片.如果图片在对应的服务器上不存在,那么这张图片就没有被缓存.
使用Hash算法的缺陷:
a)如果这五台服务器已经不能满足需求了,我们需要追加服务器.好了现在我们再加上两台服务器,现在的N从5变成了7.图片还是10W张的话,最后hash后取模的结果是不是都变了.比如开始一张图片缓存在3号服务器上,现在增加服务器后hash后取模的值从3变成了5,现在去5号服务器上找这张图片肯定是找不到的.
b)同理如果缓存服务器中有一台出问题了,我们需要将其从服务器阵列移除,这时N的值同样发生了变化,就会出现和a中同样的问题.
说到底就是N的值变化会导致缓存位置的变化
我们怎么解决这个问题呢?试试一致性Hash算法. - 使用一致性Hash算法
因为N会改变,那么我们可以不对N取模,一致性Hash算法是对2^23次方取模
我们把下图的圆想象成由2^23个点组成
现在我们要做的就是把我们的服务器映射到这个圆环上,hash(服务器ip地址) % 2^32
理想情况下我们的服务器会映射在到环上如下: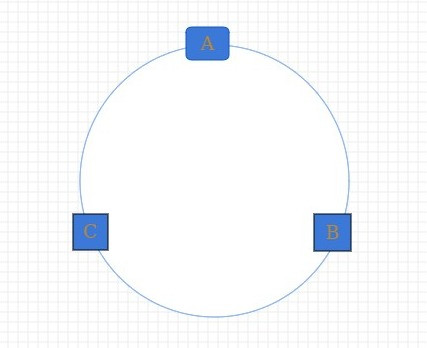
现在我们开始缓存图片hash(图片名称) % 2^32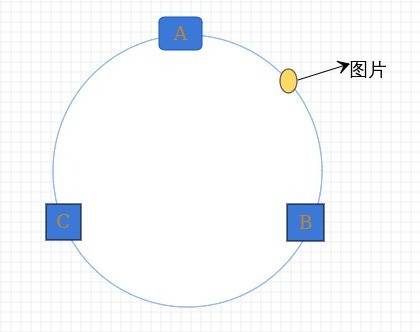
现在图片被映射到hash环上了,那到底存在哪一台服务器上?
当服务器与缓存对象都被映射到hash环上后,缓存对象沿着顺时针遇到第一个服务器就存储在上面.那么这张图片就被缓存到了B上.
现在展示多张图片如何缓存: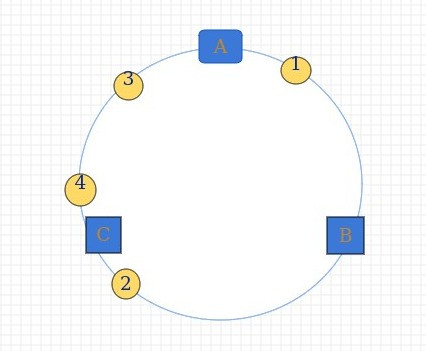
缓存位置:1->B, 2->C, 3->A, 4->A
那么一致性Hash算法与Hash相比优点在哪里呢?
假设现在服务器A出现故障,我们需要将A移除,移除A后的hash环如下: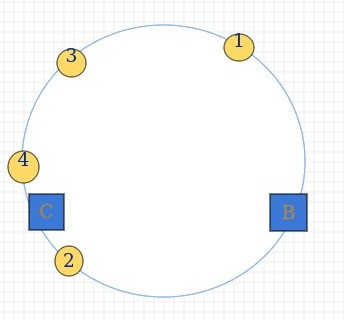
缓存位置变为了:1->B, 2->C, 3->B, 4->B
发生变化的有3和4,由A服务器存到了B服务器上.但是1和2的缓存位置没有发生改变,这就是一致性哈希算法的优点,如果使用之前的hash算法,当服务器数量发生改变的时候,所有服务器的所有缓存在同一时间都失效了,而是用一致性哈希算法的时候,服务器数量如果发生改变,并不是所有缓存都会失效,而只是一部分会失效.这就是一致性Has和算法体现出的优点.
hash环的偏移
开始我们理想化的将服务器均匀的分布在hash环上
但是实际上服务器很可能被映射成如下这样子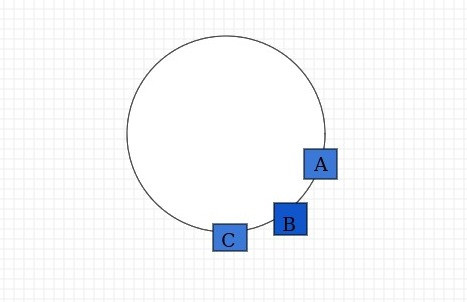
这样会出现什么问题呢?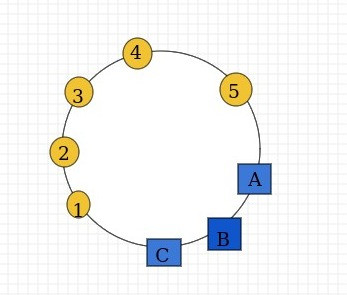
这样1,2,3,4,5待缓存的图片就都存到A服务器上了.如果出现上图中的情况,B,C服务器并没有被合理的充分利用,缓存分布不均匀,而且如果A服务器出现故障,失效的缓存数量也会达到最大.这就是hash环偏移带来的影响.
解决hash环偏移问题--虚拟节点
由于我们只有三台服务器,会很容易出现上述的hash环偏移情况,那么如何解决hash环偏移呢,我们想到让这三台服务器尽可能多的,均匀的分布在hash环上,但是我们只有三台服务器啊,怎么多起来呢?既然我们没有多的物理节点,但是我们可以虚拟出无数个节点.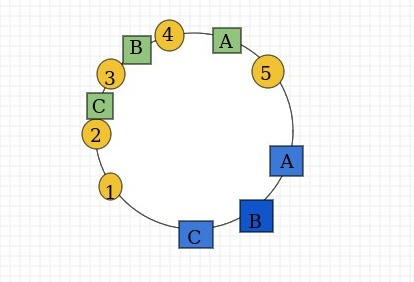
假如绿色的节点是我们虚拟出来的,当然如果你需要,你可以虚拟出更多的替代品.
这时候就不会出现像上面所有的图片都缓存在A服务器上的情况了,现在的缓存结果就是:
4->A, 5->A, 3->B, 1->C, 2->C
如果你还不满意,你可以虚拟出更多的虚拟节点来减小hash环偏移所带来的影响,虚拟的节点越多,缓存被均匀分布的概率就越大.
本作品采用《CC 协议》,转载必须注明作者和本文链接









 关于 LearnKu
关于 LearnKu




推荐文章: